This is my blog.
回归模型
应该算是最基础的吧
梯度下降法,之后也用的比较多
幸好之前也选修了数值分析
对这些东西还算有了解啦!
这里只要有两种,一种是线性回归,另一种是逻辑回归
遇到了一个函数,sigmoid,这个函数还是很神奇哒!
Octave集成的也很棒,Matlab也很棒啦!
打算学完之后,用python巩固一下
好像看到班里的大大们,都是用python研究的么!
Lesson 2 liner regression

shootthe minimum. It may fail to converge, or even diverge.
Attention: In the updating, we should simultaneously update both the parameters $\theta_0$ and $\theta_1 $
The closer is, the slower is.
problem: you may find local minimum, not the global minimum. But in the liner regression, the figure is like a bowl, so the problem will not happened.
“Batch” gradient descent: which says each steps of gradient descent uses all of training examples
Matrix: Dimension of matrix: rows columns (nm)
Vector: an n*1 matrix
Lesson 3 multivariate Liner regression


In octave:
|
|
The ‘pinv’ function will give you a value of θ even if $X^TX)\ is not invertible.[if you use the inv(), then you will get error! ]
And the reasons for the “not invertible” are:
- Redundant features, where two features are very closely related (i.e. they are linearly dependent)
- Too many features (e.g. m ≤ n). In this case, delete some features or use “regularization” (正则化)
But the two ways have both advantages and disadvantages :
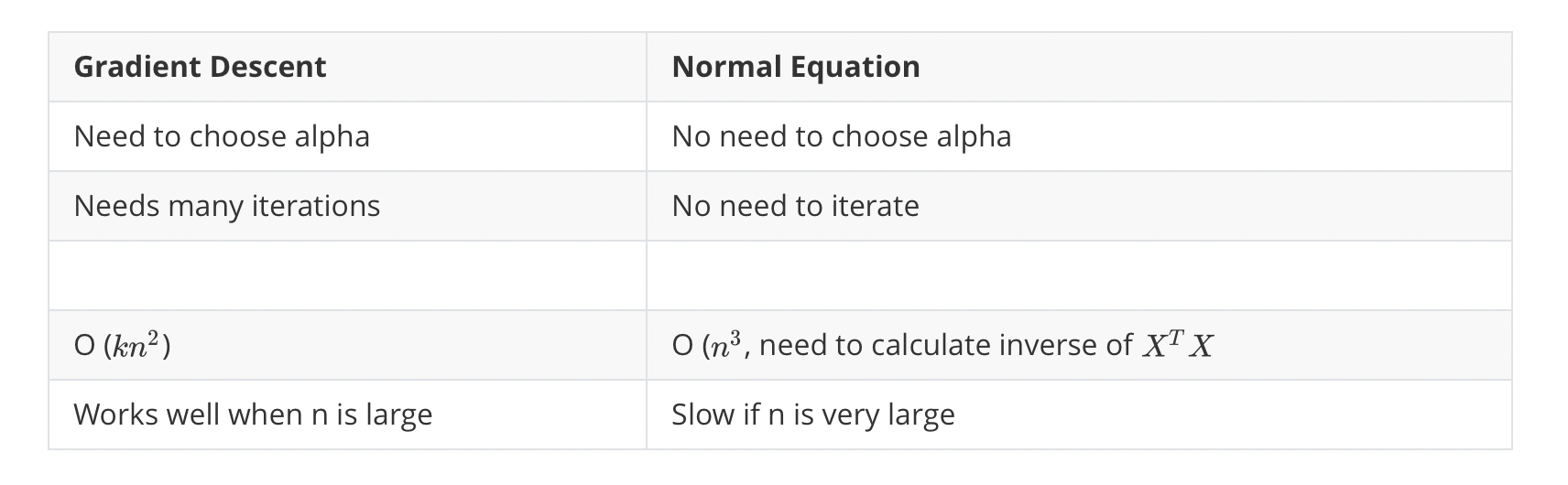
and in other more complicated problems we will find the gradient descent is more useful.
In practice, when n exceeds 10,000 it might be a good time to go from a normal solution to an iterative process.
Lesson 4 Octave
In octave, the index is not from “0”, but from “1”.
Basics :
|
|
Input data:
|
|
Computing:
|
|
Plotting:
|
|
Control:
|
|
if you can use the vector, try to use it to cacluate which will decrease the length of code.
Lesson 5 Classfication

Lesson 6 Logistic Regression Model

|
|
There are other three ways to solve it, and these ways are more faster and you don’t need find the optimal α by manually. But it is more complex. (It isn’t because it will lost in local minimum)
Conjuate gradient
BFGS
L-BFGS
Multiclass Classification

后记
上交完实验后,还是很开心哒!
不过我居然在绿色计算机大赛的时候
犯了小迷糊
可能那一天都在迷糊吧
转载请注明出处,谢谢。
愿 我是你的小太阳
