This is my blog.
Self-Supervised Learning has become an exciting direction in AI community.
- Jitendra Malik: “Supervision is the opium of the AI researcher”
- Alyosha Efros: “The AI revolution will not be supervised”
- Yann LeCun: “self-supervised learning is the cake, supervised learning is the icing on the cake, reinforcement learning is the cherry on the cake”
So, this blog is about the recent improvement (including STA) in self-supervised learning (for researchers).
由于有些论文是先发表的,之后论文有运用之前的某个点或者结构等,因此会有重复。论文笔记顺序不是按照发表顺序,而是阅读时的顺序(阅读是随机顺序……)
更改题目,2020年又有新的成果了,疫情来临,研究者们仍在努力呀!
这篇post记述在2019年中关于self-supervised learning的论文概述。首先从一篇综述开始,总揽当下。
Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey1
这篇概述主要就pretext tasks进行展开,将其分为四大类方法进行描述。并提及了自主学习的其他组成部分。
概述
深度神经网络的性能很大程度上依赖于Network capability(比如其中的特征抽取部分网络:AlexNet, ResNet, etc.)和数据的数量(ImageNet, OpenImage),而大量的数据主要是为了预训练模型,然后再用特定数据去fine-tune。预训练之后的模型主要有两个优点:有好的起点,收敛更快;可以避免over-fitting现象的发生。
但是对于数据的标注是耗时并且代价昂贵的,尤其是在video上。因此提出了self-supervised自主学习方法。首先是从数据的特性中自动 得到pretext tasks的伪标记,然后(通过ConvNet)从大量无标记的数据中学习visual features,然后将学习到的visual features去完成预先定义的pretext tasks,之后将在pretext task训练得到的网络参数(即ConvNet参数)作为监督学习downstream tasks的预训练参数,接下来就是按传统监督方式fine-tune了。
常见DNN结构
主要回顾了一些常见的网络结构,可略过
- Image
- AlexNet:每一个卷积层之后都应用了ReLU;由于只有8层,参数少,易过拟合,因此会带有数据增强、dropout、normalization等方法
- VGG:层数增加,减小stride和kernel size的大小,保留更多细节特征
- GoogLeNet:提出了Inception block,增加了网络的宽度
- ResNet:提出skip connection来解决梯度消失和梯度爆炸的问题
- DenseNet:提出了dense connection,使得浅层关注于浅层通用特征,高层关注于特定任务特征
- Video:包括将视频分成多个帧作为图像的2DConvNet-based,关注于空间和时序特点的3DConvNet-based,动态关注模型的LSTM-based
- Two-Stream Network:由一个空间流模型和一个时间流模型组成
- Spatiotemporal CNN:增加人的动作识别
- Recurrent Neural Network:基于时序特点
Pretext tasks
常见pretext tasks方法主要概括为下述四个部分:重新生成新的数据;基于内容之间的联系;在语义上生成伪标签;基于数据内在的联系。
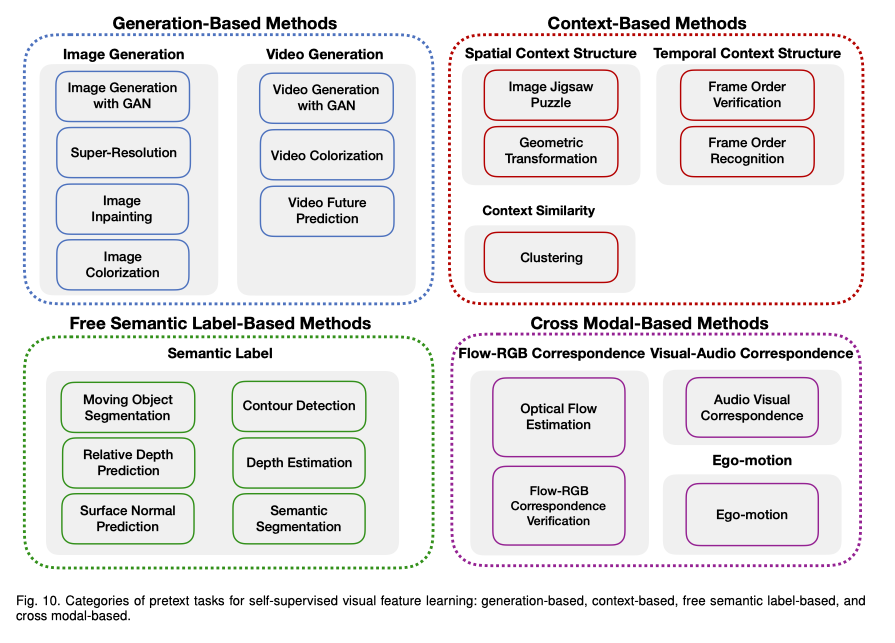
下述从Image和Video分别展开。
Image feature learning
Generation-based Methods:重新生成数据
这一部分的伪标签通常是images本身。
Image generation with GANs:生成假images
就是普通的GANs,生成器学习真实图片的分布,然后生成尽可能像真的伪images;判别器则区分images的真伪;two-players / min-max game;之后将判别器网络用在downstream tasks的初始化上即可。
Image super resolution:生成更高分辨率的images
- 自动编码器:通过压缩images,用低维度来表示原图
- GAN:仍然可以通过GAN的方法来生成高分辨率的images,生成器使用perceptual loss,包括pixel-loss和content loss两个部分,判别器使用二值损失,如MSE。
Image inpainting:将images缺失部分补全
用剩余完整images信息特征(颜色、结构等等)来补全images;可以直接用卷积网络,也可以用GAN生成更真实的图片,生成网络的全连接层又包括编码器(补全信息)和解码器(预测补全后缺失区域的位置)。
Image colorization:将灰度images填色
这里的填色不需要和原彩色相同,只需要合理即可。因此首先需要辨认出目标,找到同一部分的pixel归为一类。一个直接的方法就是全连接网络,包含编码器(特征提取)和解码器(变色color hallucination to colorization),用L2 loss评估预测和真实的值。对于多种可能性,使用类别平衡来解决不确定性的问题。
Context-based pretext tasks:通过内容特征
Context similarity:patches之间特征的相似性
Image clustering-based methods
根据数据的分布来group(可以使用KMeans);一种naive的方法就是手工标记特征,如HOG、SIFT、Fisher vector;group之后同一组的距离较小,不同组的距离较大;是当前表示学习的STA。
Graph constraint-based
Spatial context structure:patches之间空间的联系
比如任意两个patches之间的相对位置;比如一连串patches之间的顺序;当然这个联系的问题不可以过难或者过于简单。
- Image jigsaw puzzle:常见的9宫格拼图,实际上已经有9!种可能性了,patches之间可以增加空隙,避免因为一些连接特性而易找到位置关系。
- Context prediction
- Geometric transformation recognition
Free semantic label-based methods:自动生成语义标签
Free semantic label包括segmentation masks,深度图,光学流和surface normal images;
主要通过硬编码和game engine,game engine可以在低cost且拥有pixel-level label下生成大量真实的合成数据,但是合成数据和真实数据不太一样,不可以直接训练,因此需要自主学习的辅助;hard-code programs是另一种生成合成数据的方法,但是其生成的label比较noisy。
方法包括:
- Moving object segmentation
- Relative depth prediction
- Surface normal prediction
- Contour detection
- Depth estimation
- Semantic segmentation
Video feature learning
Generation-based Methods:重新生成数据
Video generation with GANs
同样用GAN做对抗,这里的网络有两个流,分别是前景和背景,然后训练完之后将判别器的参数传递到downstream tasks上。
Video colorization
这里就是将帧分开,每一个帧同样由灰色进行上色即可。很少有工作运用这个方法。
Video future prediction
对于一个有限帧的video,用编码器寻找空间和时间上的特征,用解码器生成预测的未来帧。但是目前还没有研究探究这种方法的泛化能力。
Context-based pretext tasks:通过内容特征
Temporal context structure
根据时序的顺序主要有两个方向:
- Frame order verification
- Frame order recognition
都需要捕获帧之间细微的不同之处,因此在准备时需要对大量数据进行处理,比较耗时。
Cross modal-based methods:对于输入的两个不同的通道判断是否之间存在联系
这里的通道包括:RGB顺序、光学流顺序、语音数据、相机姿势等。
Flow-RGB correspondence verification
Optical flow estimation
上面两者可以认为一类,都是从图像特征上来说的。
Audio visual correspondence
关注于visual stream和audio stream之间的关系。
Ego-motion
无人驾驶汽车可以很容易收集到以自我为中心的行为数据。
通过两个帧之间的关系,得出自己的旋转与平移的行为方式。
Downstream tasks
包含
这一部分就是传统监督学习所完成的任务(可略过)
包括:
- Semantic Segmentation:给每一像素都赋予语义标签;
- FCN全联接网络初始化为训练pretext tasks完成后的网络参数
- 用语义分割数据fine-tune
- 在语义分割任务上评估
- Object Detection:定位和分类目标
- Fast-RCNN等检测网络初始化为训练pretext tasks完成后的网络参数
- 用目标检测数据fine-tune
- 在目标检测任务上评估特征的泛化能力
- Image classification:分类目标
- 特征提取网络初始化为训练pretext tasks完成后的网络参数
- 用分类数据训练分类器如SVM
- 在分类任务测试上评估特征质量
- Action Recognition:(在预定义动作列表中)判断人的动作
- Video特征提取网络初始化为训练pretext tasks完成后的网络参数
- 用动作识别数据fine-tune
- 在动作识别任务上评估特征质量
质量评估
对于质量评估方法主要包括:
Kernel visualization
将卷积第一层的kernel可视化,与监督学习的进行比较,越相似越好
Feature map visualization
将特征图可视化,越大的激活代表越关注这个部分,与监督学习比较
Image retrieval visualization
在特征空间中寻找K近邻
数据集
所有监督学习上的数据都可以在去除标记后作为self-supervised learning的数据集使用,文中列出了Image和Video常用的数据集及其信息,可略过。
评估方法
通过在downstream tasks上的表现来评估,但是这种方法不能洞察到在自主学习训练下的情况。因此需要更多的评估方法,比如network dissection。
当前质量表现
- Image feature learning
- 没有在ImageNet预训练上表现的好,但是可以比拟(相差1%~2%左右)
- 每一层的特征都是有用的
- 深层次的特征表现比较好,浅层次的特征表现不太好
- 当数据集之间有gap时,可以和ImageNet预训练的相提并论
- Video feature learning
- 明显低于监督学习下的,亟待改进(相差30%左右)
- 可能和参数多、特征复杂有关系
未来研究方向
- Learning Features from Synthetic Data
- Learning Features from Web Data
- Learning Spatiotemporal Features from Videos
- Learning with Data from Different Sensors
- Learning with Multiple Pretext Tasks
Learning Correspondence from the Cycle-consistency of Time2
这篇文章主要是用周期一致性cycle-consistency的思想,适用于不同规模的语义相关程度上。在训练时,通过周期一致性,向前向后tracking,将起点和终点的不一致部分通过损失函数,来学习特征图的特征表示;在测试时,通过学习到的特征表示来寻找空间和时间上的最近邻。
概念上比较简单,但是需要考虑:
- 当序列帧中目标并没有移动/变化时,需要更换目标,否则学习不到
- 当物体姿态或者遮挡物发生变化时,可以通过跳过一些帧skip cycles来实现周期一致性
- 当由于较短的周期使学习简化时,可以通过更换周期或者使用多种周期Multiple cycles
方法具体来说如下:
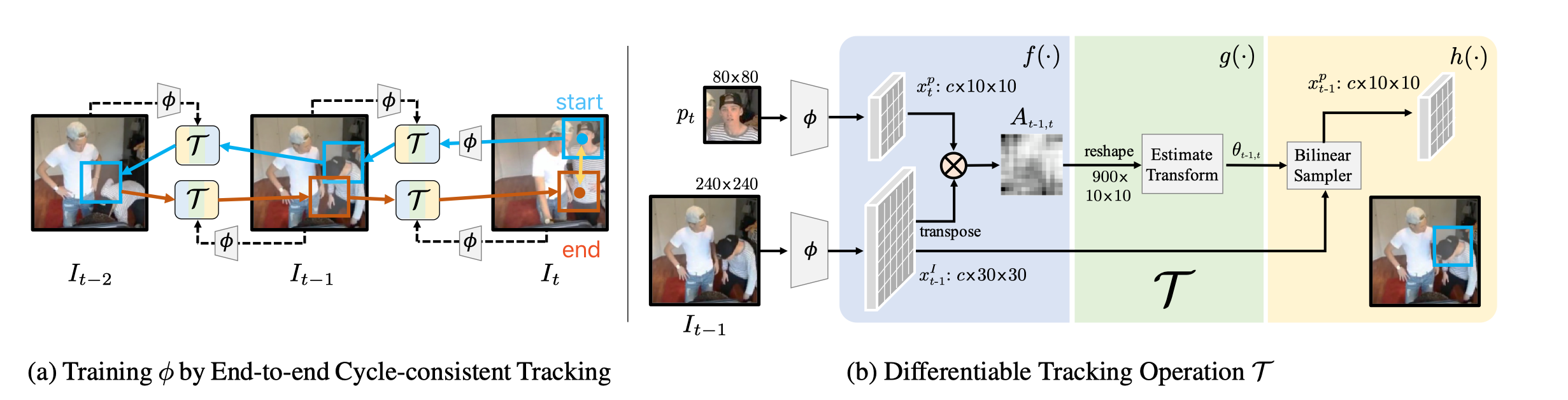
训练时,tracker 和encoder两者相伴,不断学习
首先从start开始(这时时间为t),我们有一个初始patch ,将其通过卷积网络来提取特征,得到;
接下来backward tracking,这一步我们需要通过tacker 来获得下一时刻patch在t-1和t-2时的位置,即图b所完成的工作
t-1(t-2)时刻的图片()首先通过卷积网络来提取特征,得到()(在tracking中不断完善,因此在初期训练中,结果并不太优秀)
Affinity function f,将下一个时刻t(t-1)时的patch提取的特征()与此时刻的特征()进行运算,衡量对于patch特征图的第i个格子和图像特征图的第j个格子的相似性。
定义,。具体的运算公式如下:
Localizer g,通过相似矩阵A来寻找到与patch特征图最匹配下的局部参数(包括三个部分:2个维度表示空间坐标,1个维度表示旋转角度)。
定义,。g是由两个卷积层,一个线性层组成的。
Bilinear Sampler h,则是用在Image特征图上变线性采样,得到与patch特征图最匹配的小patch。
定义,。
通过Tracking得到与()在t-1(t-2)时刻的具有最大相似性的区域()
接下来forward tracking,和backward tracking步骤相似,通过tacker 来获得上一时刻patch在t-1和t时的位置
将end获得的patch与start的patch进行比较,得到特征相似衡量部分的损失函数(这里用两个空间的欧几里得距离来作为损失量)。
继续多组循环的计算,之后加上tracking和skip cycles部分的loss,共同组成损失函数部分,通过不断训练使得损失函数最小化
测试时,用已经学习完成的encoder,找到两个帧的特征相关性的矩阵A,然后将矩阵A和各个patch的标签来计算新帧各个部分的标签。
用数学公式来表示,即:
训练部分:
提取特征
tracker找寻最相似patch
Backward:
Forward:
计算loss
对于loss部分,细化优化之后,包括tracking、skip cycle、特征相似性三个部分:
Tracking:
Skip Cycle:
其中,上两者中的的定义为:
其中,M表示n个坐标系下的变线性采样结果。
Feature Similarity:
因此Loss定义为如下(k是cycles的数目):
测试部分:
- 计算两个帧的相似矩阵
- 计算新帧各个部分的标签
作者的实验参数:
- Videos
- 114K,344hours
- Hardware
- 4-GPU machine with a mini-batch size of 32 clips(8 clips per GPU), for 30 epochs.
- Input frames
- 240 × 240 pixels
- randomly cropped rescaled to
- Image patches
- 80 × 80 pixels
- Encoder
- ResNet-50 without res5 (the final 3 residual blocks), optimizer Adam with a learning rate of 0.0002 and momentum term .
- Input image的特征图大小 30 × 30
- Image patches的特征图大小10 × 10
遗留问题:
- 训练到30 epochs就停滞不前
- 对于更大规模和有噪声数据的训练并不友好
- 需要提高对遮挡物和部分物体的识别能力
- 对于在训练中跟踪目标的选择问题
- 可以引入更多的上下文进行跟踪
结果:
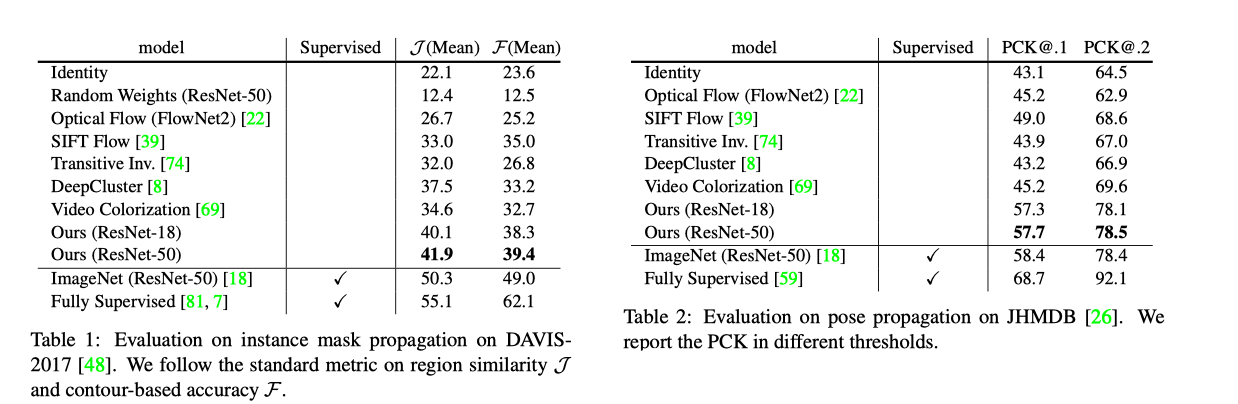
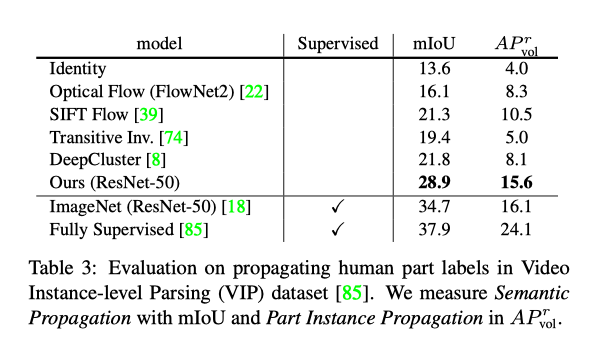
Momentum Contrast for Unsupervised Visual Representation Learning3
这篇文章是利用查询字典来完成contrastive learning对比学习(通过正反例子来学习表征),即寻找一个关键字与查询点相近,但与其他不相似。为了满足规模大和前后一致的特点,基本思路就是建立一个动态字典(从某种意义上来说是一种随机采样)。这个字典由队列来表示(实现规模大的特点),根据动量(保持一致性)来更新编码器。所要查询的和当前字典的选择,通过编码器得到各自的特征表示,之后使用contrastive loss对比损失来衡量两者的相似性,这样不断来训练视觉表示编码器。
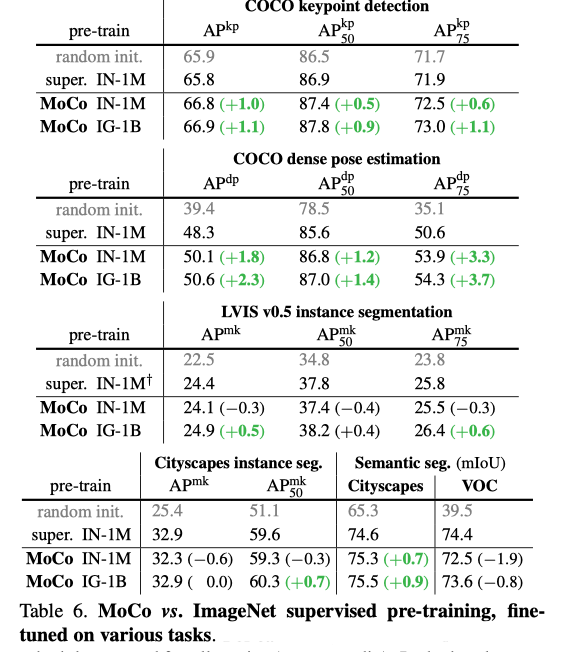
方法名简称为MoCo。在PASCAL VOC,COCO和其他数据集的7个检测/细分任务中,可以胜过监督预训练的方法,有时甚至可以大大超过它。
当负样本数量较多时,对比方法能够更好的发挥作用。因为更多的负样本能够有效的覆盖潜在数据分布。在对比学习中,负样本受限于mini-batch的大小,之前的方法是用memory bank机制(空间开销O(N))。而MoCo通过动态队列(Momentum Update、 shuffleBN 等技术)来解决这个问题。
方法如下:
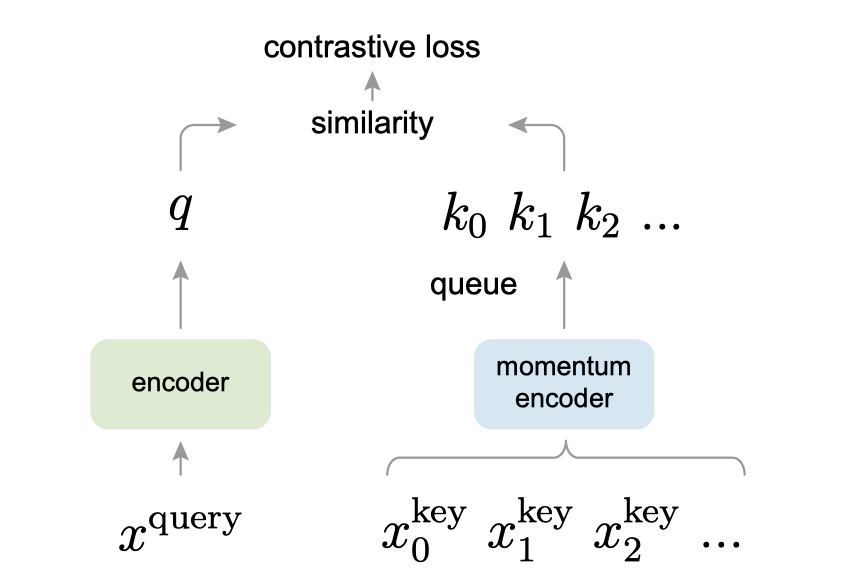
有一组候选样本,其可以是一张图片,也可以是一个小patch;
从中随机选出一个查询;
经过encoder ,,得到所需查询的特征;
经过momentum encoder ,(这里两个编码器可以独立,也可以部分参数共享,也可以相同),得到一个动态队列,队列的大小可以大于mini-batch的大小,两者是解耦的;
从队列中随机取出元素
对比的目标是学习一个,使得:
这里指的是与x相似的数据(正样本), 指的是与x不相似的数据(负样本)。score 函数是一个度量函数,评价两个特征间的相似性。
这里使用InfoNCE损失方法(可以减少外部噪声的干扰)来衡量
其中,为一个超参数。
当然这里的对比损失还可以用别的表示方法,如margin-based losses,variants of NCE losses。
根据loss,计算梯度,以此来优化encoder,使得视觉表示编码器更加优秀;
同时根据动量来更新(动量更新是为了解决反向更新后,前后编码器不一致的问题),删除最老的数据,因为它的编码密钥是最过时的,因此与最新密钥的一致性最小。
定义的参数为,则的更新如下:
其中,是动量系数,实验表明m值大些,结果更好,也表明了慢些更新编码器效果更好,作者使用的是0.999。因此,在实验中,后向传播只更新,然后通过动量更新,这样更加改变的比较平滑,尽可能保持前后编码一致性。
将新编码器规则得到的加入队列,更新队列;
伪代码如下:

在早先的比较学习中,与使用的是同一个网络,这篇文章的创新点就是,将两者分开,并且两者的参数更新方式是不同的。
超参数如下:
- Encoder
- ResNet with Batch Normalization
- Fixed-dimensional output (128-D)
- Output normalized by L2-norm
- SGD weight decay is 0.0001 and the SGD momentum is 0.9
- Initial learning rate of 0.03
- Contrastive loss
- The temperature τ is 0.07
- Input data
- 224×224-pixel
- random color jittering, random horizontal flip, and random grayscale conversion
- Mini-batch size 256
结果:
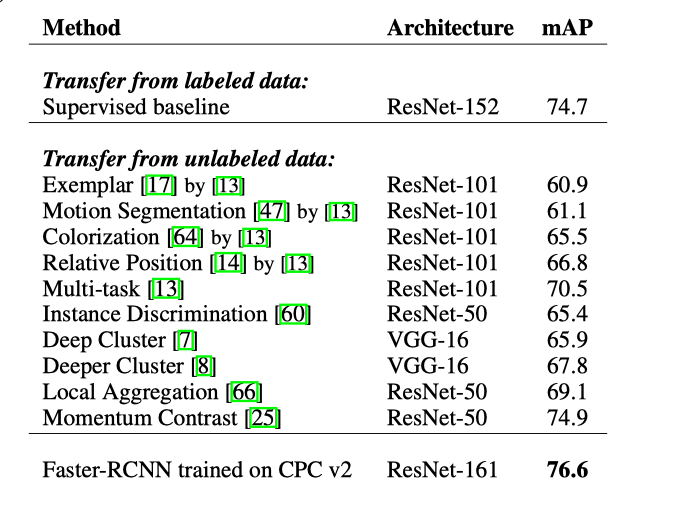
Data-Efficient Image Recognition With Contrastive Predictive Coding4
这一篇文章同样也是用contrastive learning对比学习的思想,其在未标记的ImageNet数据上并使用数据增强的方法进行对比训练,然后使用分类器进行无监督对比学习,效果超过了监督的AlexNet。
Oord et al., 2018的CPC是其基础版本,通过对多个时间点共享的信息进行编码来学习特征表达,同时丢弃局部信息(“慢特征”:随时间不会快速变化的特征)。而此篇是在其基础上加上label-propagation操作,来提高data-efficient recognition数据有效识别。
(对比学习结构都是由三个主要构件组成的)
因此后续的解析会围绕这前后两篇著作展开。
CPC V2的提升部分,具体包括:
- MC: model capacity. 模型容量
- Original: ResNet-101, 23 blocks, 1024-dimensional feature maps, and 256-dimensional bottleneck layers.
- Now: ResNet-161, use 46 blocks with 4096-dimensional feature maps and 512-dimensional bottleneck layers.
- Top-1提升了22.8%, Top-5提升了16.5%
- BU: bottom-up spatial predictions. 之前只根据patch预测,现在不仅根据patch还有patch周围元素一起来预测
- LN: layer normalization. 由于网络结构大了,训练更加难了;因此从batch normalization变更为layer normalization
- HP: horizontal spatial predictions. 实验说明,空间维度越多,效果越好
- RC: random color-dropping. 下述和这个都是用来增强数据
- LP: larger patches.
- PA: further patch-based augmentation.
方法如下:
(左边为空间示意图;右边为流程图)
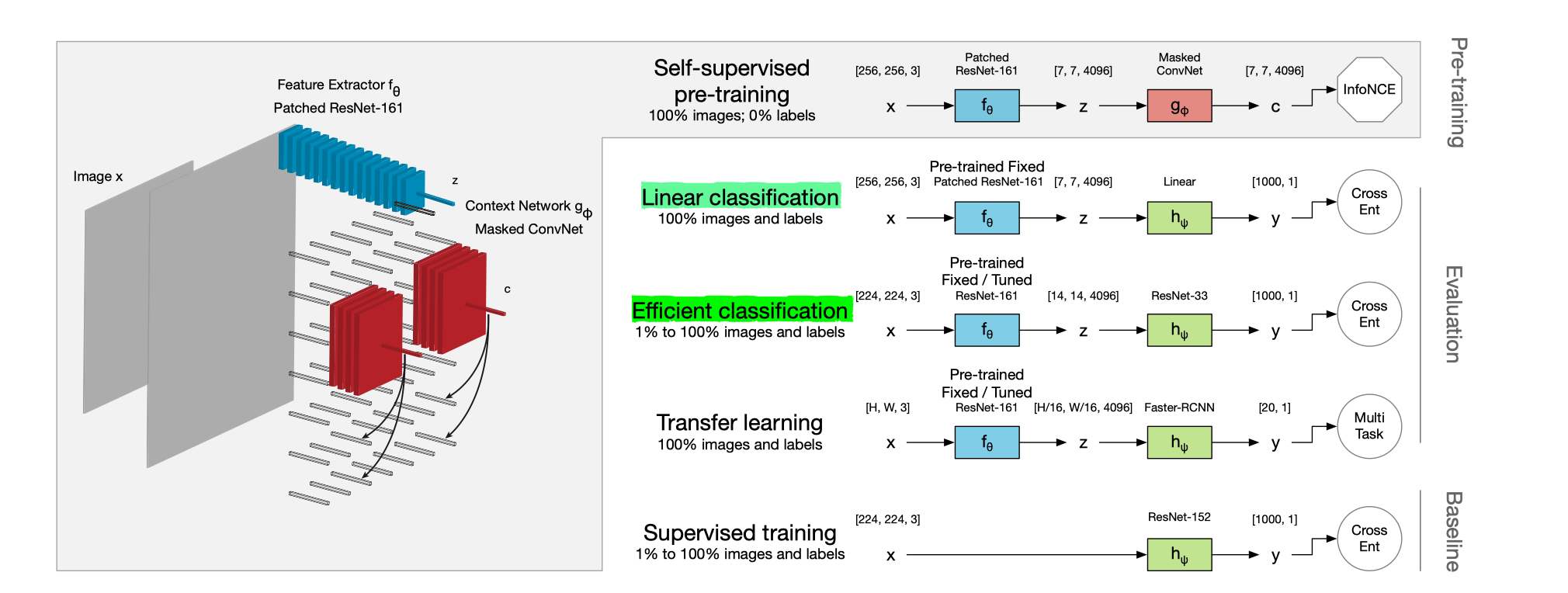
在图像上的示意图(来自基础版本),实际上就是上文中的。
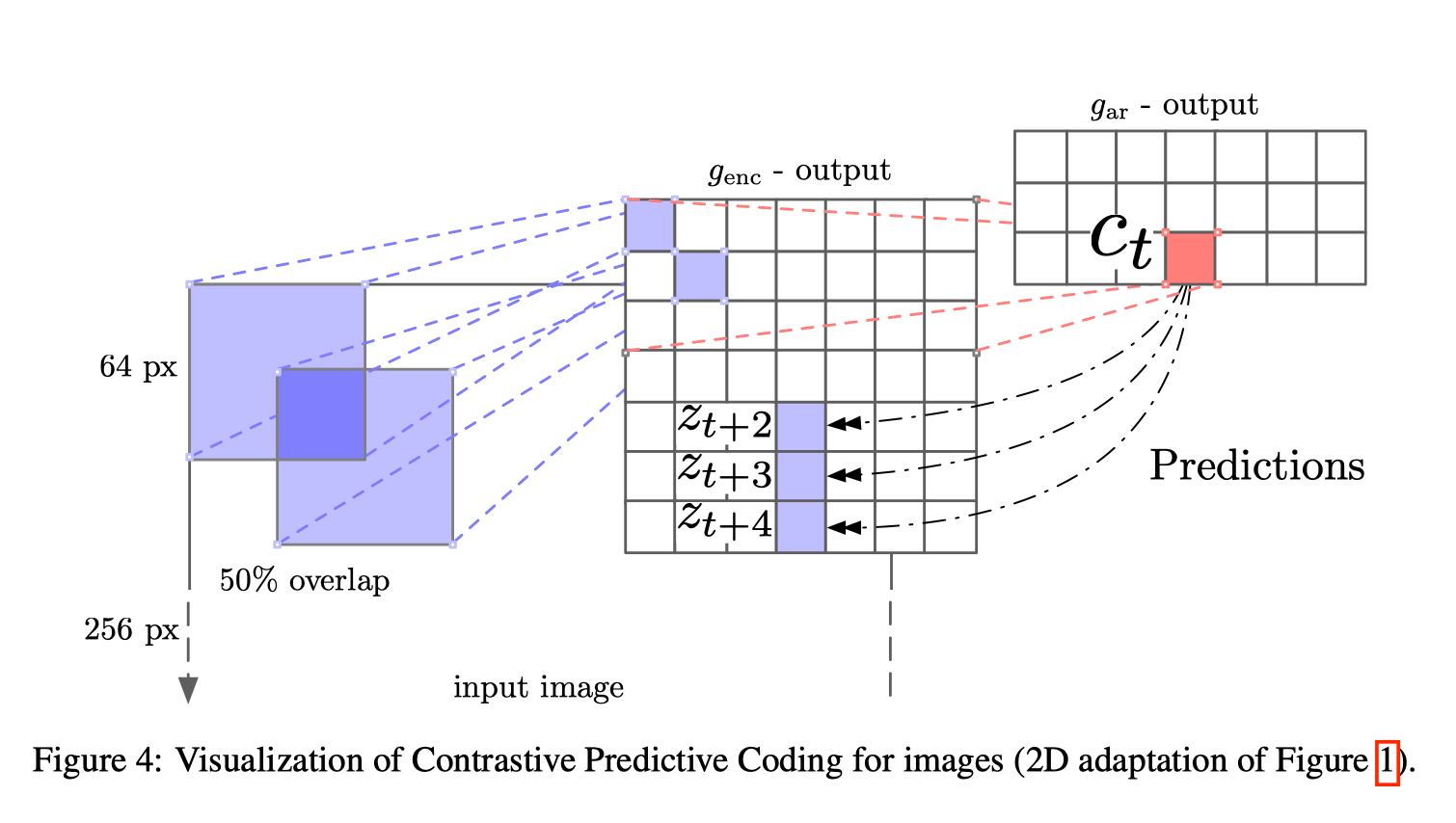
预训练:
将图片x divide分成若干小patches(块之间部分重叠,见Figure 4);
通过特征提取器(最后是平均池化的卷积网络,这里是ResNet-161)来进行表征学习Representation learning,得到特征向量;
将所有特征向量通过masked CNN ,aggregated连接起来,产生一行context向量;
将context向量用InfoNCE衡量
测试:
根据预训练的结果设定特征提取器;
通过label-propagation增强数据的有效性,将训练分类表征用小部分标记数据训练;
将图片x divide分成若干小patches;
将其通过特征提取器,得到特征向量;
将特征向量通过分类表征,得到标签向量;
将标签向量与真实标签用交叉熵损失来衡量
在Video上,时间序上的回归示意图:
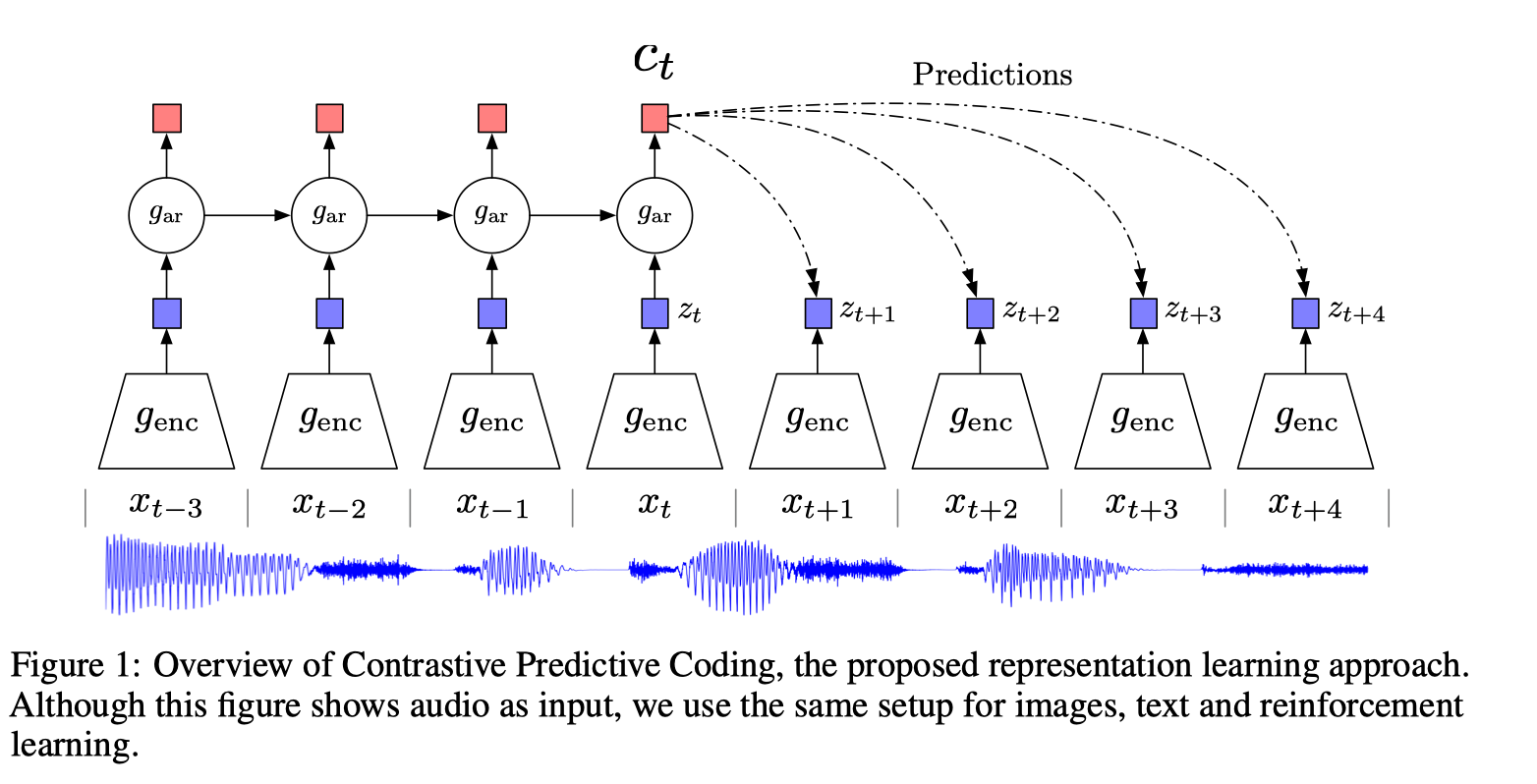
伪代码:

参数:
- Input
- extracted 80×80 patches with a stride of 32×32 from a 240×240 shaped input image
- :
- a grid of 6×6 features
- :
- an 11-block ResNet architecture with 4096-dimensional feature maps and 1024-dimensional bottleneck layers
- labeled images
- subset of the ImageNet dataset
- only 1% of dataset
- supervised loss
- cross-entropy
- Optimizer
- Adam Optimizer with a learning rate of 5e-4.
- a batch size of 512 images
结果:
下面两篇则是利用对比方法学习不变特征(Invariances)
2019年Bachman提出的 Augmented Multiscale DIM ,通过数据增强方法学习不变特征。Augmented Multiscale Deep InfoMax (AMDIM) 和CPC很相似,都是通过空间来预测的,但是这篇在预测表征上还通过层之间的关系。DIM 的具体思想是对于隐层的表达,我们可以拥有全局的特征(编码器最终的输出)和局部特征(编码器中间层的特征),模型需要分类全局特征和局部特征是否来自同一图像。所以这里 x 是来自一幅图像的全局特征,正样本是该图像的局部特征,而负样本是其他图像的局部特征。
2019年 Tian提出的 Contrastive multiview coding,通过图像不同的通道学习不变特征(深度、光照、语义标签等)【后文有介绍,代码部分开源,有些东西,复现的有问题( ・᷄ὢ・᷅ )】。
Revisiting Self-Supervised Visual Representation Learning5
这篇文章主要是研究了多种网络结构以及多种self-supervised的任务,得到了一些启发性的经验结论:
- 监督学习的结果不可以直接用在自主学习上,两者是不同的
- 自主学习在不同task上的结果依赖于网络结构的选择,比如对于rotation,RevNet50性能最好,但是对于Exemplar、相对Patch位置、Jigsaw等其他方法,ResNet50 v1性能最好(而监督学习中,AlexNet的结果会明显更优)。
- 对于skip-connection(resnet)结构的网络,高层的特征性能并不会下降。
- 增加filter数目和特征大小,对于性能提升帮助很大。
- 无监督性能最后训练的线性分类器非常依赖学习率,需要多次迭代才可收敛(作者尝试了多层感知机,但效果不好,所以并没有给出解决方法)。
实验链接,是Tensorflow版本,代码很清晰。
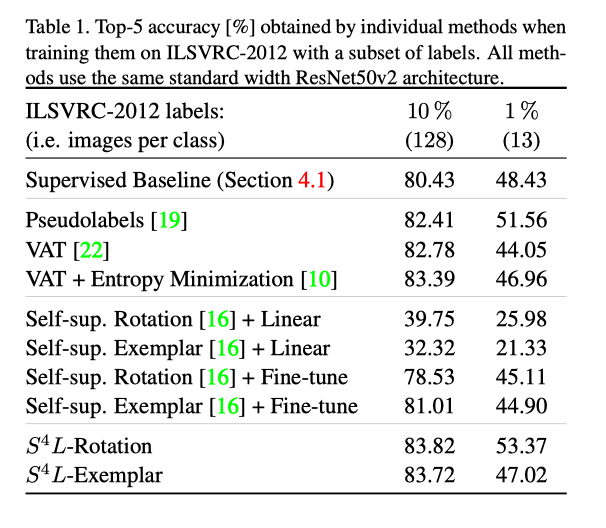
: Self-Supervised Semi-Supervised Learning6
这篇文章主要是提出了 learning的方法(是指self-supervised semi-supervised learning),将无监督学习与半监督学习结合了起来:通过在标记数据上面计算分类损失,无标记数据上计算self-supervised的损失,即
其中,是标准交叉熵损失函数,是非负权重值(实验中得出取值为1,效果最好),是中的参数。
具体流程(和平常一样):
- 由标准的标记数据先训练pretext任务的模型
- 用无标记数据测试得到预测标记(可以将标记数据去除标记,一同加入训练)
- 再用预测标记作为伪标签再次训练模型
- 之后用标记数据fine-tune模型
自主学习部分损失:
作者在两个pretext tasks上实验,两个损失函数都和各自的任务相关,并没有改变,可忽略。
一个是 -Rotation,即无监督损失旋转 预测任务(比Self-sup. Rotation + Fine-tune在10% labels上提高5.29%,在1% labels上提高8.21%);
其中,表示图片经过r翻转后的新图像,表示交叉熵损失函数。
另一个是-Exemplar,即无监督损失基于图像变换(裁切、镜像、颜色变换等)的triplet损失,即衡量相同图像有相似特征表示,不同图像有不同特征表示。(比Self-sup. Exemplar + Fine-tune在10% labels上提高2.71%,在1% labels上提高2.12%)。
半监督学习部分损失:
Virtual Adversarial Training (VAT)
主要是增强对于预测的鲁棒性
因此损失函数的形式,即在范围内的预测应该相同
Conditional Entropy Minimization (EntMin)
增强对于预测的信心
主要通过标签对于图像的条件概率来衡量
实验中,有对小的验证集是否有效这个问题进行实验,发现在小型验证集上调整的最佳模型也是在大型验证集上调整的最佳模型,因此得出结论,用小的验证集fine-tune即可。
结果:
Self-Supervised Representation Learning by Rotation Feature Decoupling7
这篇文章主要是提出将旋转不变性纳入特征学习之中,并且将图像旋转pretext task和实例区分任务接耦,来提高预测的准确性。
旋转面临的问题:
- 不是所有特征在旋转之后,都是不变的;即旋转不变性是有特例的
- 旋转之后不是所有实例都可以预测的
- 圆形物体
- 对称物体
- 从顶部观察的物体
因此,所学习的实例特征可以分成旋转判别和旋转不相关两个元素。这也是和RotNet(只进行旋转学习)方法的不同之处。
在分类任务上,比RotNet高1.3%,比监督学习低6.6%;在检测任务上,比RotNet高3.1%,比监督学习低5.6%;在语义分割任务上,比RotNet高6.2%,比监督学习低2.7%。
具体做法如下:
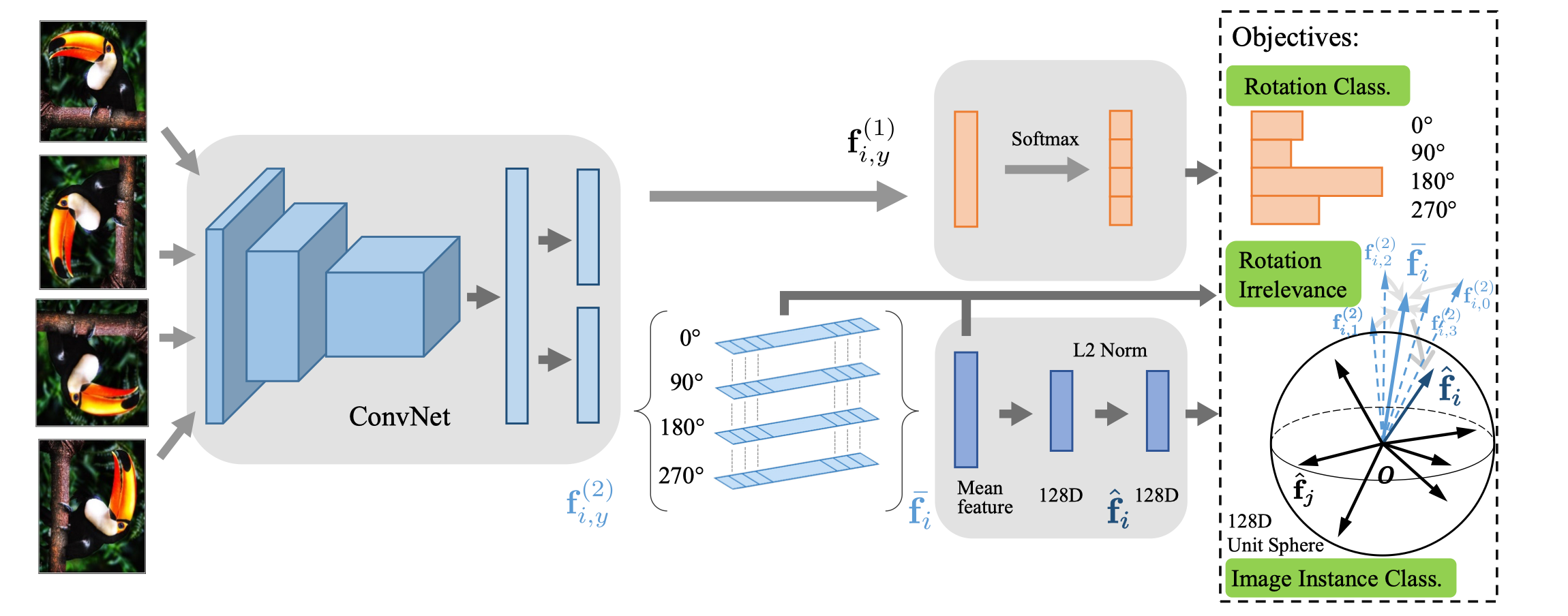
将原始图像作为正样例;
将原始图像经过旋转变换(4个角度,)得到新的生成图像,所有新生成的图像都没有(分类)标记,但有旋转标记;
用卷积网络来提取特征,按照生成的图像和原始图像是否相同,分成两个特征元素,,更加关注于主要目标(实例)在图像中的位置以及它初始的方向,而更加关注于这个图像和其他图像的不同;两者的维度是相同的;
如果原始图像和新生成的图像不同,则作为正样例;
将这部分数据训练pretext task,预测旋转的角度;
对于其中样本的旋转标记存在噪声(旋转后图像有歧义),通过PU (positive unlabeled) learning,来学习标记样本的权重;
其中,是对旋转后的图像的正负性的概率估计(正的表示,样本可用;负的表示,样本不具有训练的条件)。
对于旋转角度分类的损失,定义为(注意这里是对部分特征)
如果原始图像和新生成的图像相同,则作为负样例;
用所有旋转前后图像的特征差异来作为惩罚;
完成实例区分任务,进行无参数分类;
对于图像预测为实例的可能性定义为:
其中,是的L2-normalized 版本,是一个温度参数。
这里目标为:
由于上式计算会耗费大量空间和时间(因为包含了e的次方计算),因此在归一化之前将均值特征(超过128维,一个降维处理)线性映射到一个128维矢量,再归一化为,并采用噪声对比估计NCE(将真实的样本和一批“噪声样本”进行对比,从中发现真实样本的规律;具体来说就是将它转化为二分类问题,将真实样本判为1,从另一个分布采样的样本判为0)和近端(梯度)正则化(把一个优化问题转化为其中的一部分,然后用梯度下降法优化这一部分,从而实现总优化问题;大概就是公式中的部分)。 目的是最小化以下损失函数:
其中,表示真实的数据分布,表示NCE中噪声的均匀分布,表示其他图像归一化后的特征值。
因此最终目标定义为:
实验参数:
- 特征提取器
- AlexNet: five convolutional layers and two FC layers
- leave out the Local Response Normalization (LRN) layers
- add BN after each linear layers
- 旋转分类器
- one-layer linear network
- 损失函数
- 训练
- 200 epochs;
- The learning rate is set to 0.01 initially and then decayed by a factor of 10 every 40 epochs after the first 90 epochs.;
- momentum is 0.9;
- batch size is 192;
- penalization of the weights with .
结果:
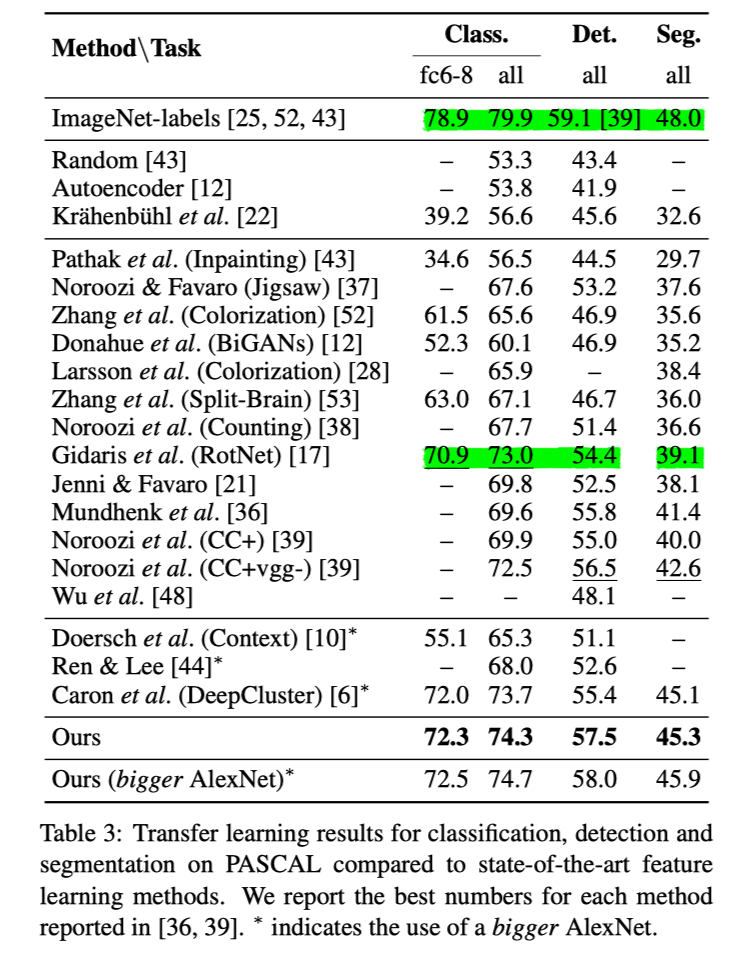
Large Scale Adversarial Representation Learning8
这篇文章,出发点是GAN在监督学习、迁移学习等上效果都很好,但还没有在表示学习上运用过。于是说,将GAN的生成图像的质量高的特点转换为提高表示学习的性能上。因此在GAN的当前最优秀之一的BigGAN模型作为基础,添加编码器和修改鉴别器,将其扩展到表示学习——BigBiGAN(=BigGAN+Bidirectional=BigGAN+ALI [Adversarial Learned Inference])。
相对于CPC(上文提到的一些对比学习来说),它不需要更改输入数据,是全分辨率进入算法的;因此在downstream tasks时,可以直接使用,而不需要域迁移。
但是正是由于它的big,因此复现上对于硬件要求高。
在说明BigBiGAN之前,先来说明它的两个基础模型:BiGAN和GigGAN。
BiGAN
BiGAN是一个双向GAN,这里的双向指的就是输入数据(一般是图像)和随机潜变量(简单来说就是一下载从数据中看不出的内容,我是把它当作特征来看的)两者之间的编码和解码过程。网络结构也很简单清晰(如下图),就是和之间的双向生成,加上生成的通过判别器判断。
考虑随机潜变量,有两个原因:
- 由于 BiGAN的生成器是基于 DCGAN 的,所以生成的图片质量并不高。这也就导致了 G 的输出和输入x的分辨率不同,图片x分辨率会高很多,对 BiGAN 的特征提取效果产生了限制。因此在GAN基础上加入了一个将数据映射到隐特征空间的E;
- 通过学习潜变量,来学习数据的内在/表征;是表征学习的关键。
同时对D做了相应的改进。D的输入变成了两个数据对和。最终模型希望 。
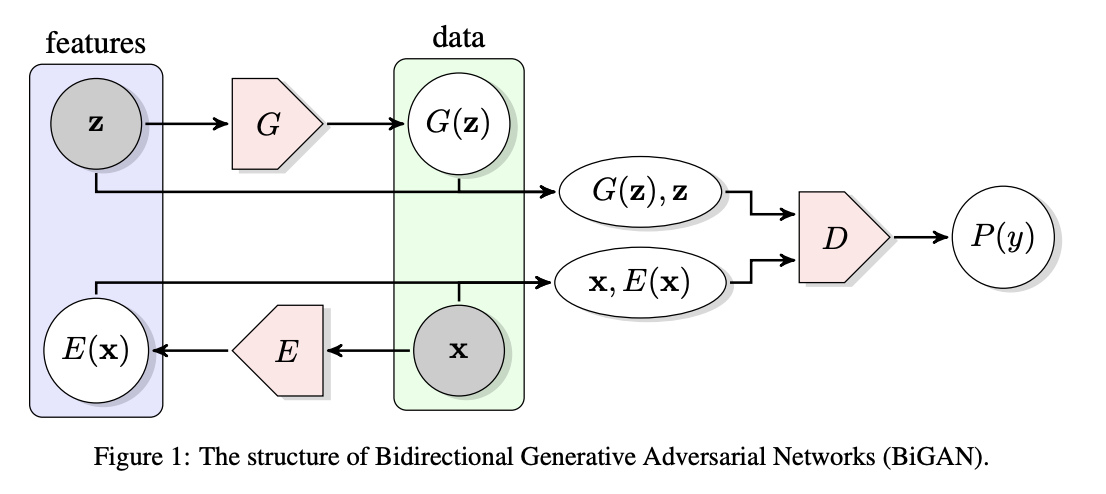
目标为:
其中期望值由蒙特卡洛样本估计来得到。
BigGAN
BigGAN,是在BiGAN上进行改进。它改进的一个点就是Big,包括模型的参数、Batch等,都大大增加了;同时将正交正则化的思想引入 GAN,通过对输入先验分布z适时截断(设置阈值的方式来截断 z 的采样)来控制样本的多样性和保真性,又增加了对模型稳定性的控制,在其中寻找到了一个平衡点阈值,大大提升了 GAN 的生成性能。现在就是要用其生成图像质量高的特点,将其作为生成器的一个部分(而且在消融实验中,也说明了好的图像生成器确实对学习表示能力有很大的帮助)。
BigBiGAN
BigBiGAN从网络结构来看(相比于BiGAN),将生成器部分用BigGAN(是一个卷积网络,不同于BiGAN中使用,而是参数化为高斯分布,通过非确定基础模型来不断完善),将判别器分为三个部分:只关注的(是一个卷积网络ConvNet),只关注的(是一个多层感知机MLP),关注两者关系的(是一个多层感知机MLP)。
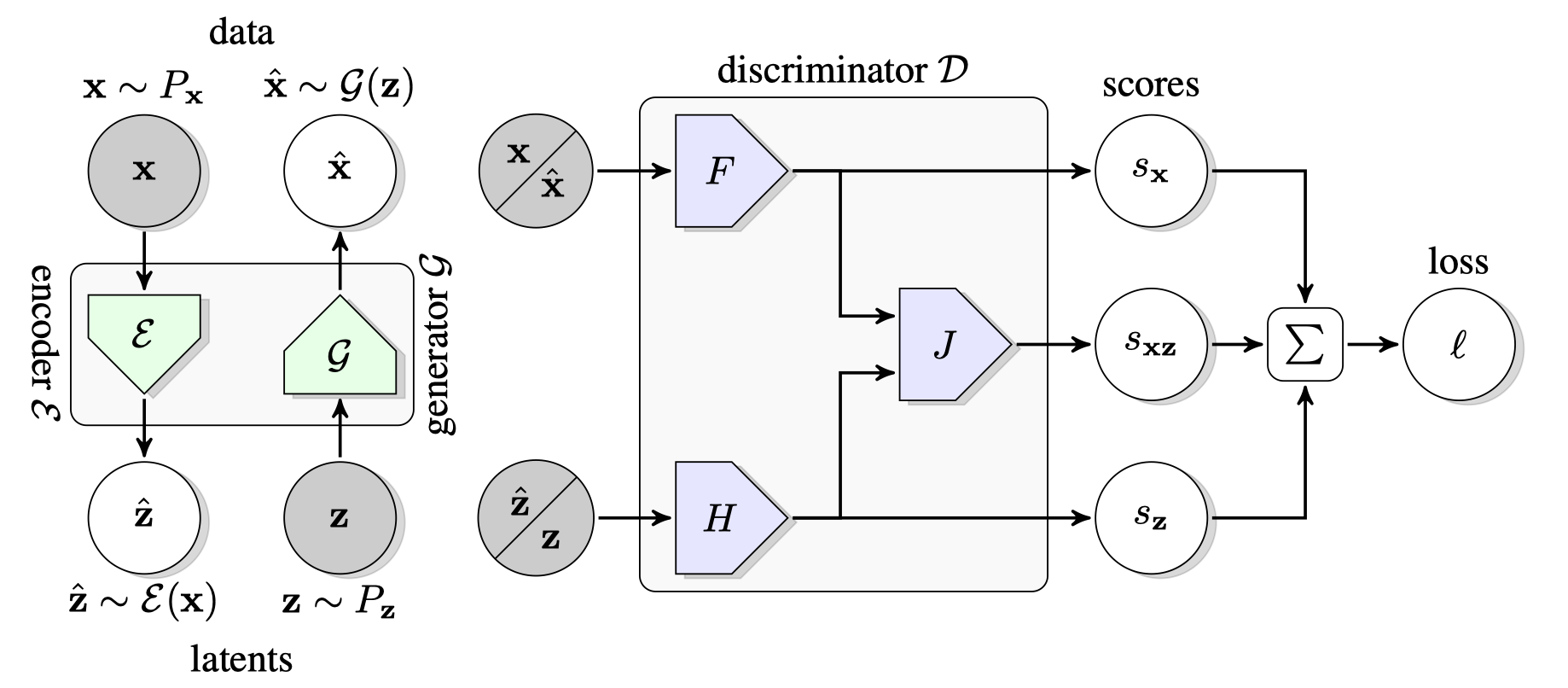
对于BiGAN的损失来说,使用Jensen-Shannon divergence来衡量,在这里就是:
(和BiGAN不同),其损失函数很明显的由两个部分组成,一个是生成器这部分(生成的数据应该可以以假乱真),一个是判别器这一部分(可以区分出赝品)。
考虑单独是因为分别可以提高分类性能,产生可区分的输出(消融实验中得到)
首先来先计算三个部分的得分:
用表示对于一个样例来说的损失量(时,关注于;时,关注于):
其中,是判别器的正则化部分(实验说明这三个部分在合并同类项,即之后,准确率有下降)。最小化,得到的最优参数(之后有做解耦实验,提高10倍后,可以加快速度,并提高表示能力);最小化,得到的最优参数。
对于所有数据来说(的分布为,的分布为,这里的分布一般都是简单连续的,如高斯分布):
和BiGAN还是一脉相承的。
结果:
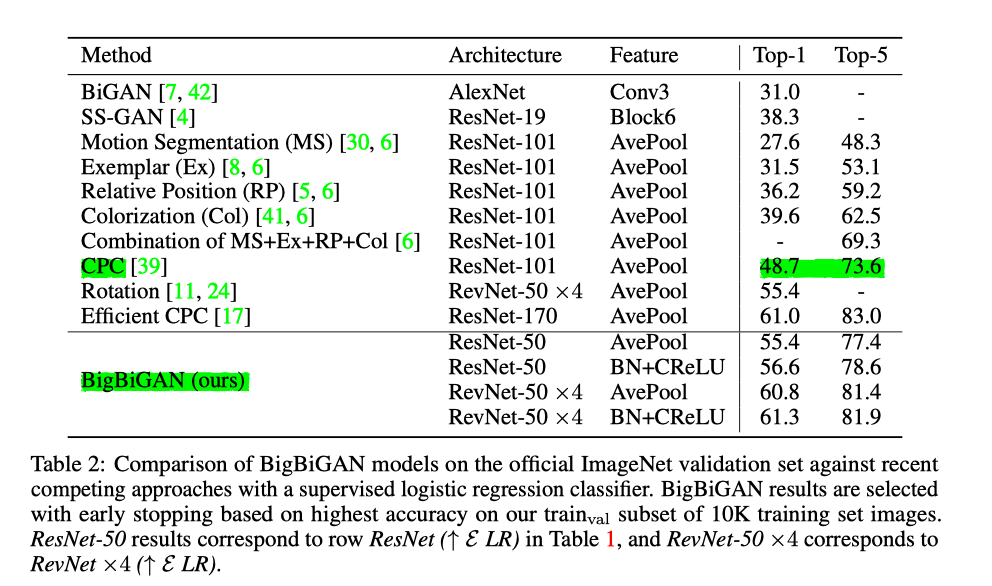
Contrastive Multiview Coding9
这篇论文提到由于每个视图都是嘈杂且不完整的,所以提出一种对比编码来最大化学习多个视图(例如,不同的图像通道或不同的模态之间,论文中提到将RGB的图像空间映射到Lab空间,再将每张图片拆分成L(光照)和ab(色度),就得到了同一图片的两个不同views。这两个views互为正对,与其他图片的views为负对)之间不变的因素。基于学习一种特征嵌入方法,以便将同一场景的视图映射到附近的点,而将不同场景的视图映射到相距较远的点。实验证明了对比目标优于交叉视图预测,并且随着视图数量的增加,学习表示的质量也随之提高。
预测学习:
假设分别代表同一张图片的光照和色度,交叉视图预测是学习中间表示z,构建编码器和解码器,,再使用loss,如L1或者L2来衡量和的距离。这个方法很适合风格转换的应用场景。
但是由于优化目标只关注和的相似性,默认了元素之间是独立的,即,这样会丢失建模关联和复杂结构的能力。
对比学习:
对比学习是通过对比与此视图一致和不一致的视图。将不同views统一映射到同一个特征空间,再利用这些embeddings进行对比学习。更加直观的,且丢失的细节更少,也更好进行比较。
方法:
正样本对的定义来自联合分布,或;负样本对的定义来自边缘乘积,或。训练一个函数来区分正负样本。
具体用表示如下:
但是可见计算量很大
又因为:
最优解正比于joint distribution和product of marginals的密度比,论证了视图数量N越大,学习表示的质量越高。
同时CPC证明了负样本k越多,表征能力越好:
于是作者给出了两个trick:
使用NCE来近似模拟full softmax,使用二分分类器从噪声样本分布中区分数据分布。噪声分布是一个对所有元素的uniform分布,即。如果我们对每个数据样本取样m个噪声样本,那么给定来自数据分布的后验概率是:
使用模型分布代替,最小化正确label D的负对数后验概率,得到NCE估计的概率函数:
为了降低运算量,引入了memory bank,可以从中有效检索m个噪声样本而不需要重新计算。
使用Deep InfoMax的方法,使用子块而不是完整图像来增加每个batch的负样本数量,并增加层之间的对比(相对来说不需要memory bank,但是效果比NCE弱一些)
两个的视图,可以自然地拆分成两个编码器,。
对于多视图的之间的关系,作者给出了两种方法:core view(选取一种为anchor,枚举其他views);full graph,两两互相匹配。即需要在效果和效率之间权衡。
但是实际上对于一个样本之间交互部分应该是特征,需要忽略一些噪声,交互信息定义为。
Representation Learning with Contrastive Predictive Coding10
补CPC v1笔记
这篇文章提出对比预测编码CPC的方法来将高维数据压缩到潜在空间中,使得模型更加容易预测,通过自动渐进的方式在潜在空间中预测特征,从共享信息中抽取有用的表示,忽略低维噪声。使用负样本来最大化利用特征样本,用可能性对比损失/噪声对比评估NCE来衡量。
方法简单,且计算量小。
CPC 主要是利用自回归的想法,对相隔多个时间步长的数据点之间共享的信息进行编码来学习表示,这个表示 可以代表融合了过去的信息,而正样本就是这段序列 t 时刻后的输入,负样本是从其他序列中随机采样出的样本。CPC的主要思想就是基于过去的信息预测的未来数据,通过采样的方式进行训练。
自动渐进方式预测示意图:
在学习过程中,共享信息变得更具有代表性,也称为慢特征(即随着时间的变换,这个慢特征仍然还在),模型也变得更加通用。
由于平方差损失、交叉熵损失不是很有效,而条件损失过于细节。因此使用了NCE。
对于相互信息通过压缩向量来表示,定义如下(x为数据,c为内容):
目标是最大化相互信息。
非线性编码器将连续的输入映射到潜在表示低维表示中
通过自动渐进模型总结之前的中间表示,产生中间语义表示
通过密度比值来保持之间的相互信息,即
简单表示为log-bilinear模型:
用InfoNCE来计算损失,表示N-1个负样本
最小化损失,最大化相互信息
参数:
- 256x256 image
- extract a 7x7 grid of 64x64 crops with 32 pixels overlap
- ResNet-v2-101 encoder, 1024-d vector per 64x64 patch, this results in a 7x7x1024 tensor
- a PixelCNN-style autoregressive model to make predictions in following rows top-to-bottom
- Adam optimizer with a learning rate of 2e-4 and trained on 32 GPUs each with a batch size of 16.
- Linear classifier uses SGD with a momentum of 0.9, a learning rate schedule of 0.1, 0.01 and 0.001 for 50k, 25k and 10k updates and batch size of 2048 on a single GPU. When training the linear classifier we first spatially mean-pool the 7x7x1024 representation to a single 1024 dimensional vector.
Selfie: Self-supervised Pretraining for Image Embedding11
这篇论文提出预训练自我监督图像嵌入技术Selfie,是BERT模型(双向表征学习,NLP)在连续数据(如图像)上的实现,并且结合了CPC loss。从同一图像的patches中用distractor抽取出正确的patches。
准确率可以超过监督学习,在ImageNet原始图像上,前5%增加了11.1;前8%增加了2.3。
结构图:
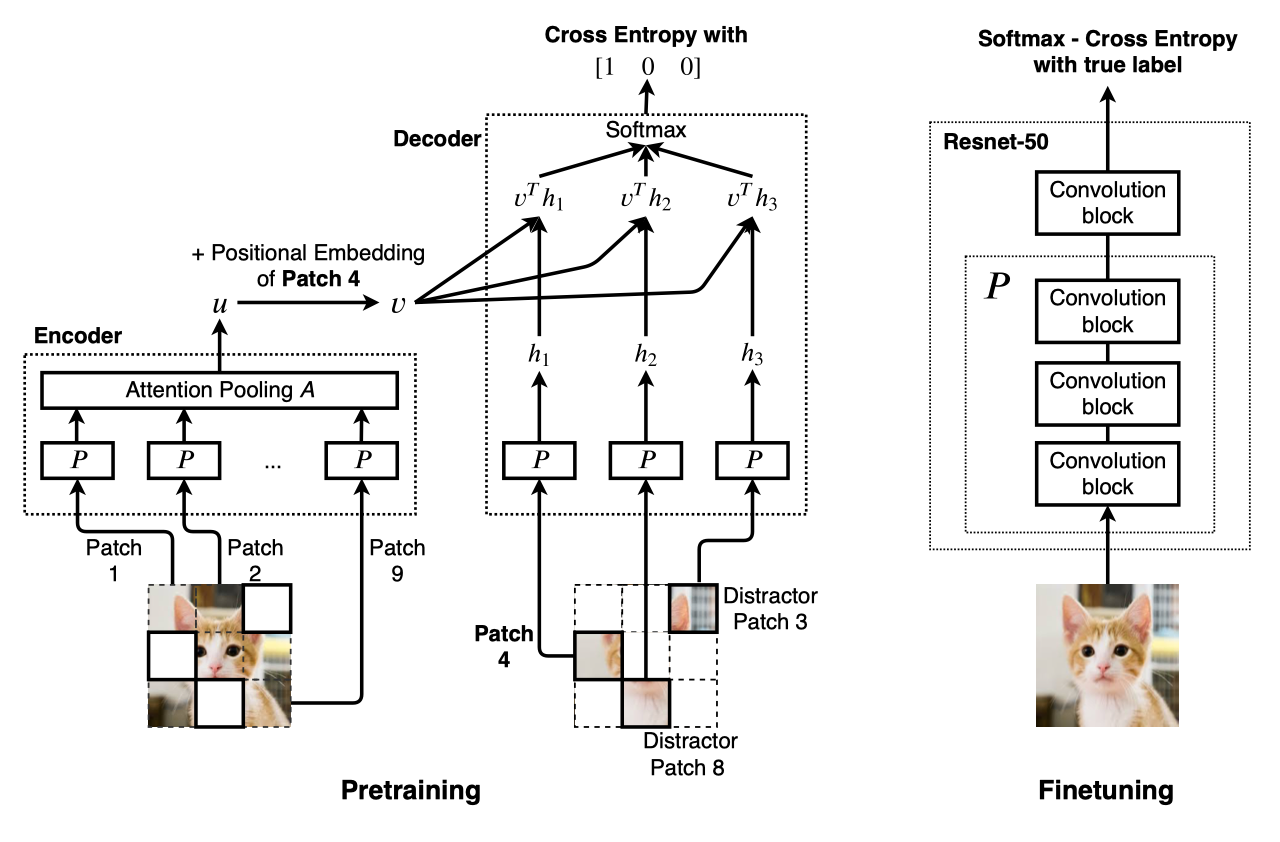
预训练:
编码器将patch经过模型P,并用Attention 池化A总结这些表征后得到一个向量u(编码器的工作就是将图像信息压缩,用u来代表整个图像,可以用来恢复图像)
对于Attention pooling A,使用transformer layers,两个全连接层来实现池化
解码器将patch直接通过模型P得到向量h
通过位置嵌入(包括行和列,相比每个位置一个减少了参数)从解码器中随机选择一个patch y的向量表示v
将v和h通过点乘得到两者的相似度
用softmax得到相关性最高的预测位置
将y的预测位置与实际的用交叉熵损失计算(使用分类损失而不是回归损失,因为其对于小的改变不敏感)
Finetuning:
- 将ResNet-50初始化为模型P
- 将图片通过模型得到预测,与标签通过交叉熵损失计算
参数
- Image 224 × 224, patch 32 × 32; Image 32 × 32, patch 8 × 8.
- ResNet-50v2, each residual connection with a drop rate of 10%.
- three attention blocks are added with a hidden size of 1024, intermediate size 640 and 32 attention heads on top of the patch processing network P.
- Momentum Optimizer with Nesterov coefficient of 0.9.
- batch size 512.
- learning rate: a warm up phase of 100 steps in [0.01, 0.02, 0.05, 0.1, 0.2, 0.4], L2 weight decay of magnitude 0.0001
A Simple Framework for Contrastive Learning of Visual Representations12
这篇文章感觉比MoCo对于数据的变换增强了,还增加了一个非线性变换,并且研究了数据增强之间的关联,得出随机裁剪、随机颜色变换这样顺序的简单组合在ImageNet上准确率更高。由于数据变换,一个batch所包含的图片大大增加了,使用了LARS优化器,以及Global BN(shuffle)。需要TPU的支持。并且做了好多实验,对各种方法也研究的很透彻。
可以认为MoCo探究的是负样本的数量,而SimCLR探究的是负样本的生成。
主要四个方面的亮点:
- 更大的batch,提供更多的负样本,并且由于大的batch,所以不需要考虑memory bank的问题;更多的迭代次数
- 不同数据增强方式(比单一的更好)
- 在表征层和最后的损失层增加非线性转换,全连接网络(如MLP)
- 对比交叉熵损失NT-Xent
结构图:

$f(\cdot)$是一个基础网络,$h_i$是一个特征表示,$g(\cdot)$是一个映射头部,用对比损失最大对齐相同图片x的不同view;当训练完成后,丢弃$g(\cdot)$,用$f(\cdot)$完成downstream task。
方法:
- 随机采样一个batch;
- 对batch里每张图像做两种随机增强,可以认为是两个view;
- 让同一张图的不同view在latent space里靠近,不同图的view在latent space里远离,通过对比损失NT-Xent (the normalized temperature-scaled cross entropy loss)实现。
- 相关性:$sim(u,v)=\frac{u^Tv}{|u||v|}$
- 损失函数:$l_{i,j}=-\log\frac{\exp(sim(z_i,z_j)/\tau)}{\sum_{k=1}^{2N}1_{[k\not=i]}\exp(sim(z_i,z_k)/\tau)}$

参数:
- backbone:ResNet-50(4x),网络参数更多
- MLP head:$z_i = g(h_i) = W^{(2)}\sigma(W^{(1)} h_i),\sigma=ReLU$
数据增强示意图:
对比各种方法

Improved Baselines with Momentum Contrastive Learning13
这篇文章从题目就可以看出,以MoCo为baselines,并且汲取了SimLR的MLP projection head和数据增强部分。MoCo验证了在多种检测和语义分割任务上无监督预训练可以超越监督预训练模型;SimLR减少了无监督和监督学习的特征表示在线性分类器上的性能gap。MoCo v2继承了MoCo对于在检测和语义分割上的优良迁移性能,同时又不需要SimLR那样大的batch,只需要在8-GPU上便可以训练。
参数
MLP head:2 layer(hidden layer 2048-d, with ReLU)
12dim_mlp = self.encoder_q.fc.weight.shape[1]self.encoder_q.fc = nn.Sequential(nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_q.fc)Data aug: blur and stronger color distortion
1234567891011121314151617181920212223if args.aug_plus:# MoCo v2's aug: similar to SimCLR https://arxiv.org/abs/2002.05709augmentation = [transforms.RandomResizedCrop(224, scale=(0.2, 1.)),transforms.RandomApply([transforms.ColorJitter(0.4, 0.4, 0.4, 0.1) # not strengthened], p=0.8),transforms.RandomGrayscale(p=0.2),transforms.RandomApply([moco.loader.GaussianBlur([.1, 2.])], p=0.5), # !transforms.RandomHorizontalFlip(),transforms.ToTensor(),normalize]else:# MoCo v1's aug: the same as InstDisc https://arxiv.org/abs/1805.01978augmentation = [transforms.RandomResizedCrop(224, scale=(0.2, 1.)),transforms.RandomGrayscale(p=0.2),transforms.ColorJitter(0.4, 0.4, 0.4, 0.4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),normalize]a cosine (half-period) learning rate schedule:
lr *= 0.5 * (1. + math.cos(math.pi * epoch / args.epochs))
Scaling and Benchmarking Self-Supervised Visual Representation Learning14
这篇论文主要探索了自主学习在三个方面的扩展情况【感觉这些大佬们,要不是完全新算法、新思路;要不就是做很多对照实验。然后告诉你们这些孩子这些方向去试试看,那些方向不必考虑了,感觉很厉害的样子】:
- 数据集大小:发现数据集越大,效果越好(由于发现低容量的模型AlexNet的提升不是很大,而高容量的resnet对于数据集扩大提升明显,于是做了第二个方面),呈log-linear关系;
- 模型的容量:发现模型容量越大,效果越好(而且在任务难易程度上,模型容量大的效果也更好);
- pretext task的难易程度:发现任务难度增加,在大容量模型上有很大的提升(这个难易程度不是指变换pretext tasks任务,因为很难说明任务的难易程度,而是对于某一个指定任务的难易等级,比如对于拼图任务,则将原图片分割成小块的数量作为因素;对于上色问题,则把ab的颜色考虑区间作为因素)。
对于pretext tasks的评估,作者提出了一套标准。因为pretext tasks是来学习表征能力的,因此作者认为在不同的任务上用有限监督数据和有限优化都应该有较好的结果。这里不同的问题和数据总共有9个,问题包括:图片分类问题、Low-shot (每一个类别少量标注数据)图片分类问题、视觉导航问题、目标检测问题、Surface Normal Estimation。
作者指出现在很多自监督方法,只在单一数据集(ImageNet-1M)上实验,并且pretext tasks和downstream tasks的数据集类型还一样,这并不难很好地说明pretext tasks方法对于特征的学习表现很好。
所以总的来说,对于下次新提出的方法,至少评价的时候要和之前方法用同一大小的数据集,同一模型。
一些话:
特征表示一般分成生成和区分两种方法。生成方法是对数据分布直接建模,比如最大化重构输入,可选地估计潜在变量或使用对抗训练。区分方法可以结合手动特征。
pretext tasks很多关注于空间结构、颜色信息、光照信息、旋转信息等。
pretext task难易程度实验中,对于拼图任务的结果比较明显,对于上色问题,不敏感。作者认为在其内部结构的语义特征中应该是有相关性的,但是上色精细程度与语义学习程度关联并不是很大。
自己想象的理解是对于蓝天白云的填色,(暂且用RGB来描述),只要天是蓝的,云是白的就可以了,而不必去因为天是深蓝还是浅蓝,云是乳白还是象牙白而影响对于天和云的学习。文中还指出预训练模型的数据和pretext tasks训练的数据如果相似,则表现会更好,不相似表现则不好。因此对于具体的pretext tasks应该选择合适的数据集,否则即使数据集的规模增大,可能提升效果也并不明显。因此,对于某一个pretext tasks的任务评估,应该由多种下游任务来评价,才是客观的。
Self-Supervised Learning of Pretext-Invariant Representations15
这一篇论文主要增加了一个不变性的约束,但是Yann在twitter上有称赞它。那肯定是我有眼不识泰山了。它的重点在代理任务不变的特征表示。对于某一个图片的不同转换,他通过网络所学习到的特征应该是相同的。
Invariance: refers to the property of objects being left unchanged by symmetry operations.
Covariance: refers to equations whose form is preserved by a change of coordinate system.
大概的理解就是,对于某个对称的操作,物体的特性没有改变,就是不变性。
更换坐标系之后,只要知道转换公式,目标的特性就是确定的,这就是协变性。感觉就是协同变换。比如,对于笛卡尔坐标系变换到极坐标系,这个转换的公式是确定不变的,因此不管是在哪个坐标系下的表达,实际上这个物体的形状大小等等信息都是没有改变的,本质不变。但是它有变化,比如我们的温度是由三个因素x,y,z决定的,我们还可以用a,b,c来表示,即
T(x,y,z)=T(a,b,c)。但是T对于x的偏导数和T对于a的偏导数是不相同的,而是T对于x的偏导数应该是T分别对a,b,c的偏导数与a,b,c对于x的偏导数的乘积之和。作者想要表达的是,之前的代理任务都是在协变性下完成的,分离同一图片的不同变换和其他图片;而现在他所提出的则是要在不变性下能够成立,增强了约束条件,同一图片变换之间的相似性。
主要思路:
数据集;特征表示;图片转换;用来学习的卷积网络;相似性损失函数;相似性分数(余弦相似度)
从经验上来说,我们对于不变性的损失函数应该如下定义:
之前文章讨论的都是协变性:
是衡量转换某些性质的函数。在图片变换之下,维护与语义无关的信息。
每个正样本对有N个负样本,我们希望正样本对的分数高,而负样本对的分数低。因此这里我们使用了带有噪声的对比评估模型h,我们希望这个比值应该尽可能接近1:
为了使得正样本相似,负样本不相似,我们使用NCE损失函数(Noise-Constrastive Estimation Loss)【假设X是从真实的数据(或语料库)中抽取的样本,其服从一个相对可参考的概率密度函数P(d),噪音样本Y服从概率密度函数为P(n),噪音对比估计(NCE)就是通过学习一个分类器把这两类样本区别开来,并能从模型中学到数据的属性。】由于考虑到不同变换(可以当作不同坐标系)下,因此我们对于原图用前缀,对于变换后的图片用前缀进行转换为统一的128维表示。
对于本文仍然采用内存空间来存储已有的图像特征表示。是在之前迭代中计算的特征表示的指数移动平均值【这里的移动平均是因为迭代更新网络,使得的值有所变换,就是在迭代中不断更新内存空间中的变量】。
最终损失函数为:
现在我来重新以我的理解说一遍,以更好地说明这一篇和MoCo的区别(它的结果是比MoCo更好的)
- 首先它将初始图片通过卷积网络学习得到特征表示,然后特征表示通过线性映射得到128维的一个表示向量,放入内存空间之中。
- 然后我们就可以开始第一轮,正样本对应该具有不变性,负样本对应该不同的学习了。
- 首先我们重新计算一个特征表示,然后将它的原始数据进行随机变换为,同样通过卷积网络学习得到特征表示,然后特征表示通过线性映射得到128维的一个表示向量,这个向量应该和接近,计算的前半部分;
- 负样本对应该尽量远离,我们就将和内存空间中除的所有特征向量通过噪音对比估计得到一个分数,计算的后半部分
- 还需要对于的前后表示尽量接近,就是的后半部分
- 最后我们需要更新这一轮的值,应该是指数偏移的均值【这里有些疑问,是直接更新,还是先保存,使得这一轮都和上一轮的特征表示进行对比学习呢】
- 重复多轮之后,我们就可以将这个卷积网络运用到下游任务之中了。
几个问题:
- MoCo的几个“缺点”(和这篇文章的不同,不能确定是不是这个因素导致的):
- 没有用的历史值的指数偏移平均,而是每次都取了网络的新值【如果学习好的话,这个新值其实就代表了m】
- 选择的负样本是队列的长度,而这里的负样本是除正样本之外的所有【但是当队列的长度大于内存长度的时候,那还是MoCo的负样本更加多】
- MoCo损失函数只有正负样本的对比,这里还有一个前后学习的特征应该相似这个约束
- MoCo学习是否属于同一张图片;而PIRL学习变换前后特征是否不变
- MoCo有两个卷积网络,而PIRL是共享的
- MoCo的“优点”(我觉得是):
- 用了队列,PIRL的内存空间需要包含所有的特征表示,这也意味着它的数据集不可以过大,像MoCo可以用ImageNet,这对于PIRL是不可能的
- MoCo的损失函数用的是InfoNCE,这里用的是NCE(实际代码中用了交叉熵损失函数)
- 对于这个不变性,MoCo虽然同一张图片的不同变换的特征应该有共同点的,但是没有强调;而PIRL是同一张图片的不同变换的特征应该是相等的。这里用的f和g,在MoCo就是两个网络增加的两个线性映射,而在代码中我感觉这两者是用一个线性映射的。
1. Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey https://arxiv.org/pdf/1902.06162.pdf ↩
2. Learning Correspondence from the Cycle-consistency of Time https://arxiv.org/pdf/1903.07593.pdf project address http://ajabri.github.io/timecycle ↩
3. Momentum Contrast for Unsupervised Visual Representation Learning https://arxiv.org/pdf/1911.05722.pdf ↩
4. Data-Efficient Image Recognition With Contrastive Predictive Coding https://arxiv.org/pdf/1905.09272.pdf ↩
5. Revisiting Self-Supervised Visual Representation Learning http://openaccess.thecvf.com/content_CVPR_2019/papers/Kolesnikov_Revisiting_Self-Supervised_Visual_Representation_Learning_CVPR_2019_paper.pdf ↩
6. S4L- Self-Supervised Semi-Supervised Learning http://openaccess.thecvf.com/content_ICCV_2019/papers/Zhai_S4L_Self-Supervised_Semi-Supervised_Learning_ICCV_2019_paper.pdf ↩
7. Self-Supervised Representation Learning by Rotation Feature Decoupling http://openaccess.thecvf.com/content_CVPR_2019/papers/Feng_Self-Supervised_Representation_Learning_by_Rotation_Feature_Decoupling_CVPR_2019_paper.pdf ↩
8. Large Scale Adversarial Representation Learning https://arxiv.org/pdf/1907.02544.pdf ↩
9. Contrastive Multiview Coding https://arxiv.org/pdf/1906.05849.pdf ↩
10. Representation Learning with Contrastive Predictive Coding https://arxiv.org/pdf/1807.03748.pdf ↩
11. Selfie: Self-supervised Pretraining for Image Embedding https://arxiv.org/pdf/1906.02940.pdf ↩
12. A Simple Framework for Contrastive Learning of Visual Representations https://arxiv.org/pdf/2002.05709.pdf ↩
13. Improved Baselines with Momentum Contrastive Learning https://arxiv.org/abs/2003.04297 ↩
14. Scaling and Benchmarking Self-Supervised Visual Representation Learning https://arxiv.org/pdf/1905.01235.pdf ↩
15. Self-Supervised Learning of Pretext-Invariant Representations https://arxiv.org/pdf/1912.01991.pdf ↩
转载请注明出处,谢谢。
愿 我是你的小太阳
