This is my blog.
初识Reinforcement Learning
很多概念,只是提及,之后待补充
强化学习
Reinforcement Learning is much more focused on goal-directed learning from interaction
让计算机实现从一开始什么都不懂(即没有数据和标签),通过不断地尝试,从错误中学习(规律),最后找到规律,学会了达到目的的方法。
强化学习最大的特点是在交互中学习(Learning from Interaction)。Agent在与环境的交互中根据获得的奖励或惩罚不断的学习知识,更加适应环境。
强化学习不同于无监督学习(虽然有些人认为算无监督学习),它试图最大化奖励信号而不是试图找到隐藏的结构。
深度学习具有较强的感知能力,但是缺乏一定的决策能力;而强化学习具有较强的决策能力,但对感知问题束手无策
These three characteristics—being closed-loop in an essential way, not having direct instructions as to what actions to take, and where the consequences of actions, including reward signals, play out over extended time periods—are the three most important distinguishing features of reinforcement learning problems.
Beyond the agent and the environment, one can identify four main subelements of a reinforcement learning system: a policy, a reward signal, a value function, and, optionally, a model of the environment.
Whereas the reward signal indicates what is good in an immediate sense, a value function specifies what is good in the long run.
和其他学科关系,生物启发……
分类
- Reinforcement Learning: 不理解环境Model-Free RL
- 基于价值Value-Based: RL
- 根据最高价值来选择;一定选择价值最高的
- Q Learning(回合更新制,离线学习off-policy)
- Sarsa(回合更新制,在线学习on-policy)
- Deep Q Network(DQN)
- DQN改进
- Dueling DQN
- DDQN
- 基于概率Policy-Based RL
- 每种动作都有可能会被选中,只是可能性不同;但是不一定是选择概率最高的
- Policy Gradients(单步更新制)
- 两者结合,Actor-Critic,一种时序差分算法
- Actor基于概率作出动作
- critic对作出的动作给出价值
- DDPG(Continuous control with deep reinforcement learning)深度确定策略梯度
- 基于价值Value-Based: RL
- 理解环境Model based RL
- Dynamic Programming
Markov
The formulation is intended to include just these three aspects—sensation, action, and goal—in their simplest possible forms without trivializing any of them.
在马尔科夫链上包含两种状态转化:状态到动作、动作到状态
MDP
MDP:Markov Decision Process,马尔科夫决策
时间不变性:随着MDP的过程的进行,最终不同时刻下的相同状态总会有着相同的价值
Model-Free
代理在每次操作之前不可以预测下一个状态和奖励的算法,一步步来试图学习最优的策略,经过多次迭代后得到整个环境中最优的策略。
model-free reinforcement learning does not use environment to learn the action that result in the best reward.
The model-free learning only uses its action and reward to infer the best action.
In model-free learning, the agent simply relies on some trial-and-error experience for action selection.
运用蒙特卡洛的方法:基于经验(包括样本序列的状态、动作、奖励)平均来代替随机变量的期望(随机样本估计期望)[之后再补充蒙特卡洛]
虽然没有环境模型,无法评估当前策略的好坏,但是在实际中使用的更多
Model-based
代理在每次操作之前可以预测下一个状态和奖励的算法;提前知道转移概率,来推断之后的可能性,从而找到最优马尔可夫链
The model-based reinforcement learning tries to infer environment to gain the reward
The model-based learning uses environment, action and reward to get the most reward from the action.
In model-based learning, the agent exploits a previously learned model to accomplish the task
更多采用Dynamic Programming动态规划来解决问题,将一个问题转化为多个可重复利用和存储的优化的子问题。
On-policy
交互更新值函数,获取策略,一步步朝着最优值函数,进而获取最优策略
优点:
- 直接,简洁
缺点:
- 可能陷入局部最优
Off-policy
优点:
- 通用性强,保证了探索性
- 数据全面性,所有行为都可覆盖
缺点:
- 每次对于状态的值函数的估计过高
- 存在一些状态未被采样到
Value-Based
基本思想
According to state, calculate approximate value function instead a table, then choose the action。
更新值函数,让其最优化(贪心最大化或者随机策略$\varepsilon$-greedy),基于值函数选取策略
Notation
状态值函数(计算期望)
$\hat v(s,W)\approx v_\pi(s)$ for the approximated value of state s given weight vector w
Typically, the number of parameters n (the number of components of w) is much less than the number of states, and changing one parameter changes the estimated value of many states.
when a single state is backed up, the change generalizes from that state to affect the values of many other states.
Evaluating function: always use root-mean-squared error (RMSE均方根误差)
$s\to[0,1]\ and\ \displaystyle \sum_sd(s)=1$
优点
- 决策简单
- 主要应用于离散动作空间的任务
缺点
- 值函数的方法无法解决状态空间过大或者不连续的情形
Policy-Based
基本思想
参数化策略$\pi$为$\pi_\theta$,然后计算得到动作上策略梯度,沿着梯度方法,一点点的调整动作,逐渐得到最优策略。
每种动作都有可能会被选中,只是可能性不同;不一定是选择概率最高的
先更新全部状态的值函数,再更新策略,再更新值函数,如此反复。
包括:
策略评估
- 寻找一个描述策略更为准确的值函数
策略更新
- 基于优化后的值函数,找到一个好的策略
优点
- 策略化参数的方法更简单,更容易收敛到局部极值点
- 稳定性,可靠性强,具有完备的理论性
- 主要适用于连续动作空间的任务
- 收敛快
缺点
- 在评估单个策略时,评估的并不好,容易收敛到局部最小值,方差过大
- 大多数的策略梯度算法难以选择合适的梯度更新步长,因而实际情况下评估器的训练常处于振荡不稳定的状态
- 算法的实现和调参过程都比较复杂
Actor-Critic
优点:
- 相比以值函数为中心的算法,Actor - Critic应用了策略梯度的做法,这能让它在连续动作或者高维动作空间中选取合适的动作
- 相比单纯策略梯度,Actor - Critic应用了Q-learning或其他策略评估的做法,使得Actor Critic能进行单步更新而不是回合更新,比单纯的Policy Gradient的效率要高。不再使用采样得到的真实回报,降低了因为采样率导致的方差
Algorithm
Q Learning
Q-Table:创建一个表格。通过它,我们可以为每一个状态(state)上进行的每一个动作(action)计算出最大的未来奖励(reward)的期望。通过这个表格,我们可以知道为每一个状态采取的最佳动作。
学习动作值函数(action value function)
动作值函数(或称「Q 函数」)有两个输入:「状态」和「动作」。它将返回在该状态下执行该动作的未来奖励期望。
$Q^\pi(s_t,a_t)=E[R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+\cdot\cdot\cdot|s_t,a_t]$
初始化为零,通过迭代地使用Bellman方程(动态规划方程)更新Q(s,a),给出越来越好的近似
Algorithm

From simoninithomas
|
|
Deep Q Network(DQN)
是一种融合了神经网络和Q Learning的方法,有效解决了使用神经网络非线性动作值函数逼近器带来的不稳定和发散性问题
将状态和动作当成神经网络的输入,然后经过神经网络分析后得到动作的 Q 值。
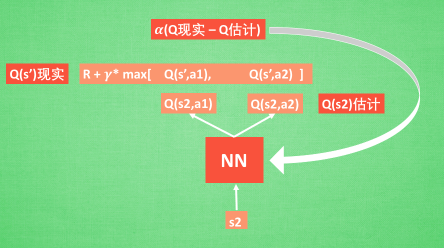
通过 NN 预测出Q(s2, a1) 和 Q(s2,a2) 的值, 这就是 Q 估计. 然后我们选取 Q 估计中最大值的动作来换取环境中的奖励 reward;通过旧NN参数加学习率 alpha 乘以Q现实和Q 估计的差来更新神经网络的参数。
Experience replay
存在一个记忆库,用于每次DQN更新时,随机抽取学习之前的经历,切断相关性。
Fixed Q-targets
通常情况下,能够使得Q大的样本,y也会大,这样模型震荡和发散可能性变大。而构建一个独立的慢于当前Q-Network的target Q-Network来计算y,使得训练震荡发散可能性降低,更加稳定。
DQN 中使用到两个结构相同但参数不同的神经网络, 预测 Q 估计 的神经网络具备最新的参数, 而预测 Q 现实的神经网络使用的参数则是很久以前的
Algorithm

算法流程描述:(from 莫烦)
|
|
神经网络结构
target_net 用于预测 q_target 值, 他不会及时更新参数,是eval_net的历史版本,通过trainable=True
eval_net 用于预测 q_eval, 这个神经网络拥有最新的神经网络参数
不过这两个神经网络结构是完全一样的, 只是里面的参数不一样
DDQN
DDQN:Double DQN,本质上是构造了两个Q网络
Dueling DQN
DDPG
深度确定策略梯度:Continuous control with deep reinforcement learning
DQN+actor-critic算法
后记
好冷的天呐~
成功将星巴克的三杯圣诞主题外加小甜点都吃到啦~
嘿嘿嘿~
转载请注明出处,谢谢。
愿 我是你的小太阳
