深度迁移部分,其实在上一篇中,DAN、DDC都是深度迁移
综述-Deep Visual Domain Adaptation: A Survey—20188
这篇综述讨论的是深度域适配方法
核心贡献
(根据数据属性分类)分为监督和无监督,以及两者混合的半监督
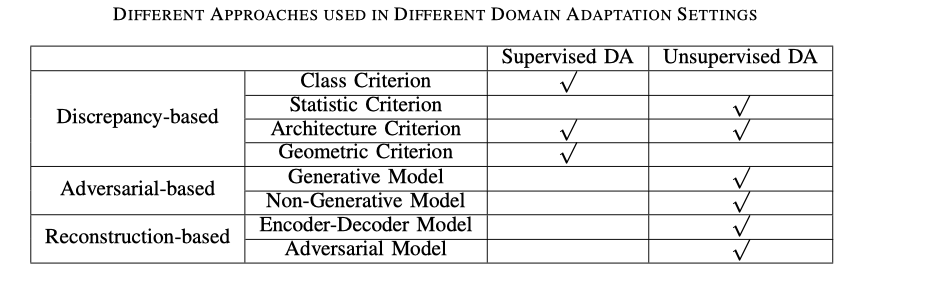
(基于训练损失分类)可以分为分类损失classification loss,差异损失discrepancy loss和对抗性损失adversarial loss。则可以分为基于差异的深度域适配Discrepancy-based deep DA,基于对抗的深度域适配Adversarial-based deep DA,基于重构的深度域适配Reconstruction-based deep DA 这三大类方法
(Multi-step (or transitive) DA多步域适配分类)考虑到源域和目标域的差异,可以多步域适配,有三种机制:手工制作hand-crafted,基于特征 feature-based和基于表示的机制representation-based
(CV上的应用)例如:图像分类、面部识别、风格转移,对象检测,语义分割和人物识别。
指出了当前方法的缺陷和未来研究的方向
核心内容
深度是指深度特征,而不是深度方法;
从广义上讲,深度DA是一种利用深度网络来提高DA性能的方法。具有深层特征的浅层方法可被视为深度DA方法。而深度网络只提取矢量特征,对直接传递知识没有帮助。
从狭义上讲,深度DA基于为DA设计的深度学习架构,可以通过反向传播从深度网络中获得最终效果。 直观的想法是将DA嵌入到学习表示的过程中,并学习具有语义意义和域不变性的深层特征表示。 通过“良好”的特征表示,目标任务的性能将显着提高。
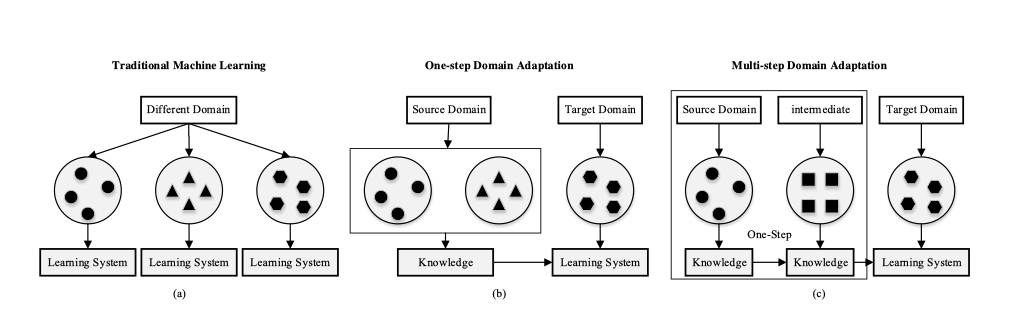
单步域适配
基于差异的深度域适配Discrepancy-based deep DA
利用fine-tuning来优化两个域的偏移。分为类标准,统计标准、结构标准、几何标准基于对抗的深度域适配Adversarial-based deep DA
域鉴别器通过对抗性目标来鼓励域混淆(deep domain confusion network—DDC),以最小化源域和目标映射分布之间的距离。
根据是否存在生成模型分为生成模型GAN和非生成模型基于GAN,将判别模型与生成成分结合起来。 其中一个典型案例是使用源图像、噪声向量或两者来生成与目标样本类似的模拟样本,并保留源域的注释信息。
CoGAN的核心思想是生成与合成源数据配对的合成目标数据。 它由一对GAN组成:GAN 1用于生成源数据,GAN 2用于生成目标数据。 生成模型中的前几层和判别模型中的最后几层的权重是相关的。 这种权重共享约束允许CoGAN在没有通信监督的情况下实现域不变的特征空间。 经过训练的CoGAN可以将输入噪声矢量调整为来自两个分布的成对图像并共享标签。 因此,合成目标样本的共享标签可用于训练目标模型。
$L_d,L_t,L_c$分别是对抗损失、softmax损失和内容相似性损失
非生成模型使用源域中的标签学习判别表示,并通过域混淆将目标数据映射到同一空间,从而导致域不变。
基于重构的深度域适配Reconstruction-based deep DA
使用数据重建作为辅助任务来确保特征不变性。重建器可以确保特定的域内表示和域间表示。分为编码器 - 解码器重建和对抗重建。
Encoder-Decoder Reconstruction编码器 - 解码器重建:通过使用堆叠自动编码器SAE。一般学习的编码器网络与数据重建的解码器网络相结合。基本的自动编码器框架是一个前馈神经网络,包括编码和解码过程。自动编码器首先对一些隐藏表示的输入进行编码,然后将该隐藏表示解码回重建版本。基于编码器 - 解码器重建的DA方法通常通过共享编码器学习域不变表示,并通过源域和目标域中的重建损失来维持域表示。
对抗重建:通过经由GAN鉴别器获得的循环映射,为每个图像域内的重建图像和原始图像测量差异。
多步域适配
- 确定与源和目标域相关的中间域
- 知识转移过程将在源域,中间域和目标域之间执行,信息损失较少。
- 关键是如何选择和利用中间域
分为三类:手工制作,基于特征和基于表示的机制。
手工制作:用户根据经验确定中间域
基于实例:从辅助数据集中选择数据的某些部分以组成中间域以训练深层网络
DDTL(distant domain transfer learning)通过删除不相关的源数据,来实现:其中,$\hat x_*^i$是重建后的数据,中间数据$I^i$,$f_e,fd$是编码和解码的参数
基于表示:通过冻结先前训练的网络并使用其中间表示作为新表示的输入
Domain Adaptation域适配
对于一个随机变量$X$,$x\in X$是它的元素,对于每一个元素,都对应一个类别$y\in Y$。那么,它的边缘概率为$P(X)$,条件概率为$P(y|X)$,联合概率为$P(X, y)$。
大多数域适配方法都假设两个领域的边缘分布不同,即$P\not=Q$,但条件分布相同,即$P(Y_s|X_s)= Q(Y_t|X_t)$。
应用
图像分类
面部识别
当训练图像中不存在测试图像的变化时,面部识别的性能显着降低。数据集移位可以由姿势,分辨率,照明,表达和模态引起。物体检测
物体检测的最新进展是由基于区域的卷积神经网络驱动的。 它们由窗口选择机制和分类器组成,这些分类器是使用从CNN提取的特征预先训练的标记边界框。 在测试时,分类器决定通过滑动窗口获得的区域是否包含该对象。 虽然R-CNN算法是有效的,但是需要大量标记数据的边界框来训练每个检测类别。 为了解决缺少标记数据的问题,考虑到窗口选择机制是域独立的,可以在分类器中使用深度DA方法来适应目标域。
语义分割
密集预测的完全卷积网络模型(FCN)已经证明在评估语义分段方面是成功的,但是在域移位下它们的性能也会降低。因此,一些工作也探索了使用弱标签来提高语义分割的性能。图像转换
最近,图像到图像的转换在深度DA方面取得了巨大的成功,并且已经应用于各种任务,例如样式转换。特别地,当源图像和目标图像的特征空间不相同时,应该通过异构DA执行图像到图像的转换。通过fine-tune深度网络来匹配统计分布是实现图像到图像转换的另一种方式。通过总损失来调整CNN以实现DA,这是内容和风格损失之间的线性组合。内容损失使原始图像与较高层中生成的图像之间的特征表示的均方差最小化,而样式损失最小化每层上它们的Gram矩阵之间的元素均方差。
人物识别
当给定人的视频序列时,人员重新识别该人是否已经在另一个相机中以补偿固定设备的限制。域引导的丢失算法来丢弃无用的神经元,以便同时重新识别多个数据集上的人。图像字幕
图像字幕自动描述具有自然句子的图像。 由于缺乏配对的图像 - 句子训练数据,DA利用其他源域中的不同类型的数据来应对这一挑战。提出了一种新的对抗性训练程序(captioner v.s. critics),用于使用成对的源数据和未配对的目标数据进行跨域图像捕获。
问题以及未来研究方向
首先,大多数现有算法都关注于同构深度DA,它假设源域和目标域之间的特征空间是相同的。但是,在许多应用中,这种假设可能并非如此。异构深DA可能在未来吸引越来越多的关注。
此外,深度DA技术已成功应用于许多实际应用,包括图像分类和样式转换。以及涉及超越分类和识别的适应性,例如物体检测,人脸识别,语义分割和人物识别。如何在没有数据或数据量非常有限的情况下实现这些任务可能是未来几年深度数据库应该解决的主要挑战之一。
最后,由于现有的深度DA方法旨在对齐边际分布,因此它们通常假设跨源和目标域的共享标签空间。然而,在实际场景中,源和目标域的图像可以来自不同的类别集合,或者仅共享几个感兴趣的类别。
Fine-tune 最简单的深度迁移学习1
在论文《How transferable are features in deep neural networks?》中可以得到:
- 深度迁移网络中加入fine-tune,效果会提升比较大,可能会比原网络效果还好;
- Fine-tune可以比较好地克服数据之间的差异性;
- 深度迁移网络要比随机初始化权重效果好;
核心贡献
通过反向传播来进一步解锁卷基层,以提升效果
核心内容
冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层),训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层。因为前面几层,一般提取的是共性、特征,后面几层具体化,因此可以适当公用基础层
在不同数据集下使用的微调方法不同:
数据量少,数据相似度高
修改最后几层或最终的softmax图层的输出类别数据量少,数据相似度低
冻结预训练模型的初始层(比如k层),并再次训练剩余的(n-k)层数据量大,数据相似度低
从头开始训练神经网络(Training from scatch)
数据量大,数据相似度高
保留模型的体系结构和模型的初始权重。然后,使用在预先训练的模型中的权重来重新训练该模型
有四种主要的技术:
类标准Class criterion
使用类标签信息作为在不同域之间传递知识的指南;当这些样本不可用时,可以采用其他一些技术来代替类标记数据,例如伪标签其中,$\hat y_i$是softmax模型预测的值,代表是某一类的可能性
另外还有边际Fisher分析准则和MMD准则来最小化:
其中,$\alpha,\beta,\gamma$是正则参数,$W^{(m)},b^{(m)}$分别是m层的权重和偏差向量,$D_{ts}^{(M)}(X^s,X^t)$是MMD的表示,$S_c,S_b$分别是类内紧凑性和类间可分性。
通过概率来确定是哪一类的,即比较$p(a_m|x)$,通过贝叶斯公式$p(y|a)=\frac{p(y)}{P(a^y)}\left[a=a^y\right]$,则先验概率为
统计标准statistic criterion
最常用的比较和减少分布偏移的方法是最大平均差异(MMD),相关性对齐(CORAL),Kullback-Leibler(KL)差异和H差异等Maximum Mean Discrepancy MMD
其中,$\phi$是核函数,将原始数据映射到RKHS中,同时在单位球中有$|\phi|_H \leq 1$
则,损失函数为:
其中,$\lambda$是惩罚参数,$L_C(X^L,y)$代表分类的损失,$X^L$代表可用的标记数据,$y$是ground-truth标记,$MMD^2(X^sX^t)$代表源域和目标域的差距
CORAL:一种线性变换,它可以对齐域之间的二阶统计量
其中,$|\cdot|_F^2$是平方矩阵Frobenius范数,$C_S,C_T$分别是源数据和目标数据的协方差矩阵。
Kullback-Leibler (KL) divergence
用来估计分布之间的距离
- CMD:central moment discrepancy中心矩差异,匹配域分布的高阶矩其中,$C_k(X)=E(x-E(X))^k$是所有k阶样本中心矩,$E(X)= \frac {1}{| X |} \sum _{x\in X^x}$是经验期望
结构标准architecture criterion
旨在通过调整深度网络的架构来提高学习更多可转移特征的能力。 被证明具有成本效益的技术包括自适应批量归一化BN,弱相关权重,域引导丢失等- 相应层中的权重不是共享的,而是由权重正则化因子$r_w(\cdot)$相关联以解释相应层之间的差异。
损失函数,则为:
其中,$\theta_j^s,\theta_j^t$是第j层源、目标域的参数
放宽限制后,使得其中一个做线性变换:
使用弱参数共享层。 惩罚项Ω控制参数的相关性
其中,$\{W_S^{(l)},b_S^{(l)}\}_{l=1}^L,\{W_T^{(l)},b_T^{(l)}\}_{l=1}^L$是第l层的源域和目标域
BN:规范化每个单独特征通道的平均值和标准偏差,使得每个层从类似分布接收数据,而不管它是来自源域还是目标域
其中,$\mu(x),\sigma(x)$是每个特征通道独立计算的平均值和标准差。
- 相应层中的权重不是共享的,而是由权重正则化因子$r_w(\cdot)$相关联以解释相应层之间的差异。
几何标准geometric criterion
该标准假设几何结构的关系可以减少域移位
GAN由两个模型组成:提取数据分布的生成模型G和通过预测二进制标签来区分样本是来自G还是训练数据集的判别模型D. 网络同时优化G以最小化损失,同时还训练D以最大化分配正确标签的概率:
伪代码
Algorithm: Fine-tune
- 初始化为预先训练的模型
- 重新构造最后一层,使它的输出数与新数据集中的类数相同
- 选择需要更新的参数以此来优化算法
- 开始训练
注:可以见BaseLine:ResNet50,在那里复现的时候,有用到Fine-tune
DaNN:Domain Adaptive Neural Networks—20145
核心贡献
DaNN虽然是一个简单的神经网络(只有一个隐藏层),来处理对象识别中的域适应问题。 但它的提出了非参数概率分布距离度量,即MMD(maximum mean discrpancy)度量作为监督学习中的正则化,作为样本差异性,以减少潜在空间中源域和目标域之间的分布不匹配。 之后的许多研究都在遵循这一想法,将MMD或其他测量(例如CORAL损失,Wasserstein距离)嵌入到更深层(例如AlexNet,ResNet)网络中。
核心内容
DaNN 的方法可以用于 无监督迁移学习中,因此训练中只有源域参加。,DaNN 的最终目的是为了使得训练出的网络学习到 source 和 target 的不变式(公用)特征,使得网络能够应用在 target 数据上。
仅有两层神经网络元组成:特征层和分类器层。创新之处在于:在特征层后加入了一项MMD适配层,用来计算源域和目标域的距离,并将其加入网络的损失中进行训练。因此,整个网络的目标也相应地由两部分构成:在有label的源域数据上的分类误差$l_C$以及对两个领域数据的判别误差$l_d$(和两个领域的距离有关),可以表示为:
很显然的由于网络层数太少,表征能力有限,精度不高。
这里来详细探究一下MMD:
MMD 的本质是在通过样本来计算两个分布之间的差异性大小。将 MMD 用于迁移学习想法早就有之,例如TCA。MMD 计算方法为:将来源于两个分布的样本投射入相同的空间,然后计算它们的均值差值。通过平方+开根的 trick 可以将 MMD 的计算变为一个核方法计算,DaNN 中采取的核为高斯核。
首先在$X$上有两个可能性分布$p,q$,这样MMD被定义为:
其中,$\zeta$是$f:X\to R$的一个类别。再生核希尔伯特空间(RKHS)中单位球的函数集,用H表示。通过$MMD(F,p,q)= 0$,以此可以检测p和q之间的差异。
在这个问题中,可以表示为:
其中,$\Phi(\cdot):X\to H$是关于特征空间映射的函数
其中$[K_{x*}]_{ij}=k(x_^{(i)},x_*^{(j)})$是所有在数据空间中的可能的核组成的Gram矩阵。
Gram(格雷姆)矩阵:由n维欧式空间中任意$k(k\leq n)$个向量$\alpha_1,\alpha_2,\cdots \alpha_k$的内积所组成的矩阵
格拉姆矩阵可以看做特征之间的偏心协方差矩阵(即没有减去均值的协方差矩阵)。在feature map中,每个数字都来自于一个特定滤波器在特定位置的卷积,因此每个数字代表一个特征的强度,而Gram计算的实际上是两两特征之间的相关性,哪两个特征是同时出现的,哪两个是此消彼长的等等,同时,Gram的对角线元素,还体现了每个特征在图像中出现的量,因此,Gram有助于把握整个图像的大体风格。有了表示风格的Gram Matrix,要度量两个图像风格的差异,只需比较他们Gram Matrix的差异即可。
FFNN:Feed Forward Neural Network前馈神经网络
标准的FFNN有三种类型的层:输入$x\in \R^{n_x}$、隐藏$h\in \R^{n_h}$和输出$o\in \R^{n_o}$;则有:
其中softplus函数$\sigma_1(u)_j=log(1+exp)u_j$和softmax函数$\sigma_2(v)_l=\frac {exp(v_l)}{\sum_k exp(v_k)}$;其中,$u\in\R^{n_h},v\in\R^{n_o}$
最大似然损失函数则为:
通过后向传播来最小化损失函数
DAE:Denoising Auto-encoder去噪自动编码器
自动编码器是通过损失函数重建其输入,来用于学习有效编码的无监督神经网络。而DAE,是在给定噪声对应物的情况下通过重建干净输入来捕获强大的表示零掩蔽、高斯以及椒盐噪声几种噪声类型来表征滤波器
DaNN:Domain Adaptive Neural Network
那么如何通过神经网络量化出两个分布的样本差异性呢? 作者的方法非常 naive,将 source 和 target 的数据分别传入网络,然后将第一层(表征层)的网络输出结果输入,作为 MMD 的输入计算样本的差异性。
DaNN 为了将 MMD 产生的 loss 传入网络,训练方式分为两步:
- 先是和常规训练方式一样,利用 mini-batch GD 传递任务(e.g. 分类)的 loss 更新参数。
- 然后用表征层分别计算 source 和 domain 样本的 MMD loss,然后再次更新参数。
DaNN是DNN的变体,加入了MMD测量,因此损失函数变为:
要最小化损失函数,可以先对其进行求导,等式的前者的导数的值很小,可以用小批量随机梯度下降的方法来更新$U_1$;后者的求导和所选择k的值有关,用完全批量梯度下降法。如果我们选择高斯核,则$K_G(x,y)=exp(-\frac{|x-y|^2}{2s^2})$。同时改写$MMD^2_e(\cdot,\cdot)$为矩阵向量的形式。先将参数改写为矩阵的形式:$\tilde {X_s}^{(i)}=\left[\begin{matrix}1\\X_s^{(i)}\end{matrix}\right]\in \R^{(d+1)}, \forall i=1,\cdots,n_s,\ \tilde {X_t}^{(j)}=\left[\begin{matrix}1\\X_s^{(j)}\end{matrix}\right]\in \R^{(d+1)}, \forall j=1,\cdots,n_t$,参数矩阵$U_1\left[\begin{matrix}b^T\\W_1\end{matrix}\right]\in R^{(d+1)\times k},\ U_2\left[\begin{matrix}c^T\\W_2\end{matrix}\right]\in R^{(k+1)\times l}$。
这样,$MMD^2_e(\cdot,\cdot)$表示为:
让$G_{*}(i,j)=-\frac 1 {s^2}K_G(x_^{(i)},x_^{(j)})(x_^{(i)}-x_^{(j)})(x_^{(i)}-x_*^{(j)})^TU_1$,则有
SURF:Speeded Up Robust Features加速稳健特征。步骤如下:
- 特征提取
- 构建尺度空间
- 特征点定位
- 特征点主方向分配
- 生成特征点描述子特征点匹配
这里运用SURF来获取图片特征:
- 利用调整大小和灰度图像上的SURF描述符来检测图像特征,以检测局部尺度不变的兴趣点;
- 使用从亚马逊图像的子集训练的码本将数据点编码成800个桶的直方图
- 对最终特征进行归一化和z-评分,得到零均值和单位方差。
伪代码
Algorithm: DaNN
输入:权重向量$U_1\in\R^{(d+1,)k},U_2\in\R^{(k+1,)l}$,$h\in\R^k$隐藏层向量,$o\in\R^l$输出层向量,$\alpha$学习率,$\gamma$MMD的正则常数
begin
1.用随机小实数初始化$U_1,U_2$
2.用标准向前、向后传播的批量随机梯度下降法分别来更新$U_2$和$U_1$
3.通过离线梯度下降法来更新$U_1$
4.重复2、3步
end
baseline:数字迁移使用网络—201510
根据上一标题《Self-Ensembling for Visual Domain Adaptation》的附录D所提及的网络
核心内容
作者给出了网络结构的数据,我挑选了其中相对来说简短的MNIST<->USPS architecture
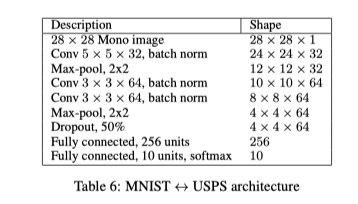
先是输入;然后一个卷积一个池化;然后两个卷积一个池化;再一个Dropout;最后两个全联接。
复现
即,根据上面的结构,进行编写。
大概结构编写如下:
|
|
解析一下上面所用到的函数:
torch.nn.Conv2d(in_channerls, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)二维卷积层, 输入的尺度是,输出尺度的计算方式:参数:
in_channels(int) - 输入信号的通道$(N, C_{in},H,W_{in})$out_channels(int) - 卷积产生的通道$(N,C_{out},H_{out},W_{out})$kerner_size(int or tuple) - 卷积核的尺寸stride(int or tuple, optional) - 控制相关系数的计算步长padding(int or tuple, optional) - 输入的每一条边补充0的层数dilation(int or tuple, optional) - 用于控制内核点之间的距离groups- 控制输入和输出之间的阻塞连接数:group=1,输出是所有的输入的卷积group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,并且产生的输出是输出通道的一半,随后将这两个输出连接起来变量:
weight(tensor) - 卷积的权重,大小是:(out_channels, in_channels,kernel_size)bias(tensor) - 卷积的偏置系数,大小是:(out_channel)torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)对于输入信号$(N, C_{in},W_{in})$,提供2维最大池化max pooling操作
输出:$(N,C_{out},H_{out},W_{out})$
参数:
kerner_size(int or tuple) - max pooling的窗口大小stride(int or tuple, optional) - max pooling的窗口移动步长,默认为kernel_sizepadding(int or tuple, optional) - 输入的每一条边补充0的层数dilation(int or tuple, optional) - 用于控制窗口中元素步幅的参数return_indices- 如果等于True,会返回输出最大值的序号,对采样有帮助ceil_mode- 如果等于True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True)对小批量(mini-batch)3d数据组成的4d输入进行批标准化(Batch Normalization)操作
输入输出大小相同。
参数:
num_features- 期望输入的特征数,大小为(batch_size x num_features x height x width)eps- 为保证数值稳定性(分母不能趋近或取0),给分母加上的值,默认为1e-5momentum- 动态均值和动态方差所使用的动量。默认为0.1。affine- 一个布尔值,当设为true,给该层添加可学习的仿射变换参数torch.nn.functional.dropout(input, p=0.5, training=True, inplace=False)
在训练期间,使用伯努利分布的样本以概率p随机地将输入张量的一些元素归零。参数:
p- 元素归零的概率,默认值:0.5training- 如果为True,则应用dropout。 默认值:Trueinplace- 如果设置为True,将就地执行此操作。 默认值:Falsetorch.nn.Linear(in_features, out_features, bias=True)
对输入数据应用线性变换:$y=xA^T+b$输入数据大小:$(N, in_{features},H_{in})$
输出数据大小:$(N, out_{features},H_{out})$
in_features- 输入数据特征数out_features- 输出数据特征数bias- 如果设置为False,则图层不会学习附加偏差,默认值:True
变量:Linear.weight权重,大小为(out_features, infeatures)。值初始化为$\mu(-\sqrt k,\sqrt k)$,其中,$k=\frac 1 {in_features}$Linear.bias偏差,大小为(out_features)。如果偏差为True,则初始化为,其中,$\mu(-\sqrt k,\sqrt k)$,其中,$k=\frac 1 {in_features}$
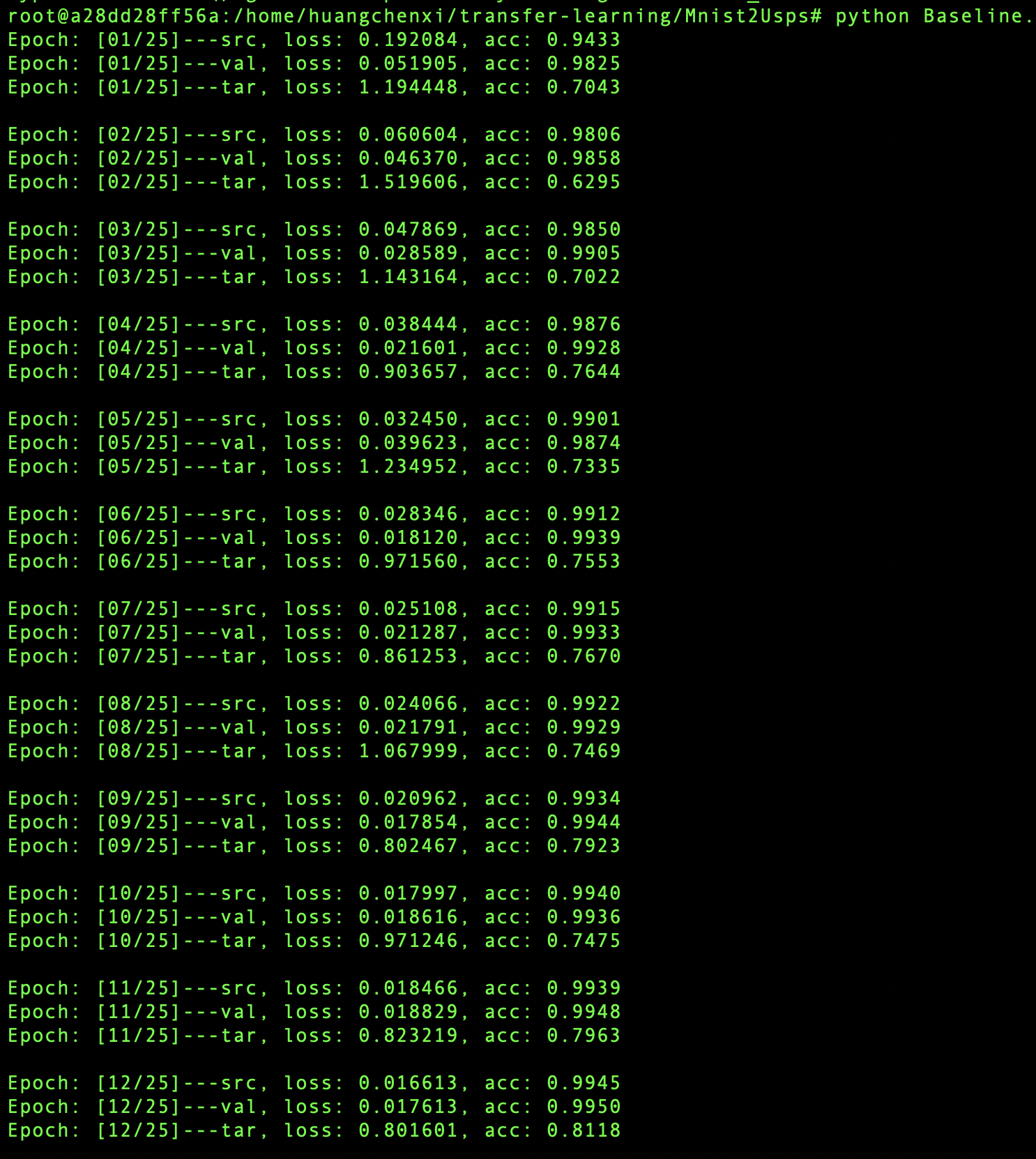
部分结果如下:
Domain Adversarial Training of Neural Networks—201617
核心贡献
利用GAN的思想来实现的。将域适应嵌入到深度特征学习过程中,使得所获得的前馈网络可以适用于目标域而不受两个域之间转换所带来的阻碍。虽然也是通过对齐特征分布来实现的,但是是通过标准反向传播训练完成对准。DANN背后的主要思想是禁止网络隐藏层去学习来预测源示例标签的表示。且该方法不仅适用于分类任务,几乎可以在任何通过反向传播训练的现有前馈架构创建DANN版本,例如用于人员重新识别的描述符学习。
核心内容
也是通过对齐特征分布来实现的。域对抗性神经网络(DANN) 框架由feature extractor、label predictor和domain classifier(标签预测器,域分类器和特征提取器)三个部分组成,并且在特征提取器和域分类器之间有一个梯度反转层(使其在前向传播中使输入保持不变,并且在反向传播中乘以负标量来反转梯度)。
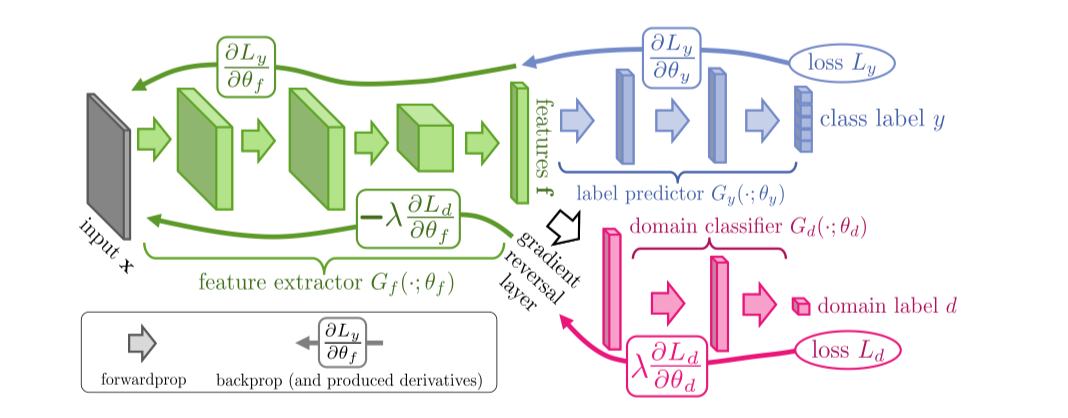
该网络由共享特征提取层和两个分类器组成(一个是标记预测器,用于预测类标签并在训练和测试时使用;另一个是域分类器用于训练时区分源和目标域)。 DANN最小化域混淆损失(对于所有样本,通过使用GRL)和标签预测损失(对于源样本)。其专注于学习结合判别性和域不变性的特征。
优化特征映射参数的目的是为了最小化label classifier的损失函数,最大化domain classifier的损失函数,前者是为了提取出具有区分能力的特征,后者是为了提取出具有领域不变性的特征。因此 模型最后的分类决策是既有区分力又对领域变换具有不变性特征的。
Definition 1
DANN直接优化了H-divergence的概念。
其中,$H$是一个假设类,$D_S^X,D_T^X$上的两个域分布。
根据经验的H-divergence:
其中,$I[a]$是指标函数,如果a为真,则为1,否则为0;$N = n + n_0$是样本的总数
作者的想法,主要参考Ben-Davaid et al.(2006,2010),即H-divergence的上界受其经验估计加上恒定复杂度项的依赖,该复杂项依赖于H的VC维数和大小。 样本S和T通过将该结果与源风险的类似界限相结合,得到以下定理。
Theorem 2:设$H$是$VC$维$d$的假设类。 X对于每个$η∈H$,在样本$S\sim(D_S)^n$和$T\sim(D_T^x)^n$的选择上概率为$1-δ$:
正如Ben-David等人所指出的那样。 (2006),控制H-发散的策略是找到示例的表示,其中源域和目标域尽可能无法区分。 根据这种表示,根据定理2,具有低源风险的假设将在目标数据上表现良好。 在本文中,我们提出了一种直接利用这一思想的算法。正如Ben-David等人所指出的那样,控制H-divergence的策略是找到样本表示,其中源域和目标域尽可能无法区分。 根据这种表示,具有低源风险的假设将在目标数据上表现良好。 在本文中,我们提出了一种直接利用这一思想的算法。
Proxy Distance
源域和目标域构成一个新的数据集,源域的标记为0,目标域的标记为1
这样式子(2)为:
$\hat d_\mathcal{A}$也被称为PAD(proxy A-distance)。A-distance被定义为$d_\mathcal{A}(D_S^x,D_T^x)=2\text{sup}_{A\in \mathcal{A}}|\text{Pr}_{\mathcal{D}_S^X}(A)-\text{Pr}_{\mathcal{D}_T^X}|$,其中$\mathcal{A}$是$X$的子集,$A=\{A_\eta|\eta\in \mathcal{H}\}$。
With shallow NN
首先考虑只有一层隐藏层的网络,我们假设输入空间是m维实向量,即$X=\R^m$。现在我们所要做的就是让隐藏层$G_f$去学习一个函数:$G_f:X\to\R^D$。这样就有一个未知矩阵向量$(W,b)\in\R^{D\times m}\times \R^D$:
同样的,预测层$G_y$需要学习一个函数:$G_y:R^D\to[0,1]^L$,未知参数为$(V,c)\in\R^{L\times D}\times\R^L$
其中,$L=|Y|$。通过softmax函数,$G_y(G_f(x))$的每个向量表示神经网络将$x$分配给由该分量表示的$Y$中类的条件概率。
给定一个源示例$(x_i,y_i)$,自然分类损失是正确标签的负对数概率:
训练神经网络然后产生源域上的优化问题:
其中,$R(W,b)$是可选的超参数λ加权的正则化选项。
我们把隐藏层的输出$G_f(\cdot)$当作神经网络的内部表示,因此我们把源域和目标域表示为:
则式(2)为:
受Proxy A-dsitance的启发,通过域分类层$G_d$估计式子(15)的“min”部分,该分类层(适应层)学习逻辑回归$G_d:\R^D\to[0,1]$,未知参数通过矢量标量对$(u,z)\in\R^D\times\R$表示,模拟给定输入来自源域$D_S^X$或目标域$D_T^X$的概率。 因此有:
这里的$G_d(\cdot)$是域回归器,定义loss为:
其中,$d_i$表示是否是目标域的数据(用0,1表示)
式子(11)改写为:
该正则化器试图近似式子(15)的H-散度,因为$2(1-R(W,b))$是$\hat d_\mathcal{H}(S(G_f),T(G_f))$的替代。 根据定理2,式子(11)和(18)给出的优化问题实现了源风险$R_S(\cdot)$和分歧$\hat d_H(·,·)$之间的权衡。 超参数$\lambda$用于在学习过程中调整这两个量之间的权衡。
我们继续改写式子(11):
对于$\hat W,\hat V, \hat b,\hat c,\hat u,\hat z$可以通过鞍点得到:
伪代码
Algorithm: Shallow DANN – Stochastic随机 training update
输入:
- 样例$S=\{(x_i,y_i)\}_{i=1}^n,T=\{x_i\}_{i=1}^{n’}$
- 隐藏层大小$D$
- 适应层参数$\lambda$
- 学习率$\mu$
输出:神经网络$\{W,V,b,c\}$
$W,V\leftarrow \text{random_init}(D)$
$b,c,u,d\leftarrow 0$
while stopping criterion is not met do
for i from 1 to n do
// 前向传播
$G_f(x_i)\leftarrow sigm(b+Wx_i)$
$G_y(G_f(x_i))\leftarrow softmax(VG_f(x_i)+c)$
// 后向传播
$\Delta_c\leftarrow (e(y_i)-G_y(G_f(x_i)))$
$\Delta_V\leftarrow \Delta_cG_f(x_i)^T$
$\Delta_b\leftarrow(V^T\Delta_c)\odot G_f(x_i)\odot(1-G_f(x_i))$
$\Delta W\leftarrow \Delta_b\cdot(x_i)^T$
// 域适应正则化
//从当前域
$G_d(G_f(x_i))\leftarrow sigm(d+u^TG_f(x_i))$
$\Delta_d\leftarrow\lambda(1-G_d(G_f(x_i)))$
$\Delta_u\leftarrow\lambda(1-G_d(G_f(x_i)))G_f(x_i)$
$\text{tmp}\leftarrow\lambda(1-G_d(G_f(x_i)))\times u\odot G_f(x_i)\odot (1-G_f(x_i))$
$\Delta_b\leftarrow \Delta_b+tmp$
$\Delta_W\leftarrow W+tmp\cdot(x_i)^T$
//从其他域
$j\leftarrow \text{uniform_integer}(1,\dots , n’)$
$G_f(x_j)\leftarrow sigm(b+Wx_j)$
$G_d(G_f(x_j))\leftarrow sigm(d+u^TG_f(x_j))$
$\Delta_d\leftarrow \Delta_d-\lambda G_d(G_f(x_j))$
$\Delta_u\leftarrow \Delta_u-\lambda G_d(G_f(x_j))G_f(x_j)$
$\text{tmp}\leftarrow-\lambda G_d(G_f(x_j))\times u\odot G_f(x_j)\odot (1-G_f(x_j))$
$\Delta_b\leftarrow \Delta_b+tmp$
$\Delta_W\leftarrow W+tmp\cdot(x_j)^T$
//更新神经网络内部参数
$W\leftarrow W-\mu\Delta_W$
$V\leftarrow V-\mu\Delta_V$
$b\leftarrow b-\mu\Delta_b$
$c\leftarrow c-\mu\Delta_c$
//更新与分类器
$u\leftarrow u-\mu\Delta u$
$d\leftarrow d-\mu\Delta d$
end for
end while
其中,$e(y)$是”one-hot” vector,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。只有当y的时候为1,其余都为0。
在训练过程中,神经网络$(W,b,V,c)$和域回归量$(u,z)$以对抗的方式相互竞争,在公式(20)上衡量。因此,称该网络为域-对抗神经网络(DANN)。 DANN将有效地尝试学习一个隐藏层$G_f(·)$,将一个例子(源或目标)映射到一个表示,允许输出层$G _y(·)$准确地对源样本进行分类,但是削弱了域回归的能力$G_d(·)$(检测每个示例是属于源域还是目标域)。
对架构的推广
可以直接推广到其他复杂的体系结构。
设$G_f(·;θ_f)$为D维神经网络特征提取器,参数为$θ_f$。另外,让$G_y(·;θ_y)$成为计算网络标签预测输出层的DANN的一部分,参数为$θ_y$,而$G_d(·;θ_d)$现在对应于域预测输出的计算网络,参数为$θ_d$。注意,为了保留定理2的理论保证,由域预测分量$G_d$生成的假设类$H_d$应该包括由标签预测分量$G_y$生成的假设类$H_y$。因此,$H_y⊆H_d$。
我们将分别记录预测损失和域丢失:
训练DANN,然后与单层案例平行并且优化:
同样,通过寻找鞍点来定义:
然后,就梯度更新:
其中,$\mu$是学习率。
在数学上,将梯度反转层视为“伪函数”$R(x)$,描述其前向和后向传播行为的两个(不相容)方程定义为:
其中,$I$是单位矩阵。
定义目标“伪函数”$(θ_f,θ_y,θ_d)$,该函数通过随机梯度下降进行优化:
可选优化
最小化第一域$L_{d+}$会使域识别更好,最小化第二域$L_{d-}$当域不同时。随机梯度更新如下:
在该框架中,梯度反转层构成特殊情况,对应于域损耗对$(L_d,-λL_d)$。也可以可以使用其他损失函数对。 一个例子是二项式交叉熵:
其中d表示域索引,q是预测器的输出。 通过交换域标签容易获得“对抗性”损失,即$L_{d-}(q,d)= L_{d+}(q,1-d)$。 如果域非常不同,这一特定对具有在早期学习阶段产生更强梯度的潜在优势。 然而,在实验中,没有观察到由于这种损失选择而导致的任何显着改善。
CNN架构
运用到了四种框架:
- 源域数据集是MNIST,用了LeNet-5的模型
- 对于SVHN数据集,采取了(Srivastava et al., 2014)
- 在
SYN SINGS → GTSRB中,用了single-CNN baseline(Cires¸an et al., 2012) - 对Office域,用了预训练模型AlexNet,适应层架构与(Tzenget al., 2014)相同:2层域分类器
(x→1024→1024→2)附加到fc7的256维瓶颈中。
训练过程
使用0.9动量的随机梯度下降和学习率退火:
其中,p是从0到1线性变化的训练进度,$μ_0= 0.01,\alpha= 10,\beta= 0.75$(优化时间表以促进源域上的收敛和低误差)。
复现
使用的网络的结构:
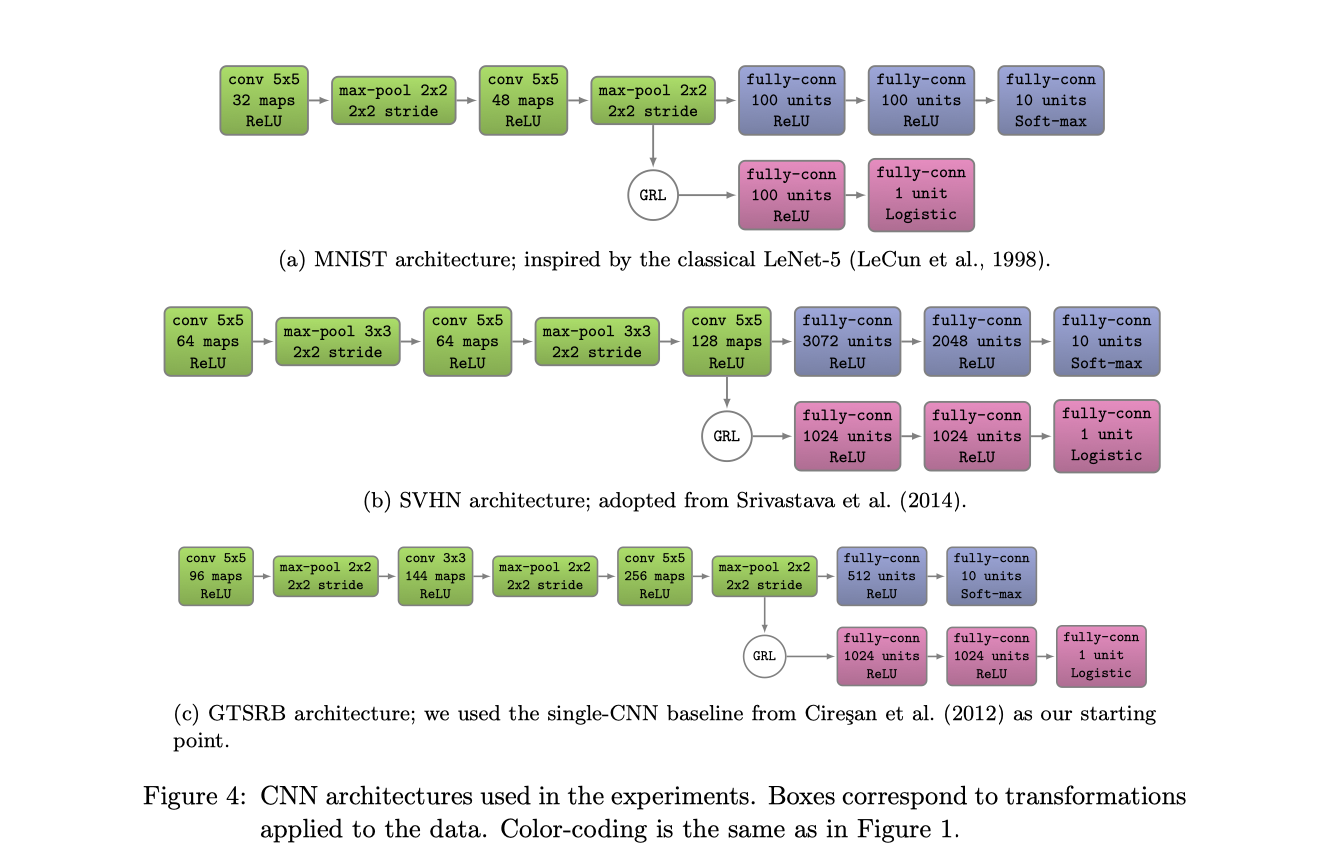
除了MNIST(x->1024->1024->2)外,使用(x->100->2)的结构。其中p是从0到1线性变化的训练进度,$μ_0= 0.01,\alpha= 10,\beta= 0.75$,动量项使用0.9。
转载请注明出处,谢谢。
愿 我是你的小太阳
