操作系统笔记与考前整理
#: 未讲部分
考试题型
进程和线程
- 进程
- 状态转换
- PCB进程控制块
- 线程
- 用户级线程
- 内核级线程
进程间通信IPC
- 竞争条件
- 临界区
- 7种方法
- Mutual Exclusion with Busy Waiting(忙等待的互斥)
- Sleep and Wakeup(休眠与唤醒)
- Semaphores(信号量)
- Mutexes(互斥锁)
- Monitors(管程)
- Message Passing(消息传递)
- Barriers(屏障)
调度算法
- First Come First Serve
- Round robin
- Shorted Job First (nonpreemptive & preemptive )
- Priority Scheduling (nonpreemptive & preemptive )
- Multiple Queues
- 指标:平均周转时间(the mean process turnaround time)
内存管理
- 地址空间
- 地址空间是一个进程可用于寻址内存的一套地址集合,存放可执行的程序、程序的数据和程序的堆栈
- address binding of instructions and data to memory addresses can happened at three different stages, compile time, load time and execution time
- 指令和数据到内存地址的地址绑定可以发生在三个不同的阶段,编译时,加载时和执行时
- 内存过载
- 对换/交换
- 把一个进程完整调入内存,使该进程运行一段时间,然后把它存回磁盘
- 虚拟存储器
- 对换/交换
- 空闲内存管理
- 位图
- 简单,但搜索耗时
- 空闲链表
- First-fit首次适配, next-fit下次适配, worst-fit最差适配, best-fit最佳适配
- 位图
- 虚拟内存
- 每个程序拥有自己的地址空间,这些空间被分割为许多块,每一块叫做一页或页面。每一页有连续的地址范围。这些页被映射到物理内存,但并不是所有的页都必须在内存中才可运行程序。当程序引用到一部分在物理内存中的地址空间时,由OS负责将缺失的部分装入物理内存并重新执行失败的指令
- 虚拟地址空间单元为页面page;物理内存对应单元为页框page frame,两者大小相同;页表page tables记录两者的映射关系
- 若某页面没有被映射,则CPU陷入到操作系统,这个陷阱称为缺页中断。操作系统替换一个页框,并把刚才需要访问的页面换入该页框中,修改映射关系,重新启动引起陷阱的指令
- 虚拟地址和物理地址的映射
- 虚拟地址空间划分,计算页面大小
- 页存储
- 页表
- 页替换算法:缺页次数
- The Optimal Page Replacement Algorithms(最优页面置换算法)
- The NRU(Not Recently Used) Page Replacement Algorithms(最近未使用页面置换算法)
- (访问位R,修改位M)
- The FIFO(First in First Out) Page Replacement Algorithms
- The Second Chance Page Replacement Algorithms
- The Clock Page Replacement Algorithms(时钟页面置换算法)
- The LRU(Least Recently Used) Page Replacement Algorithms(最近最少使用页面置换算法)
- 行置一,列置零
- The Working Set Page Replacement Algorithms(工作集页面置换算法)
- The WSClock Page Replacement Algorithms(工作集时钟页面置换算法)
- 段
文件系统
- 文件
- 普通文件:二进制文件,ASCII文件
- 特殊文件:块特殊文件、字符特殊文件
- 文件属性
- 目录
- Single-level, Two-level, Hierarchical directory systems
- 完全路径/相对路径
- I-node
- 文件系统
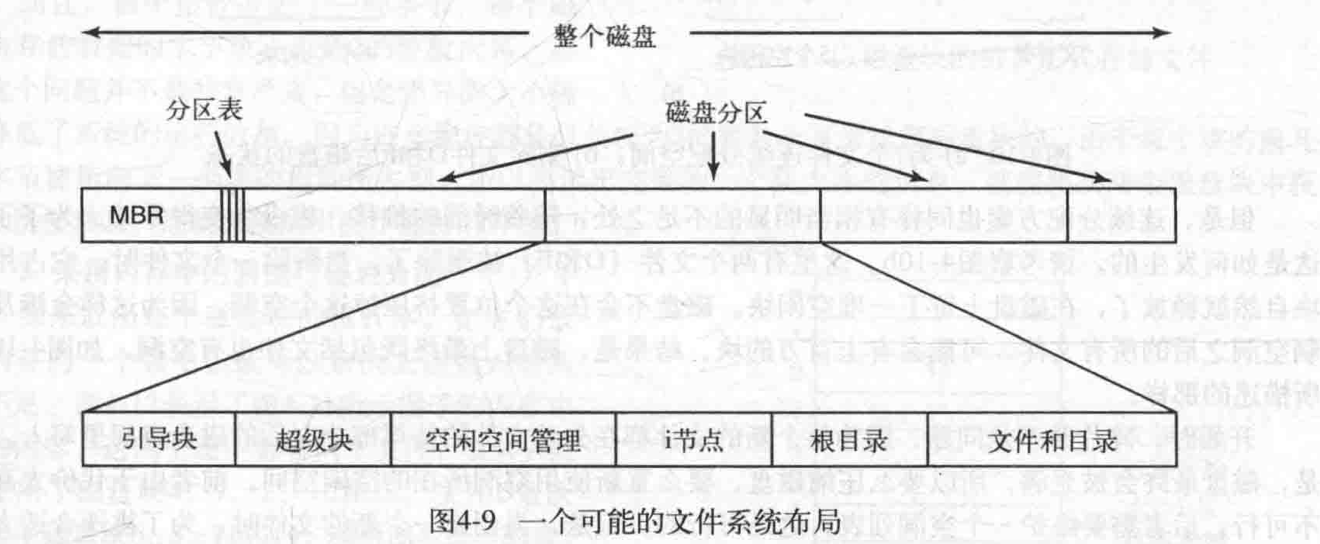
- MBR:磁盘的扇区0称为MBR(主引导记录),MBR的末尾包含分区表(分区表)
- Implementing files
- 顺序结构
- 链表结构(指针)
- 文件分配表FAT(File Allocation Table)【块中存放文件的下一个的地址】
- UNIX/Linux 文件元数据metadata被存储在i-node中
I/O
I/O硬件原理
- 块设备&字符设备
- DMA
I/O软件原理
- 目标
- Device independence(设备独立性)
- Uniform naming(统一命名)
- Error handling
- Synchronous(同步) vs. asynchronous(异步)
- transfers
- Buffering
- Sharable(共享) vs. dedicated(独占) devices
- 三种执行方式
- Programmed I/O
- 让CPU做全部的工作;CPU通过程序主动读取状态寄存器以了解接口情况,并完成相应的数据操作
- Interrupt-driven I/O
- 当程序常规运行时,若外部有优先级更高的事件出现,则通过中断请求通知CPU,CPU再读取状态寄存器确定事件的种类,执行不同的分支处理
- I/O using DMA
- 直接内存存取,即数据传送的具体过程直接由硬件(DMA控制器)在内存和I/O之间完成,CPU只在开始时将控制权暂时交予DMA,直到数据传输结束
- Programmed I/O
- 目标
I/O软件层次

盘
- 寻道时间,旋转延迟,实际数据传输时间
- 磁盘臂调度算法:(指标)磁盘臂移动总量或寻道时间(seek time)
- First Come First Serve(FCFS)
- Shortest Seek First (SSF)
- The elevator algorithm
死锁
资源:可抢占的和不可抢占的
死锁
死锁的概念
四个条件
- Mutual exclusion condition互斥使用
- 假脱机技术spooling
- Hold and wait condition占有且等待
- 资源静态分配(在开始的时候就请求全部资源)
- No preemption condition不可抢占
- 抢占资源
- Circular wait condition循环等待
- 资源有序分配
- Mutual exclusion condition互斥使用
死锁避免
安全状态
银行家算法
The banker’s algorithm considers each request as it occurs, and see if granting it leads to a safe state.
if it does, the request is granted;
otherwise, it is postponed until later.- 给出系统中的资源总数(Total Available or Exist)、最大资源需求(Maximum Needs)、已分配到的资源(Current Allocation),判断系统是否处于safe state
解题步骤
calculate the Need matrix
search a safe order - 某个进程提出新的资源请求,是否应该满足该进程?
先满足该进程的请求
修改Need矩阵
search a safe order
- 给出系统中的资源总数(Total Available or Exist)、最大资源需求(Maximum Needs)、已分配到的资源(Current Allocation),判断系统是否处于safe state
多处理器系统
三种类别
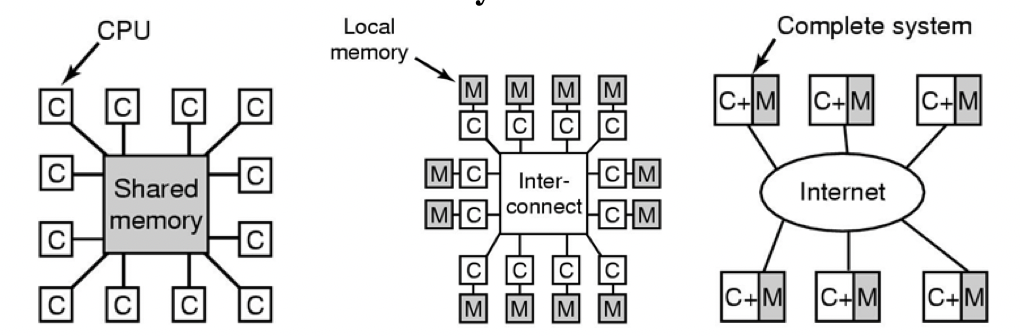
shared-memory multiprocesso内存共享多处理机
分类
Separate OS每个CPU有自己的操作系统
Master-Slave 主从多处理机
Symmetric multiprocessor对称多处理机
并行系统包括对称多处理机和非对称多处理机asymmetric multiprocessor
scheduling调度
- timesharing 分时& space sharing 空间共享& gang scheduling群调度
message-passing multicomputer消息传递多计算机
- interconnect technology
wide-area distributed system广域分布式系统
安全
- 三个安全问题
- 威胁threats
- Data confidentiality
- Data integrity
- System availability – denial of service
- privacy
- 入侵者intruders
- 数据的意外遗失accidental data loss
- 威胁threats
- 保护机制
- 域【(对象,权利)对】
- ACL访问控制列表(每个对象的)
- 权能字(每个进程的)
- 验证Authentication
- 内部攻击
- 利用代码漏洞
- 恶意软件malware
- 防御
UNIX&LINUX常用系统调用
- fork & exec: (2.1.2)
- fork: create two processes, the parent and the child, have the same memory image, the same environment strings and the same open files
- exec: do not create a new process,启动另一个程序来执行,一个进程一旦调用exec类函数,它本身就”死亡”了
- ps: list the running processes(2.1.2)
- cat: concatenates files (2.1.5)
- grep: selects lines containing the given word(2.1.5)
- chmod: to change the mode of a file(1.6.4)
在UNIX/Linux中,每个文件都有一个保护模式。该模式包括针对所有者、组和其他用户的读-写-执行位
r = 4,w = 2,x = 1
要是一个文件对除了所有者之外的用户都是只读的,可以自行命令chmod (filename, 744)
操作系统概述
程序执行流程(Hello world为例)
- 在命令行键入相应的命令 ,启动程序执行
- 操作系统接受用户请求之后,就会根据用户提供的文件名,到磁盘上找到这个程序的相关信息,找到信息之后,会去检查这个程序,是不是一个可执行文件,若不是,报错;
- 操作系统会根据程序首部信息,来确定代码和数据在这个可执行文件当中的位置,并计算出它相应的磁盘块地址
- 为了执行这个helloworld程序,操作系统首先要创建一个新的进程,并将helloworld程序的可执行文件格式,映射到该进程结构 表示由该进程来执行这个helloworld程序,做完了这件事情,操作系统就把控制权,交给了调度程序
- 当调度程序选中了helloworld程序,当执行第一条指令的时候,发生缺页异常,硬件机制就会捕获出缺页异常,并且把控制权交给操作系统
- 操作系统管理了计算机系统中的内存,(以页式存储管理方案为例)内存就有很多的物理页面,操作系统的内存管理模块,就会分配一页空闲的物理内存,并且根据前面计算出的磁盘块地址,把helloworld程序的代码从磁盘读入内存。继续执行helloworld程序,有的时候程序很大,一页内存还不够,因此在这个执行过程中会多次地产生缺页异常。然后去到磁盘读入程序到内存,这个过程会有多次
- helloworld程序执行puts函数 那么puts函数的作用,是在标准的输出设备上显示字符串,那么这个标准输出设备,通常就是我们的显示器或者说屏幕,它实际上呢是一个系统调用 是由操作系统来完成这个功能 所以控制权又转回到操作系统。操作系统找到要将字符串送到哪一个显示设备,那么通常设备是由一个进程控制的,所以操作系统把要写的字符串实际上是送给了这个进程,那么控制设备的进程,会告诉设备的窗口系统,它要显示字符串,窗口系统确定这是一个合法的操作,然后将字符串转换为像素,把像素写入设备的存储映像区,视频硬件将像素,转换成显示器可以接收的一组控制信号或数据信号,显示器再去解释这个信号,激发液晶屏
操作系统概念
是一个系统软件,是一些程序模块的集合
计算机系统由硬件和软件(系统程序+应用程序)组成
操作系统是控制计算机整体操作的软件
是介于用户和计算机硬件之间的程序;其目的是为了让用户方便执行程序,提高易用性,更高效地操作硬件
- 以尽量有效、合理的方式组织和管理计算机的软硬件资源
- 有效:系统效率、资源利用率
- 合理:软硬件资源的公平合理
- 合理地组织计算机的工作流程,控制程序的执行,并向用户提供各种服务功能
- 使用户能够灵活、方便地使用计算机,使整个计算机系统高效率运行
- 方便:用户界面与编程接口
系统接口或shell =用户和计算机之间的接口
- 命令行界面(CLI)
Linux,UNIX,DOS,旧操作系统 - 图形用户界面(GUI)
操作系统的作用
操作系统是资源的管理者,对硬件系统的扩展,为用户提供服务
操作系统是资源的管理者:
- 硬件:CPU、内存、设备
- 软件:文件
- 五大基本功能:
- 进程/线程管理(CPU管理)
- 进程线程状态、控制、同步互斥、通信、调度
- 存储管理
- 分配/回收、地址转换、存储保护、内存扩充
- 文件管理
- 文件目录、文件操作、磁盘空间、文件存取控制
- 设备管理
- 设备驱动、分配回收、缓冲技术
- 用户接口
- 系统命令、编程接口
- 进程/线程管理(CPU管理)
操作系统为用户提供服务
操作系统是对硬件系统的扩展
操作系统的特征
并发性、共享性、虚拟性、不确定性
- 并发
- 并发的关键是你有处理多个任务的能力,不一定要同时。
- 并发性是指若干程序在同一时间间隔内执行
- 与并行相似,并行多指不同程序同时在多个硬件部件上执行
- 并发环境:一段时间间隔内,单处理器上有两个或两个以上的程序同时处于开始运行但尚未结束的状态,并且次序不是事先确定的
- 共享
- 虚拟
- 一个物理实体映射为若干个对应的逻辑实体——分时或分空间
- 可以提高资源利用率
- 随机(对不可预测的次序发生的事件进行响应并处理
操作系统的架构
- 用户态
- 内核态
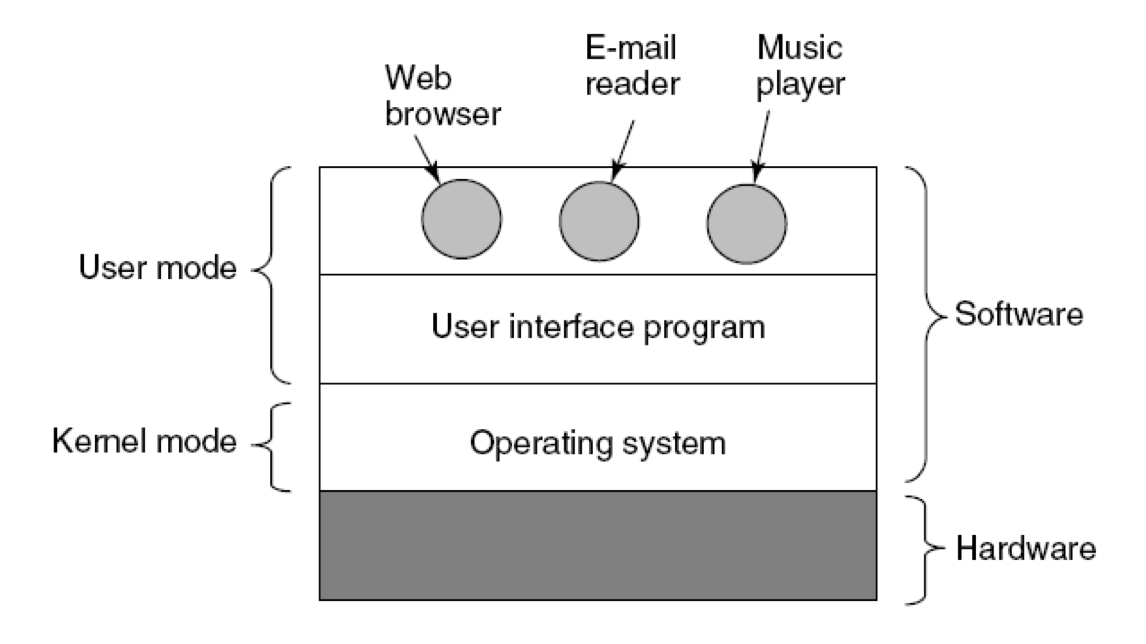
操作系统的分类
- 批处理操作系统
- 提高资源利用率,提高吞吐量
- 单道批处理操作系统,一个一个完成
- 多道批处理操作系统
- spooling技术,假脱机技术,用磁盘作缓冲,将输入、计算、输出分别组织成独立的任务流,在一台计算机上运行【现代打印机还用这个技术】不需要独占设备
- SPOOLing技术是一种用磁盘空间换取时间的技术
- 作业的输入输出工作通常由SPOOLing系统完成
- 批处理系统常采用SPOOLing技术实现
- 分时操作系统(交互式系统)
- 操作系统以时间片为单位,轮流为每个终端用户服务,每次服务一个时间片
- 两者结合时,前台用分时,后台用批处理
- 实时操作系统
- 及时响应外部事件的请求
- 对外部请求在严格时间范围内作出响应
- 高可靠性
- 硬实时系统/软实时系统
- 个人计算机操作系统
- 界面友好,方便使用
- 网络操作系统
- 分布式操作系统
- 分布式系统是指把多个处理机通过线路互联而构成的系统,此系统的处理和控制分布在各个处理机上
- 主要特点:分布性,自治性,模块性,并行性
- 处理分布在不同计算机上
- 处理能力增加,速度变快等等
- 功能:进程迁移,分布式进程同步,任务分配,资源管理
- 嵌入式操作系统
- 反应式或对处理时间有较严格要求的环境中
- 汽车电子系统
运行环境和运行机制
运行环境
CPU状态
中央处理器(CPU)
CPU由运算器、控制器、一系列的寄存器以及高速缓存构成
运行机制
中断/异常
CPU暂停正在执行的程序,保留现场后自动转去执行相应事件的处理程序,处理完成后返回断点,继续执行被打断的程序
中断:为了支持CPU和设备之间的并行操作(外部的打扰
- I/O中断(eg.ctrl+c)
- 时钟中断(eg.时间片用完了)
- 硬件故障
异常:表示CPU执行指令时本身出现的问题
分为三类:Trap陷入(有意识安排、故障Fault(可恢复的错误、终止Abort(不可恢复的错误
种类:
系统调用:特殊的异常
操作系统的主要功能是为应用程序的运行创建良好的环境,为了达到这个目的,内核提供一系列具备预定功能的多内核函数,通过一组称为系统调用的接口呈现给用户。系统调用把应用程序的请求传给内核,调用相应的内核函数完成所需的处理,将处理结果返回给应用程序。如果没有系统调用和内核函数,用户将不能编写大型应用程序
- 使CPU状态从用户态陷入内核态
- 系统调用时调用程序位于用户态,被调用程序位于内核态
- 应用程序可以直接调用系统调用,但一般通过库函数/API接口进行系统调用(存在一些库函数/API接口不执行系统调用,而是完成一些特定的功能);内核函数一部分可以用来系统调用,还有一大部分是隐藏的,没有给编程人员提供外部接口
- 有用于进程管理,文件管理,目录管理的系统调用
页故障/页错误
保护性异常
断点指令
其他程序性异常
硬件——响应
- 捕获中断源发出的中断/异常请求
- 以一定的方式响应
- 将处理器控制权交给特定的处理程序
软件——程序处理
- 识别中断/异常类型并完成相应的处理
中断向量表
存放中断处理程序入口地址和程序运行时所需的处理机状态字
中断流程:(以I/O中断为例)
给CPU发中断信号
CPU处理完当前指令后检测到中断,判断中断来源并向相关设备发确认信号
CPU开始为软件处理中断做准备
- 处理器状态被切换到内核态
- 在系统栈中保存被中断程序的重要上下文环境,主要是程序计数器PC、程序状态字PSW
CPU根据中断码查中断向量表,获得与该中断相关的处理程序的入口地址(这一段具体过程见注),并将PC设置成该地址,新的指令周期开始时,CPU控制转移到中断处理程序(硬件)
中断处理程序开始工作(软件)
- 在系统栈中保存现场信息
- 检查I/O设备的状态信息,操纵I/O设备或者在设备和内存之间传送数据等等
若执行失败,会多次执行,看是否是偶然错误
中断处理结束,CPU检测到中断返回指令,从系统栈中恢复被中断程序的上下文环境,CPU状态恢复成原来的状态,PSW和PC恢复成中断前的值,CPU开始一个新的指令周期
注 中断向量号+IDTR ->(在IDT)中查找中断描述符(得到段选择符和偏移量) -> 段选择符 + GDTR -> (在GDT)中查找段描述符,得到段基址 -> 段基址+偏移量(在内存)中找到中断处理程序【其中R是register寄存器的缩写】
补:R0特权级最高,R3用户级
Quiz2 错题
11题应该选择456


- 系统调用的功能是由内核函数实现的。正确。
进程/线程
进程的两个基本属性:
- 资源的拥有者:进程还是资源的拥有者
- CPU调度单位:线程继承了这一属性
多道程序设计
允许多个程序同时进入内存并运行,目的是为了提高系统效率
进程
进程具有并发性、动态性、独立性(资源分配的独立单元)、交互性、异步性
具有独立功能的程序关于某个数据集合上的一次运行活动,是系统进行资源分配和调度的独立单位
包括程序计数器,寄存器和变量的当前值
进程有数据段、程序段和PCB组成
注:
- 一个程序运行两次就是两个进程
- 系统资源以进程为单位分配,每个具有独立的地址空间
- 查看系统正在运行的程序
PS
进程的管理
PCB:进程控制块,是一个数据结构;通常被装载在RAM中
分为PROC结构和USER结构
包含有:
- 进程描述信息
- 进程标识符(process ID)唯一的,通常是一个整数
- 进程名,不唯一
- 用户标识符(user ID)
- 进程组关系
- 进程控制信息
- 当前状态
- 优先级
- 代码执行入口地址
- 程序的磁盘地址
- 运行统计信息(执行时间、页面调度)
- 进程间同步和通信
- 进程的队列指针
- 进程的消息队列指针
- 所拥有的资源和使用情况
- 虚拟地址空间的状况
- 打开文件列表
- CPU现场信息(当进程不运行的时候,操作系统需要保存)
- 寄存器值
- 指向该进程页表的指针
注:
进程与PCB一一对应
进程表:所有进程的PCB集合
进程的状态
三/五/七状态模型
- 运行态:该时刻进程实际占用CPU
- 运行态
->就绪态:用完了时间片/高优先级进程进入就绪态 - 运行态
->等待态:请求OS服务/资源访问尚不能进行/等待I/O结果/等待另一个进程提供信息/……
- 运行态
- 就绪态:可运行,但因为其他进程正在运行而暂时停止
- 就绪态
->运行态:调度程序选择一个新的进程运行
- 就绪态
- 等待态/阻塞态/封锁态/睡眠态:除非某种外部事件发生,否则进程不能运行
- 等待态
->就绪态:所等待的事件发生了
- 等待态
- 其他状态
- 创建(资源有限,未同意执行该进程)
- 终止
- 挂起:调节负载,不占用内存空间(阻塞挂起/就绪挂起)
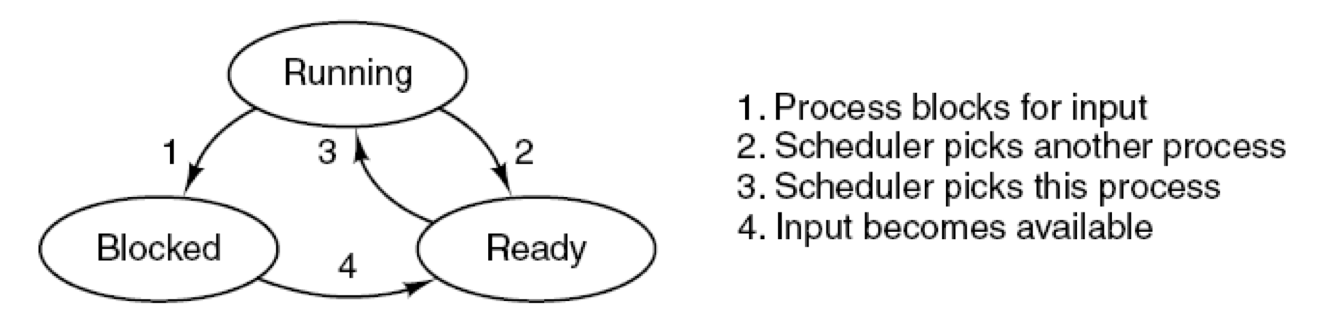
1:是由于I/O请求引起
2:时间片用完引起
3:由于调度程序的调度引起
4:由于I/O完成引起
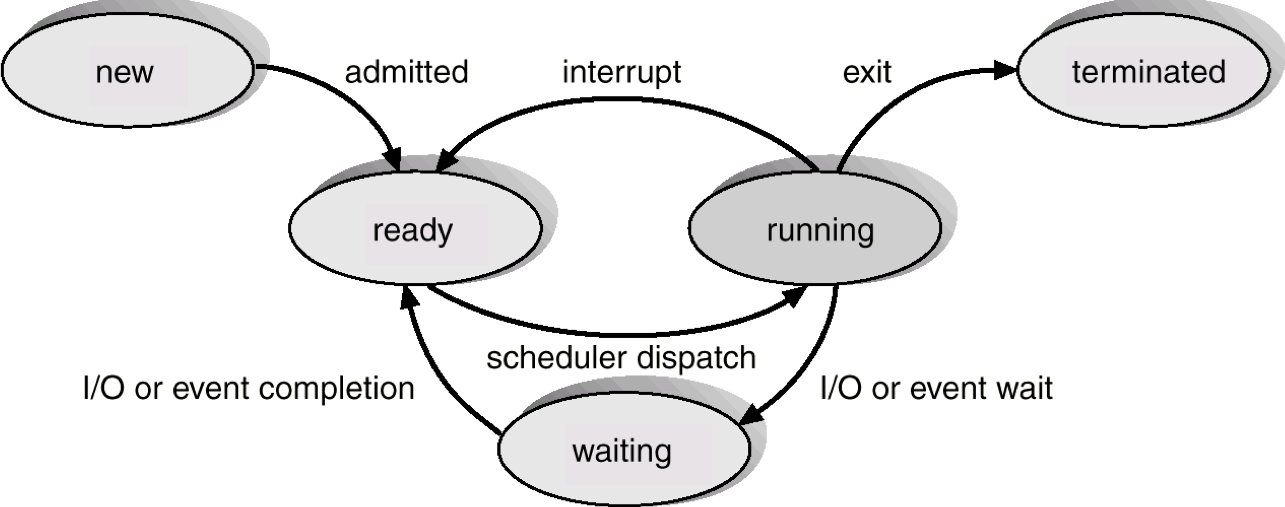
进程的创建:
- 系统初始化
- 正在运行的程序执行了创建进程的系统调用
- 用户请求创建一个新进程
- 一个批处理作业的初始化
进程的终止:
- 正常退出(自愿的)
- 出错退出(自愿的)
- 严重错误(非自愿)
- 被其他进程杀死(非自愿)
进程队列:为每一类进程创建一个或多个队列,队列元素PCB
单CPU下,运行队列中只有一个进程
就绪/等待队列可以有多个
进程控制
不允许中断(因此称为原语),以系统调用作为接口给用户使用
- 进程的创建
fork()【通过复制进程,例如在创建子进程的时候】andexec()【用一段新的程序代码覆盖原来的空间,执行代码的转换】- 给新进程分配一个唯一标识以及进程控制块
- 为进程分配地址空间
- 初始化进程控制块
- 设置相应的队列指针
- 创建进程的事件
- 系统初始化
- 执行创建进程的系统的调用
- 用户请求创建新进程
- 初始化一个批处理作业
- 进程的撤销
exit()- 收回进程所占有的资源
- 撤销该进程的PCB
- 进程阻塞(由进程自己执行阻塞原语
wait()) - 进程的结束
- Normal exit (voluntary(自愿的))
- Error exit (voluntary)
- Fatal error (involuntary(非自愿的))
- Killed by another process (involuntary)
fork()
进程执行是先父进程开始按照代码结构完整执行一遍,其余结点按照前序遍历进程树来从它生成的代码处,执行剩下的代码。(可以见文件夹中的fork_.c测试文件)
- 为子进程分配一个空闲的进程描述符(proc结构)
- 分配给子进程唯一标识pid
- 以一次一页的方式复制父进程地址空间
- 从父进程处继承共享资源,如打开的文件和工作目录等
- 将子进程的状态设为就绪,插入到就绪队列
- 对子进程返回标识符0,但是父进程的标识符还是没有改变
- 向父进程返回子进程的pid
进程的分类
- 系统进程
- 用户进程
- 前台进程
- 后台进程
- CPU密集型进程
- I/O密集型进程
- 一般的调度程序,会先进行I/O密集型进程,占用短时CPU之后,就释放,开始进行I/O操作
- 可抢占式
- 当有比正在运行的进程优先级更高的进程就绪时,系统可强行剥夺正在运行进程的CPU,提供给具有更高优先级的进程使用
- 不可抢占式
- 某一进程被调度运行后,除非由于它自身的原因不能运行,否则一直运行下去
进程的层次结构,进程家族树,init为根
进程和程序
进程是程序的一次执行
- 进程更能准确刻画并发,而程序不能
- 程序是静态的,进程是动态的
- 进程是有生命周期的,有诞生有消亡,是短暂的;而程序是相对长久的
- 一个程序可对应多个进程
- 进程具有创建其他进程的功能
注:
进程之间的地址空间是隔离的,他们的内存地址不是实际的物理地址,而是虚拟地址,给的是相对地址,所以我们用&得到的不是实际的物理地址空间,所以两个进程的变量可能具有相同的地址
进程映像(IMAGE)= 程序+数据+栈(用户栈、内核栈)+PCB
对进程执行活动全过程的静态描述
线程
进程中的一个运行实体,是CPU的调度单位,又称为轻量级进程
线程:也叫轻量级的进程,它是一个基于进程的运行单位,它可以不占有资源,一个进程可以有一个线程或者多个线程(至少一个),这些线程共享此进程的代码、数据和部分管理信息,但是每个线程都有它自己的PC、STACK、寄存器和其他
进程和线程的区别:
- 地址空间和资源不同:进程间相互独立;同一进程的各个线程之间共享
- 通信不同:进程间可以使用IPC(Inter-Process Communication)通信,线程之间可以直接读写进程数据段来进行通信;但是需要进程同步和互斥手段的辅助,以保持数据的一致性
- 调度和切换不同:线程的上下文切换比进程上下文的切换要快的多
产生的原因:
应用的需要(web服务器性能会提高;对文档第一页的修改,后续的跟进工作
| 模型 | 特性 |
| ————— | ————————————————————— |
| 多线程 | 有并发、阻塞系统调用 |
| 单线程进程 | 无并发、阻塞系统调用 |
| 有限状态机 | 有并发、非阻塞系统调用、中断【但是很复杂】 |开销的考虑(线程的开销小,创建和切换线程的开销小,同时线程之间通信不需要开销
性能的考虑
线程的属性
- 标识符ID
- 状态和状态转换
- 不运行时需要保存上下文环境
- 线程可以被独立调度,有自己的堆栈和栈指针
- 共享所在进程的地址空间和其他资源(所以通信很方便
- 可以创建、撤销另一个线程
- 程序开始是以一个单线程进程方式运行的
左边是所有线程共有的,后者为每个线程独有的

程序计数/寄存器/栈/状态
地址空间/全局变量/打开文件的清单/子进程/突出的警报/信号和信号处理/会计信息
线程机制的实现
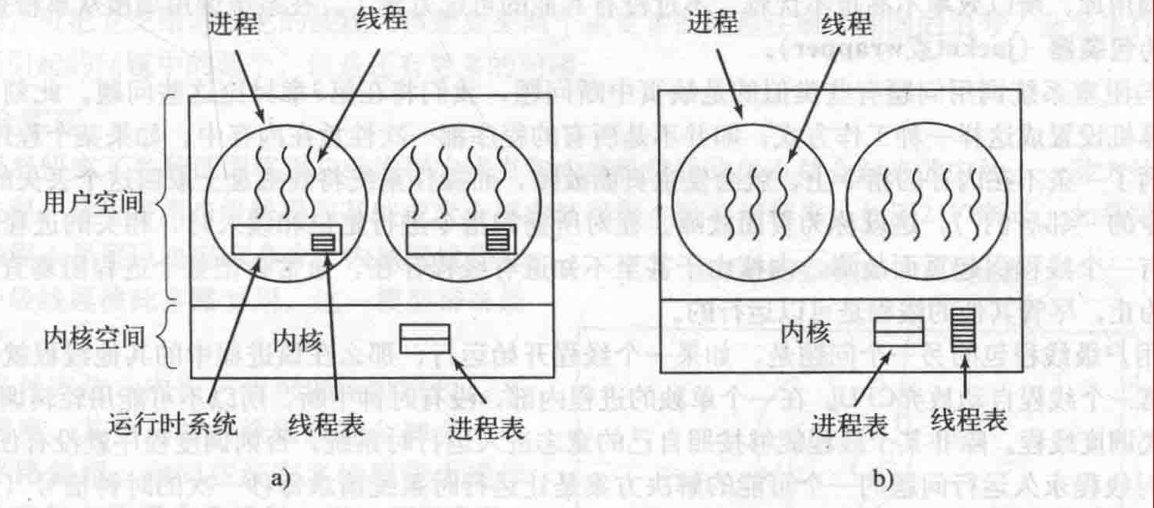
用户级线程
内核管理的还是进程,不知道线程的存在
线程切换不需要内核态特权
- 在用户空间建立线程库,提供一组管理线程的过程
- 运行时系统:线程表,完成线程的管理工作
优点:
- 线程切换快,有较好的伸缩性
- 调度算法是应用程序特定的,允许每个进程有自己定制的调度算法
- 用户级线程可运行在任何操作系统上,甚至可以在不支持线程的操作系统上实现(只需要实现线程库
缺点:
- 内核只将处理器分配给进程,同一进程中的两个线程不能同时运行于两个处理器上,即同一进程的两个线程不可以同时运行
- 大多数系统调用是阻塞的,因此,由于内核阻塞进程,故进程中所有线程也被阻塞(解决方法:Jacketing/wrapper
内核级线程
内核管理所有线程管理,并向应用程序提供API接口
内核维护进程和线程的上下文
线程的切换需要内核的支持(进行系统调用,通过对线程表的更新完成线程创建和撤销工作)
以线程为基础进行调度
优点:
- 对多处理器,内核可以同时调度同一进程的多个线程
- 阻塞在线程一级完成
缺点:
- 在同一进程内的线程切换调用内核,开销大,导致速度下降
用户级线程与内核级线程
用户级线程和内核级线程之间的差别在于性能
- 用户级线程的线程切换只需要少量的机器指令
- 内核级线程的线程切换需要完成的上下文切换,导致了若干数量级的延迟
- 使用内核级线程时,线程的阻塞不会将整个进程阻塞
- 从进程A的一个线程切换到进程B的一个线程,其代价高于运行进程A的第2个线程
- 用户级线程可以使用专为应用定制的线程调度程序
混合级线程
- 线程创建在用户空间完成
- 多个用户级线程多路复用多个内核级线程
- 线程调度等在核心态完成
- 每个内核级线程有一个可以轮流使用的用户级线程集合
Pthread的线程操作
|
|
线程调度
条件:
- 线程正常终止 或 由于某种错误而终止
- 新线程创建 或 一个等待线程变成就绪
- 当一个线程从运行态进入阻塞态
- 当一个线程从运行态变为就绪态
其他:
可再入程序(重入)可被多个进程同时调用的程序
Quiz3错题
4 死循环的时候,互相依赖
5 还有撤销该进程的PCB
- CPU切换到另一个进程需要保存当前进程的状态并恢复另一个进程的状态,所以可以中断
- 正确的是1234
- 进程运行时,其硬件状态保存在CPU的寄存器中;进程不运行时,这些寄存器的值保存到进程控制块PCB中

- 应该是阻塞原语
- 一个进程中的所有线程共享该进程的地址空间,但它们有各自独立的栈,而堆才为本进程中所有线程共享。
处理器调度
其任务是控制、协调进程对CPU的竞争
即按一定的调度算法从就绪队列中选择一个进程,把CPU的使用权(控制权)交给被选中的进程;如果没有就绪进程,系统会安排一个系统空闲进程
决策三个方面:
- What 选择下一个运行的进程
- When 何时选择,调度时机
- How 如何让选中的进程在CPU上运行,即进程的上下文切换
CPU调度时机
内核对中断/异常/系统调用处理后返回到用户态后
- 进程正常终止 或 由于某种错误而终止
- 新进程创建 或 一个等待进程变成就绪
- 当一个进程从运行态进入阻塞态
- 当一个进程从运行态变为就绪态
- 当发生I/O中断时
- 当硬件时钟中断时
进程切换:是指一个进程让出CPU,由另一个进程占用处理器的过程
- 切换全局页目录以加载一个新的地址空间
- 切换内核栈和硬件上下文,其中硬件上下文包括了内核执行新进程需要的全部信息,如CPU相关寄存器
切换过程包括了对原来运行进程各种状态的保存和对新进程各种状态的恢复
上下文切换
CPU硬件状态从一个进程换到另一个进程的过程
具体步骤
- 保存进程A的上下文环境(程序计数器、程序状态字、其他寄存器等)
- 用新状态和其他相关信息更新进程A的PCB
- 把进程A移至合适的队列(就绪、阻塞……)
- 把进程B的状态设置为运行态
- 从进程B的PCB中恢复上下文环境(程序计数器、程序状态字、其他寄存器等)
开销
直接开销:内核完成切换所用的CPU时间(保存和恢复寄存器、切换地址空间)
间接开销(高速缓存Cache、缓冲区缓存Buffer Cache和TLB [Translation Lookup/lookaside Buffer]【转换检测缓冲区】失效)
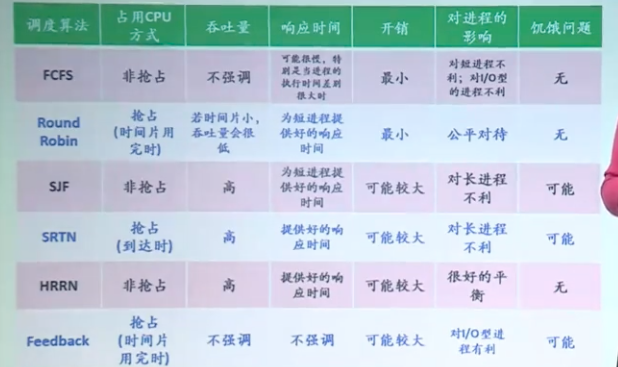
调度算法
当计算机是多程序设计时,只要两个或多个进程同时处于就绪状态,它就经常有多个进程同时竞争CPU
进行选择的操作系统部分称为调度程序(scheduler),它使用的算法称为调度算法(scheduling algorithm)
调度算法根据对时钟中断的处理,分为两种形式:
- 非抢占式(nonpreemptive)调度算法:挑选一个进程,让该进程运行直至被阻塞,或者直到该进程自动释放CPU
- 抢占式(preemptive)调度算法:挑选一个进程,并让该进程运行某个固定时段的最大值;如果在该时段结束时,进程仍然运行,它就被挂起,而调度程序挑选另一个进程运行
考虑的方面:
| 用户角度 | 系统角度 | |
|---|---|---|
| 性能 | 周转时间 响应时间 最后期限 |
吞吐量 CPU利用率 |
| 其他 | 可预测性 均衡性 |
公平性 强制优先级 平衡资源 |
- CPU utilization(CPU利用率):CPU利用率 = 1- p^n
- n个进程
- 每个等待I/O的时间与停留在内存中的时间之比为p
- Throughput(吞吐率):the number of jobs per hour that the system completes.
- Average turnaround time(平均周转时间):the statistically average time from the moment that a batch job is submitted until the moment it is completed
- $T=\frac{1}{n}\displaystyle\sum^{n}_{i=1}(T_{oi}-T_{si})$
- 其中,$T_{oi}$完成时间,$T_{si}$提交时间
衡量指标
吞吐量:每单位完成的进程数目
周转时间TT:每个进程从提出请求到运行完成的时间
响应时间RT:从提出请求到第一次回应的时间
CPU利用率:CPU做有效工作的时间比例
等待时间:每个进程在就绪队列等待的时间
批处理系统的调度算法
处理系统,通常会提交的进程多于可以立即执行的进程数,因此传入的进程被假脱机(到磁盘)
- 长期调度程序从此进程池中选择进程并将所选进程加载到内存中以供执行(作业调度)【哪个程序被系统选中并创建进程运行它】
- 中期调度程序可以将这些过程重新引入内存(内存调度),此操作也称为交换(对换),交换是改善过程组合或释放内存所必需的【决定是否将进程调入内存】
- 短期调度程序选择从已经在内存中的进程中获取处理器的进程(CPU调度)【哪个进程获得处理器资源(通常所说的调度)】
先来先服务FCFS
Fist Come First Server
先进先出,按照进程就绪的先后顺序使用CPU
非抢占式
特点:
- 公平
- 易于理解,实现简单
- CPU利用率低
- 长时间后面的短进程需要等待较长的时间,用户的体验不好
最短作业优先 SJF
Short Job First
具有最短完成时间的进程优先执行
非抢占式
缺点:
- 必须预知作业的运行时间
- 可能造成先期到达的长作业过长的等待
最短剩余时间优先 SRTN
Shortest Remaining Time Next
SJF抢占式版本,即当一个新就绪的进程比当前运行进程具有更短的完成时间时,系统抢占当前进程,选择新就绪的进程执行
特点:
- 最短的平均周转时间(在所有进程同时可运行时
- 必须预知作业的运行时间
- 不公平(当源源不断的短任务到来,可能使长的任务长时间得不到运行,产生“饥饿”现象)
#最高响应比优先HRRN
Highest Response Ratio Next
是一个综合的算法,折衷处理(FCFS和SJF的折衷),既考虑了作业到达的时间,又考虑了作业的长短
调度时,首先计算每个进程的响应比R;之后总是选择R最高的进程执行
响应比R=周转时间/处理时间=(处理时间+等待时间)/处理时间=1+(等待时间/处理时间)
交互式系统的调度算法
强调响应时间公平、平衡
时间片轮转调度RR
Round Robin
时间片
一个时间段,分配给调度上CPU的进程,确定了允许该进程运行的时间长度
考虑:进程切换的开销,对响应时间的要求,就绪进程个数,CPU能力,进程的行为
时间片太长:降级为先来先服务算法,延长短进程的响应时间
时间片太短:进程切换浪费CPU时间
20-50毫秒是一个折中的好选择
目标:
为短任务改善平均响应时间
解决问题的思路:
- 周期性切换
- 每个进程分配一个时间片
- 时钟中断->轮换
特点:
- 公平
- 有利于交互式计算,响应时间快
- 由于进程切换,时间片轮转算法要花费较高的开销
- RR对不同大小的进程是有利的,但是对于相同大小的进程,比FCFS平均响应时间还要长
#虚拟轮转法 Virtual RR
由于RR对I/O型密集型进程不友好
所以I/O进程单独设置队列,只有I/O型进程的队列为空时,才从就绪队列中用RR算法
最高优先级调度HPF
Highest Priority First
优先级 and 优先数
优先数反应了系统的优先级
静态优先级 and 动态优先级(在就绪队列等待时间过长,需要提高优先级)
就绪队列可以按优先级来分队列,从高优先级的队列中先取出进程来完成
系统进程优先级高于用户进程,前台进程优先级高于后台进程,操作系统更偏好I/O型进程
特点:
时间简单
不公平
优先级反转问题:基于优先级的抢占式
优先级翻转是当一个高优先级任务通过信号量机制访问共享资源时,该信号量已被一低优先级任务占有,因此造成高优先级任务被许多具有较低优先级任务阻塞,实时性难以得到保证。
是一个系统错误,高优先级进程停滞不前,导致系统性能降低
一个低优先级进程持有一个高优先级进程所需要的资源,使得高优先级进程等待低优先级进程运行
解决方案:
- 设置优先级上限(进入临界区的进程优先级比未在临界区的进程的优先级要高
- 优先级继承(临时继承高优先级进程的优先级
- 使用中断禁止(进入临界区的进程不响应中断
多级反馈队列
Multiple feedback queue
综合调度算法,折衷算法
设置多个就绪队列,第一级队列优先级最高
给不同就绪队列中的进程分配长度不同的时间片,第一级队列时间片最小,随着队列优先级别的降低,时间片增大
各组队列按照时间片轮转方式进行调度
- 当一个新创建进程就绪后,进入第一级队列
- 进程用完时间片而放弃CPU,进入下一级就绪队列
- 由于阻塞而放弃CPU的进程进入相应的等待队列,一旦等待的时间发生,该进程回到原来一级的等待队列(队首/队尾、时间片剩余/重新计算)
短进程优先
Shortest process next
保证调度
Guaranteed scheduling
向用户做出有关性能的真实承诺,然后实现它们
彩票调度
Lottery scheduling
为各种系统资源提供流程彩票,在安排时随机选择彩票,持有该票据的过程获得资源。
公平分享调度
Fair-share scheduling
每个用户都分配了一部分CPU
实时系统调度
m个periodic events(周期性事件),事件i发生在周期Pi内并且需要Ci秒
然后负载只能被处理在$\displaystyle\sum^m_{i=1}\frac{C_i}{P_i}\leq1$的条件下
各调度算法的比较
windows线程调度
- 调度单位是线程,采用基于动态优先级的、抢占式调度,结合时间配额的调整
- 就绪线程按优先级进入相应的队列,系统总是选择优先级最高的就绪线程运行
- 同一优先级的各线程按时间片轮转进行调度
- 多CPU系统中允许多个线程并行运行
- 引发线程调度的条件(除线程调度的条件外,加上以下两条:
- 一个线程的优先级改变了
- 一个线程改变了它的亲和(Affinity)处理机集合
- 亲和处理机集合:就是某线程所运行的处理机集合
- 32个线程优先级,分成三类
- 系统线程 0
- 用于对系统中空闲物理页面清零
- 可变优先级 1-15
- 可在一定范围内升高或降低
- 五种改变优先级的情况:
- I/O操作完成
- 信号量或事件等待结束
- 前台进程中的线程完成一个等待操作
- 由于窗口活动而唤醒窗口线程
- 线程处于就绪态超过了一定的时间还没有运行——“饥饿”现象
- 实时优先级 16-31
- 不可以改变优先级
- 被抢占后,又恢复的时候,放在就绪队列队首
- 系统线程 0
- 时间配额:配额单位的整数(如果用完了自己的时间配额,若没有其他相同优先级的进程,则重新分配时间配额,一般为5毫秒(比时间片的时间小很多)
UNIX两级调度算法
- 高级调度算法:在内存和磁盘之间移动进程以保证所有的进程都有机会进入内存运行
- 低级调度算法:从内存中的一组进程选取某个进程运行
- 多级队列:每一个队列与不重叠的优先级关联
- 每个进程的优先级按照下列公式每秒一次地被重新计算:
nice默认值为0,变化范围-20~20优先级 = CPU_usage + nice + base
多处理器调度算法
不仅需要决定哪一个进程,还需要决定在哪一个CPU上执行
要考虑进程在多个CPU之间迁移时的开销(尽可能使进程总是在同一个CPU上执行
考虑负载均衡问题
Quiz4 模糊题
PPT练习题
Three batch jobs A through C, arrive at a computer center at 0, 2, 3 second. They have estimated running time of 3, 5, and 4 seconds. Their priorities are 3, 2and 1, respectively, with 1 being the highest priority. For each of the following scheduling algorithms, determine the mean process turnaround time. Ignore process switching overhead.
(a) Round robin (quantum=1s)(b) Priority scheduling (Nonpreemptive)
(c) Priority scheduling (Preemptive)
(d) FCFS
(e) Shortest job first (Preemptive).
分析:a. A 0-1 1-2 4-5 所以5
B 2-3 5-6 7-8 9-10 11-12 所以10 C 3-4 6-7 8-9 10-11 所以8
平均轮转时间(5+8+10)/3=23/3
b. A 0-3 所以3 B 7-12 所以10 C 3-7 所以4
平均轮转时间(3+10+4)/3=17/3
c. A 0-2 11-12 所以12 B 2-3 7-11 所以9 C 3-7 所以4
平均轮转时间(12+9+4)/3=25/3
d. A 0-3 所以3 B 3-8 所以6 C 8-12 所以9
平均轮转时间(3+6+9)/3=6
e. A 0-3 所以3 B 7-12 所以10 C 3-7 所以4
平均轮转时间(3+10+4)/3=17/3
Four batch jobs A through D, arrive at a computer center at 0, 2, 3, 4 second. They have estimated running time of 3, 5, 4, and 1 seconds. Their priorities are 3, 2, 1, and 4, respectively, with 1 being the highest priority. For each of the following scheduling algorithms, determine the mean process turnaround time. Ignore process switching overhead.
(a) Round robin (quantum=1s)
(b) Priority scheduling (Preemptive)
(c) Priority scheduling (Nonpreemptive)
(d) FCFS
(e) Shortest job first (Preemptive)
(f) Shortest job first (Nonpreemptive)分析:
a. A 0-2 5-6 所以6 B 2-3 6-7 8-9 10-11 12-13所以11
C 3-4 7-8 9-10 11-12所以9 D 4-5 所以1
平均周转时间:(6+11+9+1)/4=27/4
b. A 0-2 11-12 所以12 B 2-3 7-11所以9
C 3-7 所以4 D 12-13 所以9
平均周转时间:(12+9+4+9)/4=34/4
c. A 0-3 所以3 B 7-12 所以10
C 3-7 所以4 D 12-13 所以9
平均周转时间:(3+10+4+9)/4=26/4
d. A 0-3 所以3 B 3-8 所以6
C 8-12 所以9 D 12-13 所以9
平均周转时间:(3+6+9+9)/4=27/4
e. A 0-3 所以3 B 8-13 所以11
C 3-4 5-8所以5 D 4-5 所以1
平均周转时间:(3+11+5+1)/4=5
f. A 0-3 所以3 B 8-13 所以11
C 3-7所以4 D 7-8所以4
平均周转时间:(3+11+4+4)/4=22/4
Five batch jobs A through E, arrive at a computer center at almost the same time. They have estimated running times of 10, 6, 2, 4 and 8 minutes. Their priorities are 3, 5, 2, 1 and 4, respectively, with 5 being the highest priority. For each of following scheduling algorithms, determine the mean process turn-around time. Ignore process switching overhead. (a) Round robin; (b)Priority scheduling; (c)First-come, first-served(run in order 10, 6, 2, 4, 8); (d)Shortest job first
For (a) assume that the system is multiprogrammed, and that each job gets its fair share of the CPU. For (b) through (d) assume that only one job at a time runs, until it finishes. All jobs are completely CPU bound.a.
5个作业共享CPU,每个作业各获得1/5的CPU时间:C结束需要10分钟。( TC = 10)
4个作业共享CPU,每个作业各获得1/4的CPU时间:D结束需要8分钟。( TD = 10 + 8 = 18)
3个作业共享CPU,每个作业各获得1/3的CPU时间:B结束需要6分钟。( TB = 18 + 6 = 24)
2个作业共享CPU,每个作业各获得1/2的CPU时间:E结束需要4分钟。( TE = 24 + 4 = 28)
A独占CPU运行2分钟,A结束:( TA = 28 + 2 = 30)
平均周转时间T = 22b. B 0-6 E 6-14 A 14-24 C 24-26 D 26-30 所以平均周转时间是(6+14+24+26+30)/5=20
c. A 0-10 B 10-16 C 16-18 D 18-22 E 22-30 所以平均周转时间是(10+16+18+22+30)/5=96/5=19.2
d. C 0-2 D 2-6 B 6-12 E 12-20 A 20-30 所以平均周转时间是(2+6+12+20+30)/5=14
Five processes A, B, C, D and E arrived in this order at the same time with the following CPU burst and priority values. A smaller value means a higher priority.
Fill the entries of the following table with waiting time and mean process turnaround time for each indicated scheduling policy and each process. Ignore context switching overhead.| | CPU Burst | Priority |
| ——- | ——————- | —————— |
| A | 3 | 3 |
| B | 7 | 5 |
| C | 5 | 1 |
| D | 2 | 4 |
| E | 6 | 2 |等待时间=完成时间-任务需要时间
| Scheduling Policy | Waiting | | | | Time | Mean Process turnaround time |
| —————————————————— | :—————————-: | :—————————————————-: | :————————————————: | :———————: | :————————————————-: | ———————————————— |
| | A | B | C | D | E | |
| First-Come-First-Served | 0 | 3 | 10 | 15 | 17 | (3+10+15+17+23)/5=68/5 |
| Non-Preemptive Shorted-Job First | 2 | 16 | 5 | 0 | 10 | (2+5+10+16+23)/5=56/5 |
| Priority | 11 | 16 | 0 | 14 | 5 | (5+11+14+16+23)/5=69/5 |
| Round-Robin(time quantum = 2) | 0-2 10-11
11-3=8 | 2-4 11-13 17-19 22-23
23-7=16 | 4-6 13-15 19-20
20-5=15 | 6-8
8-2= 6 | 8-10 15-17 20-22
22-6=16 | (11+23+20+8+22)/5=84/5 |
同步机制
进程的并发执行
从进程的特征来看:
并发
- 进程的执行是间断性的
- 进程的相对执行速度不可预测
共享
- 进程/线程之间的制约性
- 不确定性
- 进程执行的结果与其执行的相对速度有关,是不确定的
进程互斥
竞争条件(Race condition):两个或多个进程读写某些共享数据,而最后的结果取决于进程的精确时序
进程定义:由于各进程要求使用共享资源(变量、文件等),而这些资源需要排他性使用,各进程之间竞争使用这些资源
临界资源: 系统中某些资源一次只允许一个进程使用,称这样的资源为临界资源或互斥资源或共享变量
临界区(互斥区): 各个进程中对某个临界资源(共享变量)实施操作的程序片段
- 使用原则
- 没有进程在临界区时,想进入临界区的进程可进入
- 不允许两个进程同时处于其临界区中
- 不应对CPU的速度和数量做任何假设
- 临界区外运行的进程不得阻塞其他进程进入临界区
- 不得使进程无限期等待进入临界区
由于临界区的存在,在基于抢占式的优先级调度中,可能会出现优先级反转的问题(在最高优先级调度HPF中,有提到过)
有7种方法:忙等待的互斥、休眠与唤醒、semaphores信号量、mutexes互斥锁、monitors管程、消息传递、屏障
解决方案
软件方案
进入临界区之前需要一系列判断,增加开销;需要较高的编程技巧
设置临界区空闲标志——锁变量
false:无进程在临界区(初值为false);true:有进程在临界区
缺点:因为进程的相对执行速度是不确定的,所以我们需要对lock()操作进行原子化,否则还是会导致进程之间覆盖数据的情况,即出现两个进程同时进入临界区的情形
进入临界区的进程没有来得及置锁变量时,另一个进程开始运行,进入临界区;等到第一个进程再次被调度时,也进入临界区。
|
|
谁进临界区的标志turn
true: P进程进入临界区;false:Q进程进临界区;初始值任意
缺点:Q进程想要执行,必须等待P进程执行完之后才可以进行,这样违反了“临界区外运行的进程不得阻塞其他进程进入临界区”;且对于多个进程的时候,turn的设置复杂
|
|
设置两个标志 pturn,qturn
初始值为false
P进入临界区的条件pturn¬ qturn
Q进入临界区的条件not turn&qturn
缺点:会导致两个进程都想进入临界区的时候,都进不去,最后时间片用完,但是临界区却空闲着;当有多个进程的时候,标志过多,while语句复杂
|
|
Dekker
第一个用软件方法解决了进程互斥的问题
在算法三的基础上加上turn的变量,这样在两个进程都谦让的情况下,决定哪个进程优先进入临界区
缺点:在让出CPU的时候,还要保持循环,不断判断,进入忙等待状态,一直在CPU上等到时间片用完为止
|
|
Peterson
解决了互斥访问的问题,而且克服了强制轮流法的缺点,可以完全正常地工作
主要思想:
|
|
具体实现:
|
|
硬件方案
屏蔽中断
“开关中断”指令
在进入临界区之前,执行“关中断”操作;在离开临界区之后,执行“开中断”操作
特点:
- 简单,高效
- 代价高,限制CPU并发能力(临界区大小)
- 不适用于多处理器,(只可以关一个CPU的,不可以控制所有的CPU都关上,这个进程可以用其他的CPU来抢占资源
- 适用于操作系统本身,不适于用户进程(用户程序不可以直接控制中断标志的
TSL指令
“测试并加锁”指令 Test and set lock
在CPU对内存总线上进行加锁,但是这样的方法也是会忙等待;但是对多处理器有效(因为对于同一个进程,会在一个CPU上循环,所以不会出现这个进程到其他CPU上进入临界区
- 将一个内存字LOCK读到寄存器RX中,然后在该内存地址上存一个非零值
- 读数和写数操作保证是不可分割的。
- 执行TSL指令的CPU将锁住内存总线,以禁止其他CPU在本指令结束之前访问内存
|
|
互斥仅适用于管理对某些共享资源或代码段的互斥
互斥锁是一个变量,可以处于以下两种状态之一:解锁或锁定
|
|
XCHG指令
s p
也是通过加锁的方式(基本类似),但是是对锁和寄存器的内容进行交换操作
|
|
忙等待busy waiting
进程在得到临界区访问权之前,持续测试而不做其他事情
在单处理器上,应该拒绝这种方案;在多处理器上,因为切换的开销更大(临界区的时间比较短),所以可以允许忙等待的存在,同时把忙等待称作为自旋锁 Spin lock
阻塞Block
在不允许他们进入关键区域时,禁止他们因为忙等待而浪费CPU时间;存在两个操作:
睡眠sleep:导致进程暂停,直到另一个进程唤醒它
唤醒wakeup:唤醒过程
进程同步synchronization
指系统中多个进程中发生的事件存在某种时序关系,需要相互合作,共同完成一项任务(多个进程之间的协作关系)
具体来说,一个进程运行到某一点时,要求另一伙伴进程为它提供消息,在未获得消息之前,该进程进入阻塞态,获得消息后被唤醒进入就绪态
信号量及PV操作
信号量(semaphore s):一个特殊变量,用于进程间传递信息的一个整数值
由Dijkstra提出的同步互斥工具(可以完成同步,也可以完成互斥的功能)
可实施的操作:
- 初始化
- P操作(原语操作):down
- 检查信号量的值是否大于0
- 若大于0,则将其值减1,并继续
- 若等于0,则进程将休眠,而此时down操作并未结束
- 上述操作均作为单一的、不可分割的原子操作完成
- V操作(原语操作):up
- 对信号量的值增1
- 如果一个或多个进程在该信号量上休眠,无法完成一个先前的down操作,则由系统选择其中一个并允许该进程完成它的down操作
二元信号量(binary semaphore):也称互斥(mutex)信号量,用于实现进程间的互斥,初值为1,保证同时只有一个进程可以进入临界区
计数信号量:也称同步信号量,用于实现进程间的同步,初值为0或某个正整数n,仅允许拥有它的进程对其实施P操作
计数信号量可以有多个值,而mutex只有两个值;
计数信号量一般在内核态下实现,而mutex一般在用户态下实现;
计数信号量数量远小于mutex的数量
两种实现方式:
- semaphore的取值必须大于或等于0;0表示当前已没有空闲资源,而正数表示当前空闲资源的数量
- semaphore的取值可正可负,负数的绝对值表示正在等待进入临界区的进程个数(目前采用这种比较多)
不管哪种,当信号量的值大于0时,表示当前可用资源的数量
信号量的值仅能由P、V操作来改变
定义:
|
|
P操作:
|
|
V操作:
|
|
解决步骤:
- 分析并发进程的关键活动,划定临界区
- 设置信号量mutex,初值为1
- 在临界区前实施P(mutex)
- 在临界区之后实施V(mutex)
生产者/消费者问题(有界缓冲区问题)
比如:在spooling技术的打印中,输入进程和调度程序也是一个生产者/消费者问题
有问题但是一般的思考过程:(原因:对count的访问未加限制)
|
|
解决方案:
|
|
读者/写者问题
条件:
- 允许多个读者同时执行读操作
- 不允许多个写者同时操作
- 不允许读者、写者同时操作
读者优先
|
|
管程
(在存在信号量之后)引入管程的原因:信号量机制的不足:程序编写困难、易出错
定义:
管程是一个由过程,变量和数据结构等组合的一个集合,它们组成一个特殊的模块或软件包。进程可在任何需要的时候调用管程中的过程,但它们不能在管程之外声明的过程中直接访问管程内的数据结构。任一时刻管程中只能有一个活跃进程
- 一种高级同步机制
- 是一个特殊的模块(是过程,变量,数据结构的集合)
- 有一个名字
- 由关于共享资源的数据结构及在其上操作的一组过程组成
管程与进程的区别
- 进程定义的是私有数据结构PCB,管程定义的是公共数据结构;
- 进程是由顺序程序执行有关操作,而管程主要是进行同步操作和初始化操作;
- 设置进程的目的,在于实现系统的并发性,而管程的设置,则是解决共享资源的互斥使用问题;
- 管程为被动工作方式,进程则为主动工作方式;
- 进程之间能并发执行,而管程则不能与其调用者并发;
- 进程具有动态性,而管程则是操作系统中的一个资源管理模块,供进程调用
缺点:
- 易读性差
- 要了解对于一组共享变量及信号量的操作是否正确,则必须通读整个系统或者并发程序
- 不利于修改和维护
- 程序的局部性很差,所以任一组变量或一段代码的修改都可能影响全局
- 正确性难以保证
- 操作系统或并发程序通常很大,要保证这样一个复杂的系统没有逻辑错误是很难的
其他:进程无法直接访问monitor,只能通过通过调用管程中的过程来间接地访问管程中的数据结构;在任何时刻,管程中只能有一个进程处于活动状态
|
|
解决两大问题:
- 互斥
- 管程是互斥进入的——为了保证管程中数据结构的数据完整性
- 管程的互斥性是由编译器负责保证的
- 同步
- 管程中设置条件变量及等待/唤醒操作以解决同步问题
- 可以让一个进程或线程在条件变量上等待(此时,应先释放管程的使用权),也可以通过发送信号将等待在条件变量上的进程或线程唤醒
- 可能会出现Q进程唤醒了之前睡着的P进程,但是这样就出现了两个活跃进程的问题
- 方案一:规定唤醒操作为管程中最后一个可执行的操作,唤醒后进程就终止了
- 方案二:P等待Q执行
- 方案三:Q等待P继续执行
HOARE管程
当一个进程试图进入一个已被占用的管程时,进入管程的入口处设置的进程等待队列,此队列又称作入口等待队列
解决同步问题的时候,采用了方案三,一个管程内部允许存在多个等待进程,将它们放在管程内的进程等待队列,此队列又称作紧急等待队列,紧急等待队列的优先级高于入口等待队列的优先级
条件变量
在管程内部说明和使用的一种特殊类型的变量
var c:condition;
对于条件变量,可以执行wait和signal操作
wait(c)
如果紧急等待队列非空,则唤醒第一个等待者;否则释放管程的互斥权,执行此操作的进程进入c链末尾
signal(c)
如果c链为空,则相当于空操作,执行此操作的进程继续执行;否则唤醒第一个等待者,执行此操作的进程进入紧急等待队列的末尾
缺点:
- 两次额外的进程切换
MESA管程
解决了HOARE管程的缺点,通过把signal换成了notify的方法
notify:当一个正在管程中的进程执行notify(x)时,它使得x条件队列得到通知,发信号的进程继续执行
使得到通知的进程,在将来合适的时候且当处理器可用时恢复执行;但是这样不能保证在它之前没有其他进程进入管程,因而这个进程必须重新检查条件,用while循环取代if语句,这样会导致对条件变量至少多一次额外的检测(但不再有额外的进程切换),并且对等待进程在notify之后何时运行没有任何限制
可以对notify改进:
- 给每个条件原语关联一个监视计时器,不论是否被通知,一个等待时间超时的进程将会被设为就绪态
- 当该进程被调度执行时,会再次检查相关条件,如果条件满足则继续执行
- 引入broadcast:使所有在该条件上等待的进程都被释放进入就绪队列
相对于HOARE管程来说:出错率更小
管程的实现和应用
实现的途径:
- 直接构造:效率高
- 间接构造:用某种已经实现的同步机制(信号量,P、V操作)去构造
应用:
生产者/消费者问题
HOARE管程:
signal只能作为管程过程的最后一条语句
|
|
MESA管程
|
|
进程与管程
进程只能通过调用管程中的过程来间接地访问管程中的数据结构
- 进程定义的是私有数据结构PCB,管程定义的是公共数据结构
- 进程是由顺序程序执行有关操作,而管程主要是进行同步操作和初始化操作
- 设置进程的目的,在于实现系统的并发性,而管程的设置,则是解决共享资源的互斥使用问题
- 管程为被动工作方式,进程则为主动工作方式
- 进程之间能并发执行,而管程则不能与其调用者并发
- 进程具有动态性,而管程则是操作系统中的一个资源管理模块,供进程调用
Pthread的同步机制
|
|
生产者/消费者问题
|
|
通信机制
产生的原因:信号量及管程只能传递很简单的信息,不能传递大量的信息;管程不适用多处理器情况
进程通信机制:
- 消息传递:send&receive原语
send(destination, &message)receive(source, &message)
- 适用于:分布式系统、基于共享内存的多处理机系统、单处理机系统
- 可以解决进程间的同步问题、互斥问题、通信问题
- 设计的问题:确认消息,身份验证,性能
进程间的数据交换,是以格式化的消息(也称为报文)为单位的。程序员直接利用操作系统提供的一组通信命令(原语),实现大量数据的传递,通信过程对用户是透明的。
消息传递系统的通信方式分成两类:
- 直接通信方式:发送进程利用OS所提供的发送命令,直接把消息发送给目标进程
- 间接通信方式:进程之间的通信,通过中间实体(也称为信箱)来暂存发送进程发送给目标进程的消息,接收进程则从该实体中读取发送给自己的消息
基本通信方式:
- 消息传递
- buffer消息缓冲区:消息头(消息类型,接受进程ID,发送进程ID,消息长度,控制信息)消息体
- 发送send原语(需要申请消息缓冲区),陷入内核;复制消息;接收进程的PCB中消息队列指针,消息入队;receive原语,陷入内核,复制消息
- 共享内存
- 需要解决建立共享物理内存的地址映射问题和共享内存的读者/写者问题
- 管道
- 利用缓冲传输介质——内存或文件连接两个相互通信的进程
- 字符流的方式来写入读出,它是没有格式的
- 先进先出顺序
- 管道通信机制必须提供协调能力:互斥、同步、判断对方进程是否存在
- 套接字
- 远程过程调用
Linux的进程通信机制
用户进程:管道、消息队列、共享内存、信号量、信号、套接字……
内核同步机制:
- 原子操作
- 操作不可分割,在执行完之前不会被其他任务或事件中断
- 常用于实现资源的计数
- atomic_t类型
- 自旋锁
- 读写锁
- 信号量
- 屏障(栅栏、关卡)
- 一种同步机制
- 用于对一组线程进行协调
- 一组线程协同完成一项任务,需要所有线程都到达一个汇合点后再一起向前推进
- 常用于矩阵运算
- ……
注:验证代码的正确性:以不同的次序运行各进程,是否能保证问题的圆满解决,切忌按固定顺序执行各进程
Quiz 5 错题和模糊题
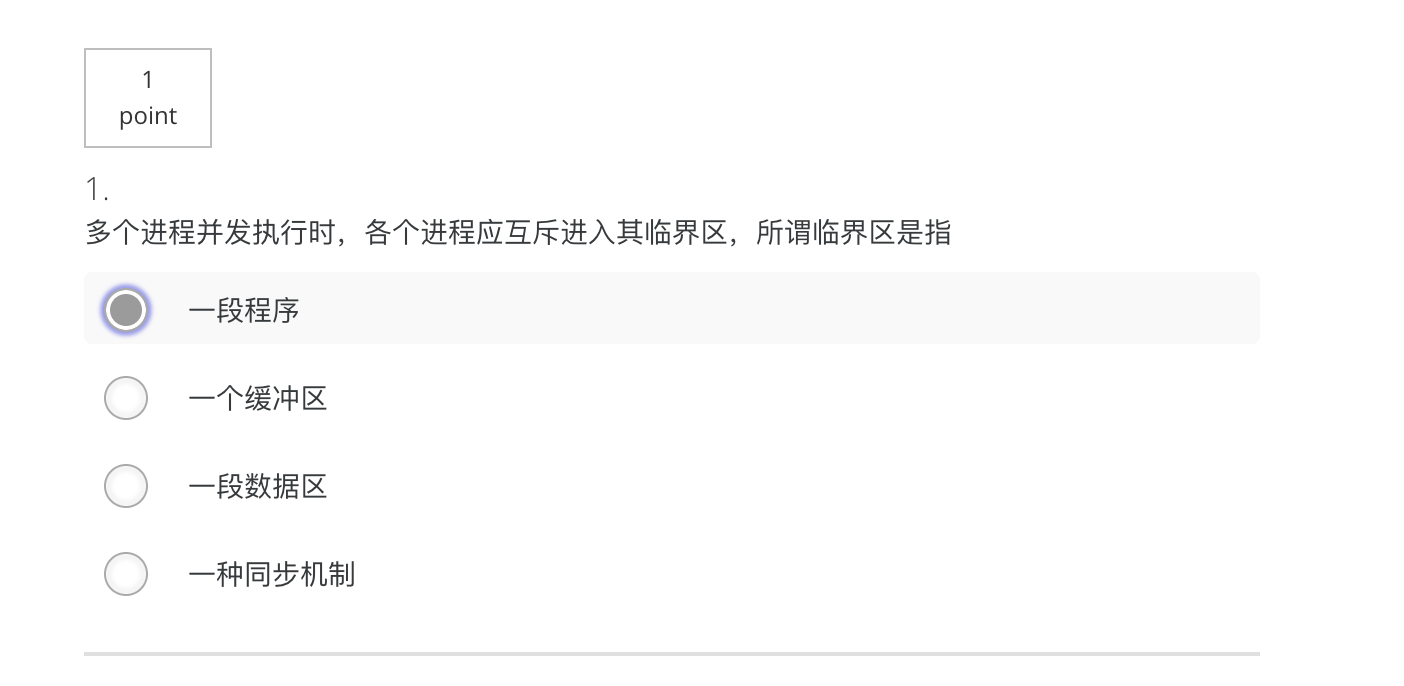
1 临界区执行相同的一段代码
5 麻将应该是没有互斥的部分

7 应该选择第3个,可以想像到进程在申请资源,所以是等待队列到就绪队列

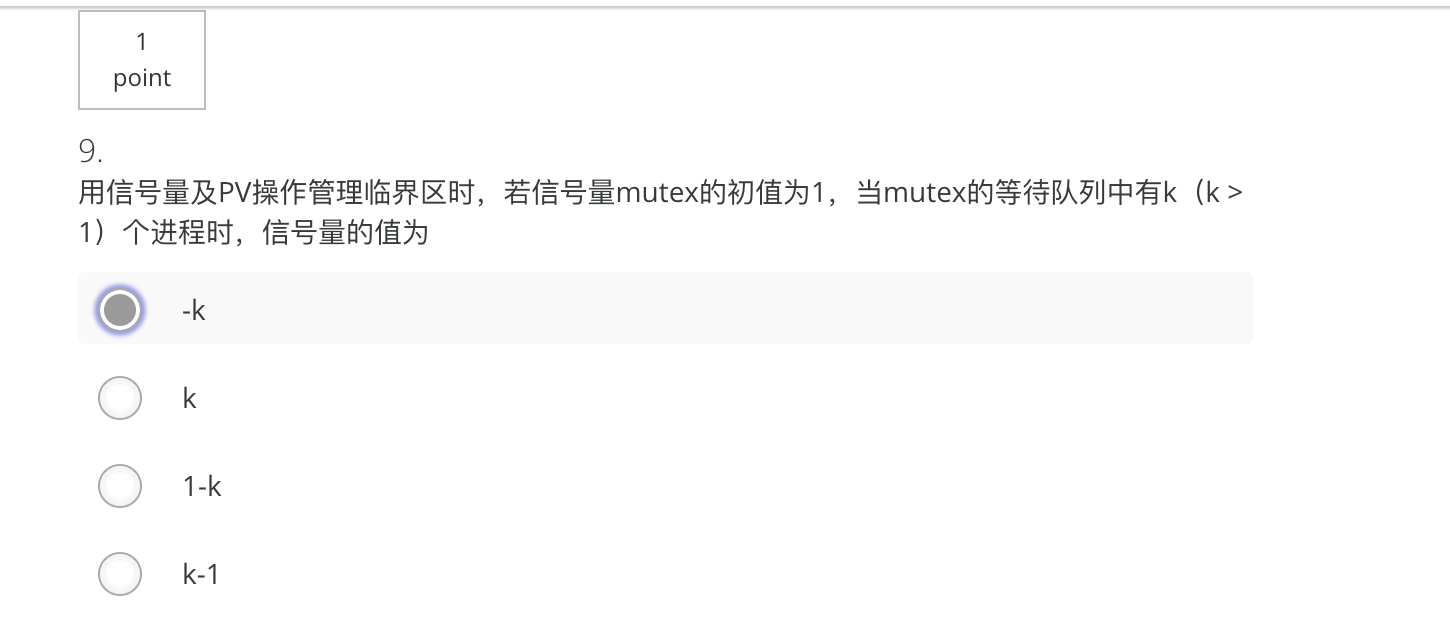
9 等待队列中有k个进程,而不是同时有k个进程来申请资源
10 错误,是中断不适合多处理器(见前文的解析)

Quiz 6 错题和模糊题


应该选择错误,唤醒之前的那个管程,然后等待唤醒之前的管程P执行完后,再执行后面的管程Q

PPT练习题
n processes shared one segment, if allow m(m<n) processes enter the mutual segment simultaneously(同时), then the value range of semaphore is __ .
-(n-m)~m
In the process management, if the initial value of semaphore S is 2 and the current value is -1, then there are ____ processes waiting for this resource.
1设一民航航班售票系统有n个售票处。每个售票处通过终端访问系统中的公用数据区,假定公共数据区中的某些单元xk(k = 1, 2, …)分别存放某月某日某次航班的现存票数。设P1,P2,…,Pn表示各售票处的处理进程,R1,R2,…,Rn表示各进程执行时所用的工作单元,试给出各个进程的程序代码
一个信号量s,保证每次访问公共数据区的只有一个进程,初值为1
12345678910111213141516semaphore s = 1;/* 进程Pi (i = 1, 2, …)的代码 */按旅客订票要求找到xk;P(s); /* 进程Pi进入临界区 */Ri = xk;if (Ri >= 1) {Ri = Ri - 1;xk = Ri ;V(s); /* 进程Pi离开临界区 */输出一张票;}else {V(s); /* 进程Pi离开进入临界区 */输出“票已售完”;}桌上有一只盘子,每次只能放入一个水果。爸爸专向盘中放苹果,妈妈专向盘中放桔子。一个女儿专门等着吃盘中的苹果,一个儿子专门等着吃盘中的桔子,试用P、V操作写出他们能同步的程序
生产者与消费者问题的变形:2个生产者(爸爸、妈妈)、2个消费者(女儿、儿子)共享一个只能存放一个数据的区域(盘子)
创建4个进程,分别对应爸爸、妈妈、女儿、儿子
信号量:
互斥信号量:empty = 1(能否向盘子中放水果)
同步信号量:SA = 0(最大苹果数)、SO = 0(最大桔子数)12345678910111213/* 爸爸进程 */P(empty);放入一个苹果;V(SA);…/* 女儿进程 */P(SA);取出苹果;V(empty);…A store has two consigners (发货员), one checker. when customer want to pick up the goods, if one of the consigner is idle, the customer is allowed to get into the store and take the goods. when customer leaves, the checker examines whether customer gets the right goods. To coordinate(协调) their works using PV operations, two semaphore S1 and S2 are used. The initial value of S1 is 2, and the initial value of S2 is 1. the operation in ‘a’ shown in the following figure should be (1); the operation in ‘b’, ‘c’ and ‘d’ should be (2) .
(1) A. P(S1) B. P(S2)C. V(S1) D. V(S2)(2) A. P(S2)、V(S2) and V(S1)
B. P(S1)、V(S1) and V(S2) C. V(S1)、P(S2) and V(S2) D. V(S2)、P(S1) and V(S1)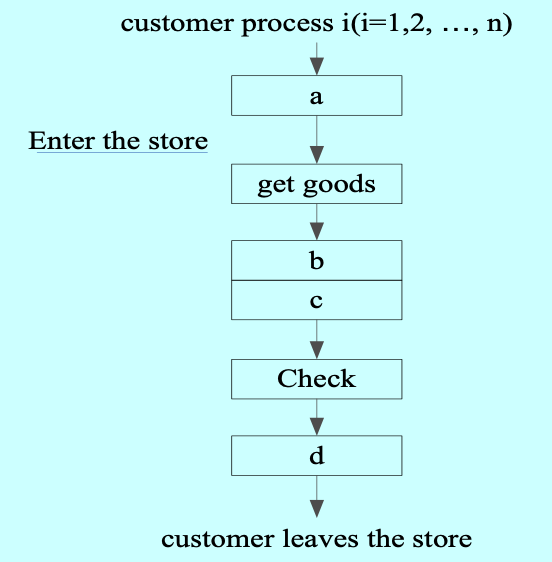
A C
有一阅览室,读者进入时必须先在一张登记表上进行登记。该表为每一座位列出一个表目,包括座号、姓名。读者离开时要撤销登记信息。阅览室有100个座位,试问:
(1) 为描述读者的动作,应编写几个程序,应该设置几个进程?进程和程序之间的对应关系如何? (2) 试用P、V操作描述这些进程间的同步算法分析:读者动作:登记、读书、撤销
座位总数100
登记/撤销都需要在登记表修改信息,一次只能由一个读者对登记表进行访问(登记表是临界资源,必须互斥访问)
1个程序,1个读者1个进程,进程是程序的一次执行
1234567891011121314151617181920212223typedef int semaphore;semaphore mutex = 1; empty = 100;Process reader() {到达阅览室;register();进入阅览室;unregister();离开阅览室;}register() {P(empty);P(mutex);登记;V(mutex);}unregister() {P(mutex);撤销登记;V(empty);V(mutex);}设有3个并发进程R、M、P,它们共享一个缓冲区。R负责从输入设备读信息,每读出一个记录后,就把它存放在缓区中;M在缓冲区中加工读入的记录;P把加工后的记录打印输出。读入的记录经加工输出后,缓冲区又可存放下一个记录。试写出它们能正确执行的程序
分析:R、M、P的同步,缓冲区每次只能放一个记录
12345678910111213141516171819semaphore s1 = 1, /* 缓冲区存放的最大记录数 */s2 = 0, /* 缓冲区中待加工的记录数 */s3 = 0; /* 缓冲区中待打印的记录数 */Process R() {读入一个记录;P(s1);将记录放入缓冲区;V(s2);}Process M() {P(s2);加工记录;V(s3);}Process P() {P(s3);打印记录;V(s1);}有三个进程A、B和C协作解决文件打印问题:A将文件记录从磁盘读入主存的缓冲区buffer1,每执行一次读一个记录;B将缓冲区buffer1的内容复制到缓冲区buffer2,每执行一次复制一个记录;C打印缓冲区buffer2的内容,每执行一次打印一个记录。缓冲区的大小和一个记录大小一样。请用P、V操作来保证文件的正确打印
分析:B既是生产者也是消费者
1234567891011121314151617181920212223242526272829303132semaphore mutex1 = mutex2 = 1;empty1 = empty2 = 1;full1 = full2 = 0;Process A() {从磁盘读入一个记录;P(empty1);P(mutex1);将记录放入缓冲区buffer1;V(full1);V(mutex1);}Process B() {P(full1);P(mutext1)从buffer1中取一条记录;V(empty1);V(mutex1);P(empty2);P(mutex2);将记录拷入buffer2;V(full2);V(mutex2);}Process C() {P(full2);P(mutext2)从buffer2中取一条记录;V(empty2);V(mutex2);打印记录}这里说明一下,首先对于生产者,是先占位P(empty),然后通过P(mutex)V(mutex),对V(full)进行操作来生产;对于消费者,它检查的是full,所以先P(empty)没有影响,还可以减少mutex的临界区的时间,而且对于加入的操作必须是原子性的,所以这样是ok的【可以对full和mutex的V操作进行交换】;同样的,对于消费者,先占位P(full),然后通过mutex对empty进行操作
存储管理
预备知识:
- 程序中装载到内存才可以运行:通常,程序以可执行文件格式保存在磁盘上
- 每个进程有自己的地址空间
- 一个进程执行时不能访问另一个进程的地址空间
- 进程中的地址不是最终的物理地址
- 在进程运行前无法计算出物理地址:因为不能确定进程被加载到内存什么地方
进程地址空间
- 内核地址空间
- 用户地址空间
- 栈
- 堆
- 数据段
- 代码段
地址重定位
又称地址转换、地址映射、地址翻译;将用户程序中的逻辑地址转换为运行时可由机器直接寻址的物理地址
逻辑地址:相对地址,虚拟地址;目标代码通常采用相对地址的形式,其首地址为0,其余地址都相对于首地址而编址;不能用逻辑地址在内存中读取信息
物理地址:绝对地址,实地址;内存中存储单元的地址,可直接寻址
静态重定位:当用户程序加载到内存时,一次性实现逻辑地址到物理地址的转换
- 一般由软件完成
动态重定位:在进程执行过程中进行地址变换,即逐条指令执行时完成地址转换
- 需要硬件部件支持
- CPU将逻辑地址送入到MMU(内存管理单元),MMU完成地址转换工作,得到物理地址
物理内存管理
空闲内存管理
- 等长划分
- 位图
- 不等长划分
- 空闲区表
- 已分配区表
- 空闲区链表
内存分配算法
将空闲块分配之后,又分成新的空闲块和已使用部分
- 首次适配 first fit
- 在空闲区表中找到第一块满足进程要求的空闲区
- 下次适配 next fit
- 从上次找到的空闲区处接着查找
- 最佳适配 best fit
- 查找整个空闲区表,找到能够满足进程要求的最小空闲区
- 需要搜索整个链表
- 并且对于空闲块的合并较为复杂
- 最差适配 worst fit
- 总是分配满足进程要求的最大空闲区
- 需要搜索整个链表
- 快速适配 quick fit
- 为一些所需的更常见尺寸维护单独的列表
伙伴系统
一种内存分配方案
主要思想:将内存按2的幂进行划分,组成若干空闲块链表;查找该链表找到能满足进程需求的最佳匹配块
算法:
- 首先将整个可用空间看作一块: $2^U$
- 假设进程申请的空间大小为s,如果满足$2^{U-1}<s\leq2^U$,则分配整个块;否则,将块划分为两个大小相等的伙伴,大小为$2^{U-1}$
- 一直划分下去直到产生大于或等于s的最小块
内存回收问题
当某一块归还后,前后空闲空间合并,修改内存空闲区表
内存管理方案
- 一个进程进入内存中连续的一块区域
- 单一连续区
- 一段时间内只有一个进程在内存
- 简单,内存利用率低
- 固定分区
- 把内存空间分割成若干区域,称为分区;每个分区的大小可以相同也可以不同
- 分区大小固定不变
- 每个分区装一个且只能装一个进程
- 在运行时进程大小会增长
- 该进程与一个空闲区相邻:把该空闲区分配给它
- 与该进程相邻的是另一个进程:把该进程移到内存的另一个足够大的分区,把其他进程交换出去
- 若进程不能在内存上增长,并且磁盘上的交换区也已经满了:进程只有等待或被杀死
- 可变分区
- 根据进程的需要,把内存空闲空间分割出一个分区,分配给该进程;剩余部分分成为新的空闲区
- 产生外碎片(进程之间的空闲区),导致内存利用率下降
- 单一连续区
一个进程进入内存中若干不连续的区域
页式(现代大多数计算机支持
用户进程地址空间被划分为大小相等的部分,称为页或页面,从0开始编号
内存空间按同样大小划分为大小相等的区域,称为页框,从0开始编号;也称为物理页面,页帧,内存块
内存分配规则
- 以页为单位进行分配,并按进程需要的页数来分配
- 逻辑上相邻的页,物理上不一定相邻
逻辑地址:页号+页内地址(偏移)
每个程序都有自己的地址空间,它被分成页;每个页面都是连续的地址范围;这些页面映射到物理内存,但并非所有页面都必须在物理内存中才能运行程序;分页允许程序分配不连续的内存块
将虚拟地址映射为物理地址的一般过程为:(类似于计组的直接映射方式)
- 把虚拟地址划分为两部分:页面号+页内偏移
- 以页面号为索引查找页表,找到该页面对应的页帧号
- 用页帧号替换虚拟地址中的页面号,得到物理地址
- 若给定一个虚拟地址空间中的地址为A,页面的大小为L,则页号P和页内偏移量offset可按下式求得:
- $P=INT[\frac{A}{L}]\ offset=A\ mod\ L$
页和页帧通常具有相同的大小
页表:记录进程的逻辑地址到物理地址的映射关系
- 每一行叫做页表项,页表项记录了逻辑页号与页框号的对应关系
- 每个进程一个页表,存放在内存
- 在进程上CPU的时候,页表的起始地址存放CPU中的一个控制寄存器,叫做页表基址寄存器(pagetablebaseregister,PTBR)
- 在进程未上CPU的时候,页表的起始地址存放在进程控制块中
- 地址转换(硬件支持):CPU取到逻辑地址,自动划分为页号和页内地址;用页号查页表,得到页框号,再与页内偏移拼接成物理地址
会产生内碎片
- 段式
- 用户进程地址空间按程序自身的逻辑关系划分为若干程序段,每个程序段都有一个段名
- 内存空间被动态划分为若干长度不相同的区域,称为物理段,每个物理段由起始地址和长度确定
- 内存分配原则
- 以段为单位进行分配
- 每段在内存中占据连续空间
- 但段之间可以不相邻
- 逻辑地址:段号+段内地址(不是自动划分的,必须显示给出)
- 段表:记录段逻辑地址到物理地址的映射关系
- 每项记录了段号、段首地址和段长度的关系
- 每个进程一个段表,存放在内存
- 在进程上CPU的时候,段表起始地址放在段表基址寄存器
- 在进程未上CPU的时候,页表的起始地址存放在进程控制块中
- 地址转换(硬件支持):CPU取到逻辑地址;用段号查段表,得到该段所在的起始地址,与段内偏移计算出物理地址
- 每个段由线性地址序列组成
- 不同的段可以并且通常具有不同的长度
- 不同的段可以独立地增长或缩小,而不会相互影响
- 逻辑实体
- 段页式
- 用户进程地址空间:先按段划分,每一段再按页面划分
- 内存空间划分同页式存储管理方案
- 内存分配原则:同页为单位进行分配
- 逻辑地址:段号+段内地址(页号+页内地址)【段内地址自动划分为页号+页内地址)
- 段表:记录了每一段的页表始址和页表的长度;每一段有一张页表
- 页表:记录了逻辑页号与页框号的对应关系;一个进程有多个页表(一个进程分在不同段)
- 段页式存储管理的基本思想:用分段方法来分配和管理虚拟存储器(逻辑存储空间),即对虚拟空间采用段式划分,把虚拟地址空间划分为若干段;按照内存分页的大小,把每一段划分成若干相等的页(管理物理存储空间)
- 段页式存储管理结合了分段和分页的优点:
- 统一的页面大小、在只使用段的一部分时不用把整个段全部调入内存(分页的优点)
- 易于编程、模块化、保护和共享(分段的优点)
碎片:
- 很小的、不易利用的空闲区
- 导致内存利用率下降
- 解决方案:紧缩compaction技术
- 在内存移动程序,将所有小的空闲区合并为较大的空闲区
- 需要考虑:系统开销,移动时机
内存“扩充”技术
解决在较小的内存空间运行较大的进程
内存紧缩技术(例如:可变分区)
将空闲区向下,就大概是上面都是占用的,下面都是空闲的,但是会耗费大量的CPU时间
覆盖技术 overlaying
主要用于早期的操作系统
- 按照其自身的逻辑结构,将不会同时执行的程序段共享同一块内存区域;要求程序各模块之间有明确的调用结构
- 程序员声明覆盖结构,操作系统完成自动覆盖
- 缺点:把程序分割成多个片断的工作必须由程序员来完成。
- 对用户不透明,增加了用户负担
交/对换技术 swapping
- 内存空间紧张时,系统将内存中某些进程暂时移到外存,把外存中某些进程换进内存,占据前者所占用的区域(进程在内存与磁盘之间的动态调度)
- 交换的内容:运行时创建或修改的内容(堆和栈)【对于代码块这些没有改变的,磁盘上已经有了,不需要再保存到磁盘上了】
- 交换分区:一般系统会指定一块特殊的磁盘区域作为交换区,包括连续的磁道,操作系统可以使用底层的磁盘读写操作对其高效访问
- 何时换出:不用就换出(很少再用);内存空间不够或有不够的危险时换出;与调度器结合使用
- 不应换出处于等待I/O状态的进程
虚拟存储技术 virtual memory
当进程运行时,先将一部分装入内存,另一部分暂留在磁盘,当要执行的指令或访问的数据不在内存时,由操作系统自动完成将它们从磁盘调入内存的工作
虚拟内存:
- 内存与磁盘的有机结合(从而得到了一个很大的“内存”,构建在存储体系之上,由操作系统协调各存储器的使用)
- 虚存提供了一个比物理内存空间大的多的地址空间
- 大小收到计算机的寻址机制和磁盘当中可用空间这两方面的限制
虚拟地址空间
分配给进程的虚拟内存
虚拟地址
在虚拟内存中指令或数据的位置,该位置可以被访问
地址保护(存储保护)
- 确保每个进程有独立的地址空间
- 确保进程访问合法的地址范围(防止地址越界)
- 确保进程的操作是合法的(防止访问越权)
虚拟页式存储管理系统(PAGING)
虚拟页式存储管理系统=虚拟存储技术+页式存储管理方案
以CPU时间和磁盘的空间换取昂贵内存空间(是操作系统中的资源转换技术)
基本思想
- 进程开始运行之前,不是装入全部页面,而是装入一个或零个页面
- 根据进程运行的需要,动态装入其他页面
- 当内存空间已满,而又需要装入新的页面时,则根据某种算法置换内存中的某个页面,以便装入新的页面
两种方式
- 请求调页(主要的)
- 预先调页(预测//缺页异常调入的时候,顺带调入相关的一些页)
页表及页表项
页表由页表项组成(页表项一般由硬件设计)
每个进程一张页表
包括:
- 页框号(内存块号、物理页号、页帧号)
- 有效位(驻留位、中断位)P:表示该页是在内存还是磁盘【页框号是否有效
- 访问位A:引用位
- 修改位D(dirty):(修改的话,还要写回磁盘),硬件来支持的
- 保护位:读/可读写 R/W,访问权限(用户组什么的)
- 缓存禁用位:此功能对于映射到设备寄存器而非内存的页面非常重要
- ……
若某个页面不在内存时,用于保存该页面的磁盘地址不是页表的一部分
32位虚拟地址空间(假设页面大小为4K;页表项大小为4字节,则:
一个进程地址空间有2^32/(4*2^10)=2^20页
其页表需要占2^20*4/(4K)=2^10=1024页
存在的问题:
- 从虚拟地址到物理地址的映射必须快速
- 解决方案1:把整个页表放在内存中,因执行过程中多次访问页表,导致效率较低;但实际中采用这种方案,基于大多数程序倾向于对少量页面进行大量引用的情况
- 解决方案2:使用一组快速硬件寄存器组成的单个页表,虚拟页面号作为索引,每个虚拟页面一个表项。
在一个进程启动时,操作系统把位于主存中的进程的页表装入寄存器,在进程运行期间不必因为页表而访问内存,造价昂贵,尤其是页表很大时 - 如果虚拟地址空间很大,则页表也会很大
页表页在内存中若不连续存放,则需要引入页表页的地址索引表:页目录
- 二级页表结构
- 页目录->页表->页框号->物理地址
- 虚拟地址
页目录偏移 页表偏移 页内偏移 - 二级页表可以表示4G的虚拟地址空间(32位计算机)
- 多级页表结构
- 访问多次内存,n级n次,CPU的指令处理速度与内存指令的访问速度差异大,导致CPU的速度得不到充分利用
反转(倒排)页表
很多进程没有对应的物理地址,用地址转换的页表占用内存太大,所以从物理地址空间出发,页表项记录进程i的某虚拟地址(虚页号)与页框号的映射关系;所以整个系统一张页表
反转页表大小与实际内存成固定比例,与进程数无关;
存在的问题:
- 虚拟地址转换成物理地址的时候,则要查找整个页表(消耗过大);
- 解决方法:运用hash列表,通过拉链解决hash中的冲突问题虚拟地址到物理地址的转换变得困难得多。
- 对每一次内存引用,都要搜索倒排页表
快表TLB(Translation Look-aside Buffers)
转换检测缓冲区或者相联存储器(associative memory按内容并行查找)或者快表
TLB即translation look-aside Buffers转换检测缓冲区,是一个小型的硬件设备,将虚拟地址直接映射到物理地址,不必再访问页表。它通常存在MMU中,包含少量的表项,每个表项记录了一个页面的相关信息,包括虚拟页号、页面的修改位、保护码(读/写/执行权限)和该页所对应的物理页框。它是一个内存管理单元用于改进虚拟地址到物理地址转换速度的缓存,它的管理和失效处理由MMU硬件实现
为了解决多级页表需要访问多次内存的情况,根据程序访问的局部性原理而引入快表
快表:在CPU中引入的高速缓存(cache),可以匹配CPU的处理速度和内存的访问速度,一种随机存取型存储器
快表的空间是有限的(并且由于成本大,空间小),它通常位于MMU内部,一般保存正在运行进程的页表的子集(部分页表项),条目很少
过程:先找TLB,找到TLB hit;否则TLB miss,接着查找页表,如果页面还没有读入内存,产生异常page fault,进入操作系统,需要从磁盘中调入,再……从TLB中淘汰一个表项,然后用新找到的页表表项替换它
上述TLB管理和处理TLB失效都完全是由MMU硬件来实现的,但是现代的许多RISC机器,几乎完全采用软件页面管理
切换进程后,TLB会被清空
页错误Page Fault
又称 页面错误、页故障、页面失效,是地址转换过程中硬件产生的异常
具体原因:
- 所访问的虚拟页面没有调入物理内存——缺页异常
- 在地址映射过程中,硬件检查页表时发现所要访问的页面不在内存,则产生该异常
- 操作系统执行缺页异常处理程序:获得磁盘地址,启动磁盘,将该页调入内存
- 如果内存中有空闲页框,则分配一个页框,将新调入页装入,并修改页表中相应页表项的有效位及相应的页框号
- 若内存中没有空闲页框,则要置换内存中某一页框;若该页框内容被修改过,则要将其写回磁盘
- 页面访问违反权限(读/写、用户/内核)
- 错误的访问地址
- ……
处理:
- 硬件陷入内核,在堆栈中保存程序计数器
- 启动一个汇编代码例程,保存通用寄存器和其他易失的信息,以免被操作系统破坏
- 当操作系统发现一个页面失效时,试图查找需要哪个虚拟页面
- 操作系统检查发生页面失效的虚拟地址是否有效,并检查存取与保护是否一致
- 如果选择的是“脏”页帧,安排将该页面写回磁盘
- 一旦页帧“干净”后,操作系统查找所需页面在磁盘上的地址,通过磁盘操作将其装入
- 当磁盘中断发生,表明该页面已经装入时,页表也已更新以反映它的位置,页帧也标记为通常的状态
- 恢复发生页面失效指令以前的状态,程序计数器重新指向这条指令
- 调度页面失效进程,操作系统返回调用它的汇编语言例程
- 该例程恢复寄存器和其他状态信息,回到用户空间继续执行
驻留集
操作系统分配给进程的页框数
- 固定分配策略(进程创建时确定,根据进程类型或者程序员需要来设定)
- 可变分配策略(根据缺页率评估进程局部性表现+系统开销)
置换问题
置换范围:
- 局部置换策略(仅在产生本次缺页的进程的驻留集中选择)
- 可以有效地为每个进程分配固定的内存片段
- 全局置换策略(将内存中所有未锁定的页框都作为置换的候选)
- 在可运行的进程之间动态的分配页框,因此分配给各个进程的页框数是随时间变化的
置换策略:(基于过去的行为来预测将来的行为)
【置换策略设计得越精致、越复杂,实现的软硬件开销就越大】
页框锁定:避免产生由交换过程带来的不确定的延迟
例如:操作系统核心代码、关键数据结构、I/O缓冲区
清除策略:从进程的驻留集中收回页框
因为,虚拟页式系统工作的最佳状态:发生缺页异常时,系统中有大量的空闲页框
所以,在系统中保存一定数目的空闲页框供给比使用所有内存并在需要时搜索一个页框有更好的性能
分页守护进程:多数时间睡眠,可定期唤醒以检查内存的状态
如果空闲页框过少,分页守护进程通过预定的页面置换算法选择页面换出内存;如果页面装入内存后被修改过,则将它们写回磁盘分页守护进程可保证所有的空闲页框是“干净”的。
页缓冲技术
当进程未结束,需要使用一个已置换出的页框时,如果页框还没有被新的内容覆盖,将它从空闲页框集合中移出即可恢复该页面
不丢弃置换出的页,将它们放入两个表之一(根据是否修改);被修改的页定期写回磁盘(一批一批的写,而不是一次只写一个,减少了I/O操作的数量,从而减少了磁盘访问时间)
被置换的页仍然保留在内存中,一旦进程又要访问该页,可以迅速将它加入该进程的驻留集合(代价很小)
影响缺页次数的因素
- 页面置换算法
- 页面本身的大小
- 小页面大小
- 优点
- 内部碎片少(内部碎片)
- 更适合各种数据结构,代码部分
- 内存中少没用的程序
- 坏处
- 程序需要很多页面,更大的页面表
- 优点
- 内部碎片
- 页表长度
- 辅存的物理特性
- 最优页面大小$P=\sqrt{2se}$,其中s是进程的平均规模,e是页表项的长度
- 开销overhead
- $overhead=\frac{s*e}{p}+{\frac p 2}$
- s : average process size in bytes进程平均大小为s个字节
- p : page size in bytes页面大小为p个字节
- e : page entry每个页表项需要e个字节
- 前面一项是页表的开销,后面是内部碎片的开销
- 小页面大小
- 程序的编制方法
- 例如按行按列分配的时候,按列分配,每次这一行都要重新缺页
- 分配给进程的页框数量
颠簸(Thrashing,抖动):虚存中,页面在内存与磁盘之间频繁调度,使得调度页面所需的时间比进程实际运行的时间还多,这样导致系统效率急剧下降,这种现象称为颠簸或抖动
页面置换算法
There are four times when the OS has paging-related work to do:
- Process creation time进程创建
- Process execution time进程执行
- Page fault页错误
- Process termination time进程终止
OPT最佳页面置换算法
置换以后不再需要的或最远的将来才会用到的页面
不可实现的,但是可以作为一种标准来衡量其他算法的性能
FIFO先进先出算法
选择在内存中驻留时间最长的页并置换它
实现:页面链表法
缺点:内存中驻留时间最长的页可能经常使用
BELADY现象
FIFO页面置换算法会产生异常现象(Belady现象),即:当分配给进程的物理页面数增加时,缺页次数反而增加
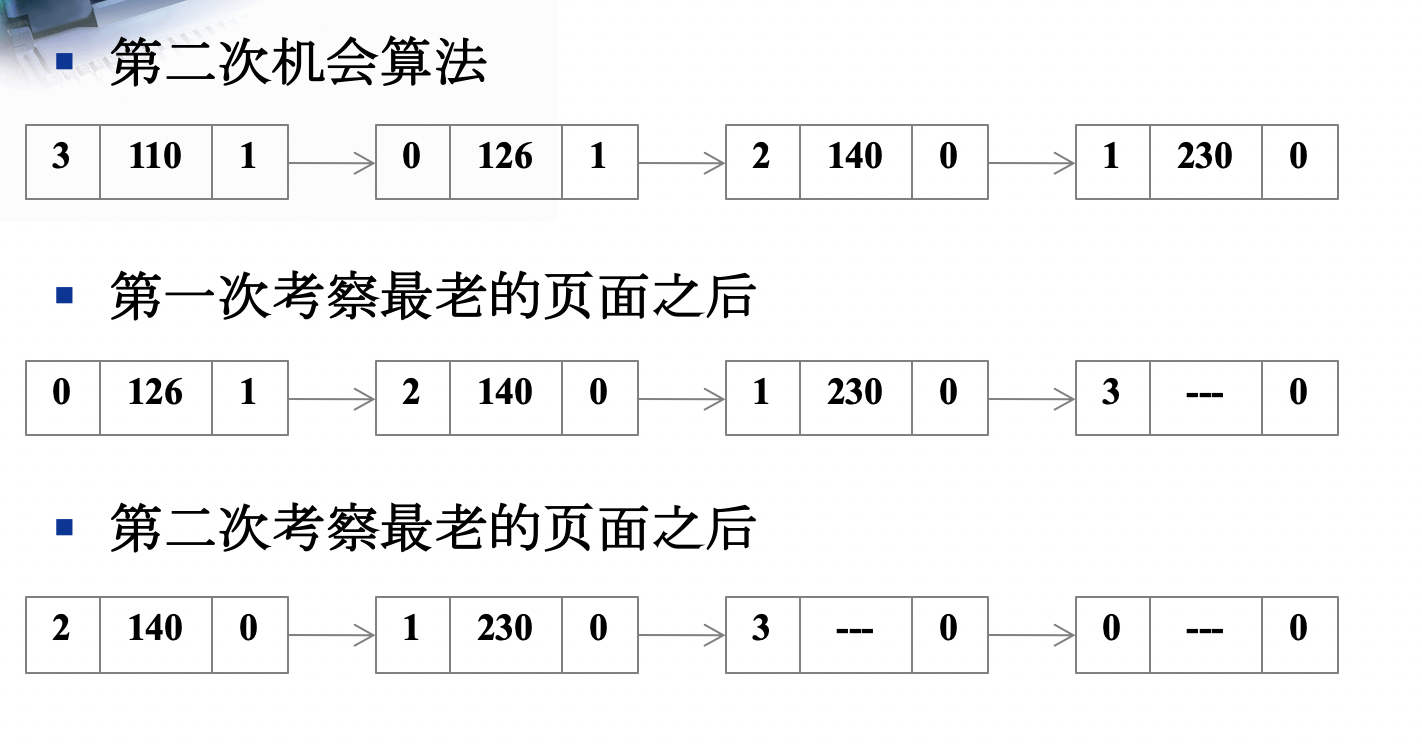
SCR-Second Chance第二次机会算法
按照先进先出算法选择某一页面,检查其访问位R,如果为0,则置换该页;如果为1,则给第二次机会,并将访问位置0
摘链,挂链都需要开销
CLOCK时钟算法实现
通过移动指针来选择下一个页面
NRU-Not Recently Used最近未使用算法
选择在最近一段时间内未使用过的一页并置换
实现:设置页表表项的两位(访问位R,修改位M)
R位被定期清零(复位),初始均为0;
第一类:无访问,无修改
第二类:无访问,有修改
第三类:有访问,无修改
第四类:有访问,有修改
随机从编号最小的非空类中选择一页置换
CLOCK时钟算法实现
通过移动指针来选择下一个页面
LRU-Least Recently Used最近最少使用算法
选择最后一次访问时间距离当前时间最长的一页并置换
即置换未使用时间最长的一页
性能接近OPT
实现:时间戳或维护一个访问页的栈——开销大
先行置1,再列置0,最后置换的时候看哪一行最小
NFU-Not Frequently Used最不经常使用算法
选择访问次数最小的页面置换
LRU的一种软件解决方案
实现:
- 软件计数器,一页一个,初值为0
- 每次时钟中断时,计数器加R
- 发生缺页中断时,选择计数器值最小的一页置换
AGING老化算法
改进LRU
计数器在加R前先右移一位,R位加到计数器的最左端
选择,最小的一个置换出去
工作集算法
开销大,但是很多操作系统采用了这种算法
根据程序的局部性原理,一般情况下,进程在一段时间内总是集中访问一些页面,这些也页面称为活跃页面,如果分配给一个进程的物理页面数太小了,使该进程所需的活跃页面不能全部装入内存,则该进程在运行过程中将频繁发生中断
程序的局部性原理:
程序在一段时间内访问相对小的一段地址空间;虚拟内存基于程序的局部性原理而设计的;程序的局部性原理是指程序在执行仅限于程序中的某一部分。相应地,执行所访问的存储空间也局限于某个内存区域
工作集:一个进程当前正在使用的页框集合
工作集$W(t,\Delta)=$该进程在过去的$\Delta$个虚拟时间单位中访问到的页面的集合
内容取决于三个因素:
- 访页序列特性
- 时刻t
- 工作集窗口长度($\Delta$),窗口越大,工作集就越大
基本思路:找出一个不在工作集中的页面并置换它
- 每个页表项中有一个字段:记录该页面最后一次被访问的时间
- 设置一个时间值T
- 判断:根据一个页面的访问时间是否落在“当前时间-T”之前或之中决定其在工作集之外还是之内
实现:扫描所有页表项,执行操作
如果一个页面的R位是1,则将该页面的最后一次访问时间设为当前时间,将R位清零
如果一个页面的R位是0,则检查该页面的访问时间是否在“当前时间-T”之前
(1) 如果是,则该页面为被置换的页面
(2) 如果不是,记录当前所有被扫描过页面的最后访问时间里面的最小值。扫描下一个页面并重复1、2
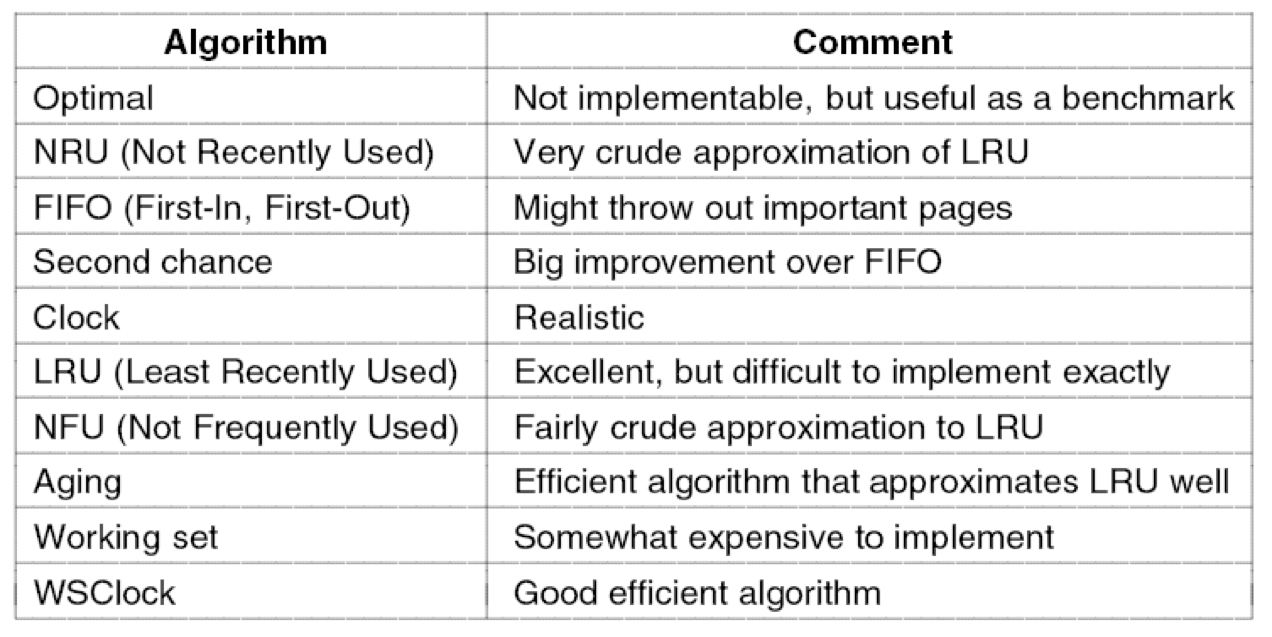
fairly crude approximates相当粗略的近似
内存映射文件
基本思想:进程通过一个系统调用(比如:linux中mmap)将一个文件(或部分)映射到其虚拟地址空间的一部分,访问这个文件就像访问内存中的一个大数组,而不是对文件进行读写
在多数实现中,在映射共享的页面时不会实际读入页面的内容,而是在访问页面时,页面才会被每次一页的读入,磁盘文件则被当作后备存储
当进程退出或显式地解除文件映射时,所有被修改页面会写回文件
写时复制技术
比如:linux中,在fork之后exec之前两个进程用的是相同的物理空间(内存区),子进程的代码段、数据段、堆栈都是指向父进程的物理空间,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。
当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间,如果不是因为exec,内核会给子进程的数据段、堆栈段分配相应的物理空间(至此两者有各自的进程空间,互不影响),而代码段继续共享父进程的物理空间(两者的代码完全相同)。而如果是因为exec,由于两者执行的代码不同,子进程的代码段也会分配单独的物理空间。
quiz 7 错题和模糊题
选择4

选择1 2 4 5
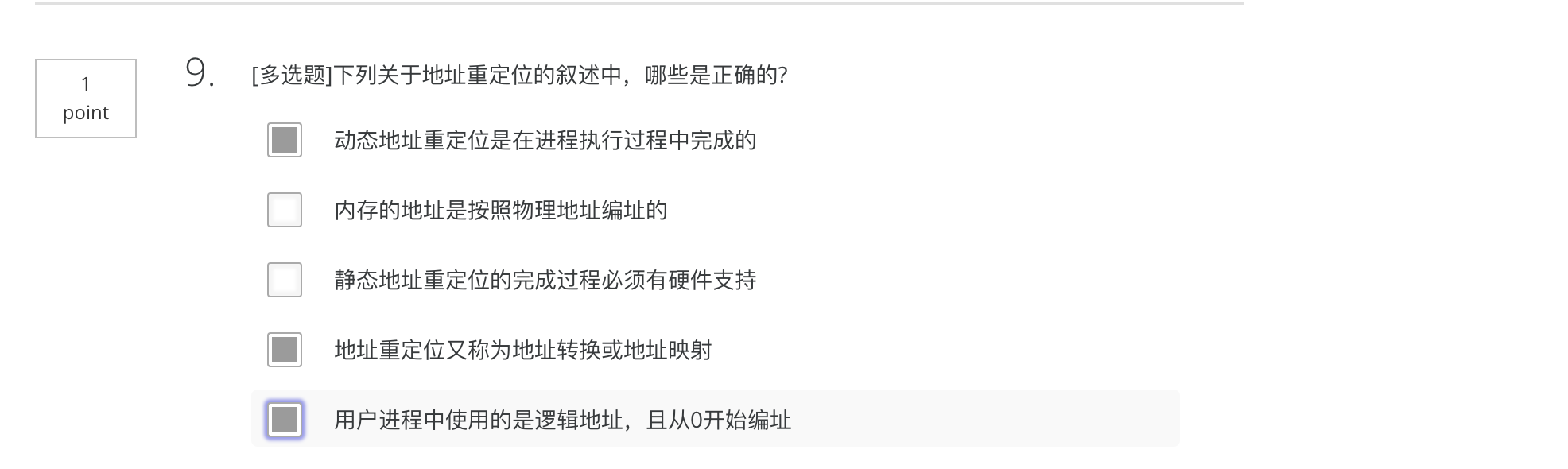
quiz 8 错题和模糊题
正确

应选择1
页面大小= 4KB = 2^12B ,则页内偏移=12位
一页可存放页表项个数 = 4KB / 4B = 1024 = 2^10
采用三级页表,则虚页号 = (2^10) (2^10) (2^10) = 2^30
虚拟地址 = (2^30) * (2^12) = 2^42

应选择4

应选择3

- 正确 14. 应选择1 2 3 5

应如图选择


PPT练习题
Consider the following page-request string in Demand Paging system:
1,2,3,4,5,3,4,1,6,7,8,7,6,3,2,1,2,3,6
How many page faults would occur for the following replacement algorithms, assuming four frames? Remember that all frames are initially empty, so your first unique pages will all cost one fault each.
(1) LRU replacement
(2) Optimal replacement分析:12,10
设某进程的执行过程中有以下的页面号引用串(页面走向):4, 3, 2, 1, 4, 3, 5, 4, 3, 2, 1, 5
(1)当为进程分配3个页帧时,分别给出采用OPT(最优页面置换)、FIFO、LRU算法时的页面置换过程。 (2)当为进程分配4个页帧时,分别给出采用FIFO、LRU算法时的页面置换过程分析:7、9、10、10、8
如果某进程使用5个虚拟页面(编号从0到4),页面访问次序为012301401234。采用FIFO页面置换算法,在分配4个页帧和3个页帧时,分别会产生多少次页面失效。假设初始时页帧是空的
分析:10,9
Consider a swapping system in which memory consists of the following hole size in memory order: 10KB, 4KB, 20KB, 18KB, 7KB, 9KB, 12KB, and 15KB. Which hole is taken for successive segment requests of 12KB, 10KB, 9KB for first fit? Now repeat for best fit, worst fit and next fit
分析:20,10,18;12,10,9;20,18,15;20,18,9
对于下面的每个十进制虚拟地址,分别使用4KB和8KB的页面计算机虚拟页号和偏移量:20000, 32768, 60000
分析:
| | 4 | KB | 8 | KB |
| ———— | :——: | :——: | :——: | ——— |
| 虚拟地址 | 页面号 | 偏移量 | 页面号 | 偏移量 |
| 20000 | 4 | 3616 | 2 | 3616 |
| 32768 | 8 | 0 | 4 | 0 |
| 60000 | 14 | 2656 | 7 | 2656 |一个32位地址的计算机使用两级页表。虚拟地址被分成9位的顶级页表域、11位的二级页表域和一个偏移量,页面大小是多少?在地址空间中一共有多少个页面?
分析:32-9-11=12位,所以页面大小4KB;2^9*2^11=2^20个页面
一个计算机有4个页帧,装入时间、上次访问时间和每个页面的R位和M位如下表所示(时间以时钟滴答为单位)
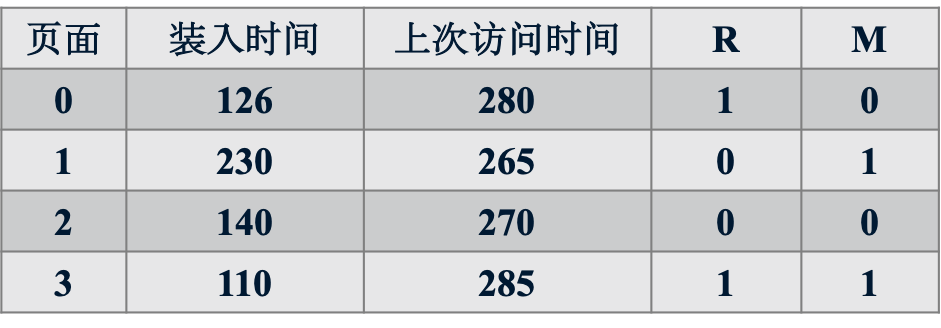
(1) NRU算法将置换哪个页面?
(2) FIFO算法将置换哪个页面?
(3) LRU算法将置换哪个页面?
(4) 第二次机会算法将置换哪个页面?2;3;1;2
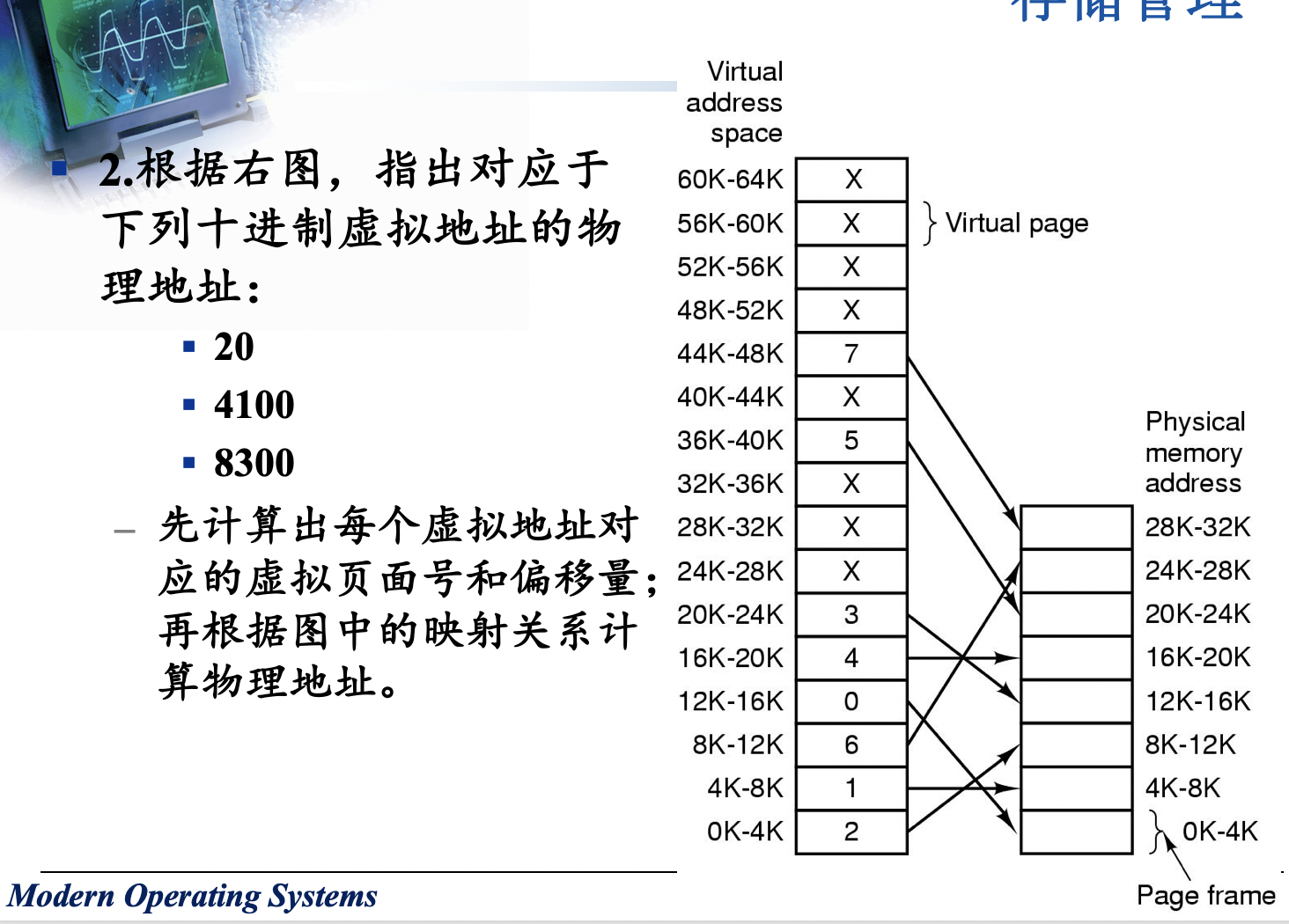
首先计算20:页面号0,偏移量20;4100:页面号1,偏移量4;8300:页面号2,偏移量108
根据映射,知道0对应2,所以物理地址是8k+20=8212;1对应1,所以物理地址是4k+4=4100;2对应6,所以物理地址是24k+108=24684
文件系统
文件
文件是对磁盘的抽象(进程是对CPU的抽象,地址空间是对内存的抽象)
文件: 一组带标识的(标识即为文件名)、在逻辑上有完整意义的信息项的序列
信息项:构成文件内容的基本单位(单个字节或多个字节),各信息项之间具有顺序关系
分类:
- 普通文件
- 用户建立的
- 包含了用户的信息,一般为ASCII或二进制文件
- 目录文件
- 操作系统建立的
- 为了管理文件系统的系统文件
- 特殊文件(设备文件)
- 字符设备文件:和输入输出有关,用于模仿串行I/O设备,例如终端,打印机,网卡等
- 块设备文件:磁盘(若干个字节来进行检索和传输)
- 管道文件
- 套接字
文件逻辑结构:
从用户角度看文件,由用户的访问方式确定
- 流式文件
- 构成文件的基本单位是字符
- 文件是有逻辑意义、无结构的一串字符的集合
- 只可以一个一个读,一个一个写
- 记录式文件(例如目录文件)
- 文件由若干个记录组成,可以按记录进行读、写、查找等操作
- 每条记录有其内部结构
文件存取:
- 顺序存取(访问)
- 随机存取(访问)
- 提供读写位置(当前位置)
- 例如unix的seek操作
- 提供读写位置(当前位置)
文件的存储介质
磁盘(包括固态盘SSD)
- 磁盘的物理块号与磁盘地址可以相互转换
- 读写磁头:一个盘面一个
- 任何时刻只有一个磁头处于活动状态:输入输出数据流以位串形式出现
- 盘面上的同心圆:磁道
- 扇区:磁道划分成很多段;信息存放在扇区里
- 标题+数据(通常512字节)+ECC纠错信息
- 坏扇区
- 在控制器中处理它们
- 最后加入用备用品代替坏道
- 转移所有扇区(避开坏块),在坏块之后加入备用品
- 在操作系统中处理它们
- 如果操作系统正在处理重映射,则必须确保在任何文件中都不会出现坏扇区,并且也不会在空闲列表或位图中出现
- 一种方法是创建一个由所有坏扇区组成的秘密文件
- 如果磁盘是逐个文件备份的,则备份实用程序不要尝试复制坏块文件,这一点很重要
- 在控制器中处理它们
- 把一个给定的磁盘臂位置上的所有磁道合并起来,组成了一个柱面(cylinder)
- 物理地址:磁头号(盘面号)、磁道号(柱面号)、扇区号
- 磁盘访问
- 磁盘调度时,首先是移臂调度,然后是旋转调度
- 一次访盘请求:读/写,磁盘地址(设备号,柱面号,磁头号,扇区号),内存地址(源/目)
- 三个动作(对于SSD只有最后一个,前面两个不存在)
- 寻道(时间):磁头移动定位到指定磁道【一般这个占主要部分】
- 大多数硬盘控制器会自动纠正寻道错误
- 旋转延迟(时间):等待指定扇区从磁头下旋转经过
- 数据传输(时间):数据在磁盘与内存之间的实际传输
- 寻道(时间):磁头移动定位到指定磁道【一般这个占主要部分】
- 稳定存储器使用一对完全相同的磁盘,对应的块一同工作以形成一个无差错的块
- 当不存在错误时,在两个驱动器上对应的块是相同的
- 稳定存储器定义了3种操作:
- Stable writes(稳定写)
首先将块写到驱动器1上,然后将其读回以校验写的是正确的。如果不正确,就再次做写和重读操作
对驱动器1的写成功之后,对驱动器2上对应的块进行写和重读 - Stable reads(稳定读)
首先从驱动器1上读取块。若始终无法正确读取,则从驱动器2上读取对应的块 - Crash recovery(崩溃恢复)
恢复程序扫描两个磁盘并比较对应的块
如果一对块都是好的并且相同,什么都不做
如果其中一个有错,用对应的好块来覆盖坏块
如果一对块都是好的但不相同,将驱动器1上的块写到驱动器2上
- Stable writes(稳定写)
- 磁带
- Magnetic Disks
- 现代磁盘被划分为区域,外部区域上的扇区多于内部区域
- cylinder skew(柱面斜进)在设置低级格式时,每个磁道上第0扇区的位置与前一个磁道存在偏移,让磁盘在一次连续的操作中读取多个磁道而不丢失数据
- 格式化磁盘时以交错(交错)方式对扇区编号,扇区0包含主引导记录(主引导记录):一些启动代码,分区表(给出每个分区的起始扇区和大小);要从硬盘引导,必须在分区表中将一个分区标记为活动
- 最后一步是准备一个磁盘,用于执行每个分区的高级格式化,设置引导块,空闲存储管理,根目录和一个空文件系统
- RAID
- CD-ROMs
- CD-Recordable
- CD-Rewritable
- DVD
光盘
U盘
物理块(block、cluster)
- 信息存储、传输、分配的独立单位
- 存储设备划分为大小相等的物理块,统一编号
文件系统
操作系统中统一管理信息资源的一种软件,管理文件的存储、检索、更新,提供安全可靠的共享和保护手段,并且方便用户使用
- 统一管理磁盘空间,实施磁盘空间的分配与回收
- 实现文件的按名存取:名字空间【映射到】磁盘空间
- 实现文件信息的共享,并提供文件的保护、保密手段
- 向用户提供一个方便使用、易于维护的接口,并向用户提供有关统计信息
- 提高文件系统的性能
- 提供与I/O系统的统一接口
文件控制块FCB
大小固定的
为管理文件而设置的数据结构,保存管理文件所需要的所有有关信息
文件属性或元数据(即数据的数据)
常用属性:
文件名,文件号,文件大小,文件地址,创建时间,最后修改时间,最后访问时间,各种标志等等
文件目录
- 统一管理每个文件的元数据,以支持文件名到文件物理地址的转换
- 将所有文件的管理信息组织在一起,即构成文件目录
- 按名存取
目录文件:将文件目录以文件的形式存放在磁盘上
目录项:
- 构成文件目录的基本单元
- 目录项可以是FCB,目录是文件控制块的有序集合
路径名(文件名):绝对/相对路径名
当前/工作目录
- 1层目录系统
- 优点:简单,能够快速定位文件
- 坏处:在具有多个用户的系统中,不同用户为自己的文件选择相同的文件名会导致冲突
- 2层目录系统
- 增加了中间的用户层
- 可以缩短访问文件存储器时间
- 多层目录系统
管理文件目录的系统调用
- Create
- mDelete
- Opendir
- Closedir
- Readdir
- Rename
- Link
- Uplink
文件的物理结构
文件在存储介质上的存放方式
顺序(连续)结构
文件的信息存放在若干连续的物理块中
FCB记录文件的第一块的地址+文件长度
优点:
- 简单
- 支持顺序存取和随机存取
- 所需的磁盘寻道次数和寻道时间最少
- 可以同时读入多个块,检索一个块也很容易
缺点:
- 文件不能动态增长
- 可以通过预留空间(但是会浪费)或重新分配和移动
- 不利于文件插入和删除(CD-ROM适合这种方法,
- 外部碎片:紧缩技术
链接结构
一个文件的信息存放在若干不连续的物理块中,各块之间通过指针连接,前一个物理块指向下一个物理块
FCB记录文件的第一块的地址
优点:
- 提高了磁盘空间利用率,不存在外部碎片问题
- 有利于文件插入和删除
- 有利于文件动态扩充
缺点:
- 存取速度慢,不适于随机存取
- 可靠性问题,如指针出错
- 更多的寻道次数和寻道时间
- 链接指针占用一定的空间
文件分配表FAT
变形:将链接指针的内容都存放在FAT中,块中存放文件的下一个的地址(0表示空闲,-1表示文件的最后一块了,其余表示下一块块号)
FCB记录起始块号
缺点是必须把整个表都放在内存中
索引结构
- 一个文件的信息存放在若干不连续物理块中
- 系统为每个文件建立一个专用数据结构——索引表,并将这些物理块的块号存放在索引表中
- 索引表就是磁盘块地址数组,其中第i个条目指向文件的第i块(所以可以随机存取
- 索引块存放索引表
- 如果索引表很大的时候,需要多个索引块的时候:
- 链接方式:一个盘块存一个索引表,多个索引表链接起来
- 多级索引方式:将文件的额索引表地址放在另一个索引表中(unix采用,一般为256的次方个)
- 综合模式:直接索引方式和间接索引方式的结合
- 如果索引表很大的时候,需要多个索引块的时候:
优点:
保持了链接结构的优点,又解决了其缺点
- 既能顺序存取,又能随机存取
- 满足了文件动态增长、插入删除的要求
- 能充分利用磁盘空间
缺点:
- 较多的寻道次数和寻道时间
- 索引表本身带来了系统开销:如:内存、磁盘空间、存取时间
i-node
FAT正比于磁盘大小;i节点正比于同时打开的最大文件个数,与磁盘大小无关
保存文件的块号,保存各个子目录的文件块号
元数据+数据块
- 为每个文件赋予一个i节点
- 每个i节点都有固定数量的磁盘地址空间;当文件超出此限制时,将出现问题,可以将最后一个磁盘块地址不指向数据块,而是指向一个包含额外磁盘块地址的块的地址
- 记录文件块的属性和磁盘地址
- 在i节点中存储文件属性
- 每个目录条目包括文件名和索引节点号
优点:
- 只有在文件打开时,才在内存中
- 该数组远小于FAT,其大小与一次打开的最大文件数成比例
共享文件系统Shared Files
共享文件通常同时出现在属于不同用户的不同目录中,方便多个用户访问
目录和共享文件之间的连接称为链接
文件系统本身是有向无环图(DAG)
问题:导致一个对共享文件的修改,其他用户看不到
解决方案:
- 磁盘块未列在目录中,而是列在与文件本身关联的小数据结构(i节点)中
- i节点中记录一些属性:所有者,链接数count(如果硬连接,会动态变化)
- 不会改变文件的所有权
- 软连接中:如果文件所有者删除了文件,则其他可共享的用户将会指向一个无效的i节点(目录条目);硬连接中,无影响
- 硬链接就是同一个文件使用了多个别名(它们有共同的inode),由于硬链接是有相同inode号仅文件名不同的文件,因此删除一个硬链接文件并不影响其他有相同inode号的文件,硬链接不能对目录进行创建,只可对文件进行创建。
- 软连接:也叫符号链接,文件用户数据块中存放的内容是另一文件的路径名的指向,软连接就是一个普通文件,只是数据块内容有点特殊,软链接可以对文件或目录创建
- 通过让系统创建LINK类型的新文件并在B的目录中输入该文件来链接到A的文件
- 新文件仅包含与其链接的文件的路径名,这种方法称为符号连接
- 符号链接的问题是需要额外的开销
日志文件系统Journaling File Systems
在文件系统执行之前记录文件系统要执行的操作,以便在系统崩溃之前可以执行其计划的工作,在重新启动系统后可以查看日志以查看崩溃时发生的情况 并完成工作,这样的文件系统,称为日志文件系统(journaling file systems)
虚拟文件系统VFS(Virtual File Systems)
尝试将多个文件系统集成到一个有序的结构中,关键思想是抽象出所有文件系统通用的文件系统部分,并将该代码放在一个单独的层中,该层调用底层的具体文件系统来实际管理数据(用户层和虚拟文件系统交互,虚拟文件系统和文件系统交互,作为一个中间层)
示例:Sun Microsystems,UNIX
UNIX文件系统的实现
磁盘分区:把一个物理磁盘存储空间划分为几个相互独立的部分,称为分区
文件卷:磁盘上的逻辑分区,由一个或多个物理块(簇)组成
- 一个文件卷可以是整个磁盘或部分磁盘或跨盘(RAID)
- 同一个文件卷中使用同一份管理数据进行文件分配和磁盘空闲空间管理,不同文件卷中的管理数据是相互独立的
- 一个文件卷上:包括文件系统信息、一组文件(用户文件、目录文件)、未分配空间
- 块(BLOCK)或簇(CLUSTER):一个或多个(2的幂)连续的扇区,可寻址数据块
- 包括了
- 引导区,包括了从该卷引导操作系统所需要的信息,每个卷(分区)一个,通常为第一个扇区
- 卷(分区)信息:包括块(簇)数,块(簇)大小,空闲块(簇)数量和指针,空闲DCB数量和指针
- 目录文件(根目录文件及其他目录文件)
- 用户文件
格式化:在一个文件卷上建立文件系统,即建立并初始化用于文件分配和磁盘空闲空间管理的管理数据(建立元数据)
内存中需要提供的数据结构以支持这个进程对文件的使用:
- 系统打开文件表:整个系统一张,放在内存,用于保存已打开文件的FCB
- 格式:FCB(i节点)信息+引用计数+修改标记
- 用户打开文件表
- 每个进程一个
- 进程的PCB中记录了用户打开文件表的位置
- 格式:文件描述符+打开方式+读写指针+系统打开文件表索引
以UNIX为例:
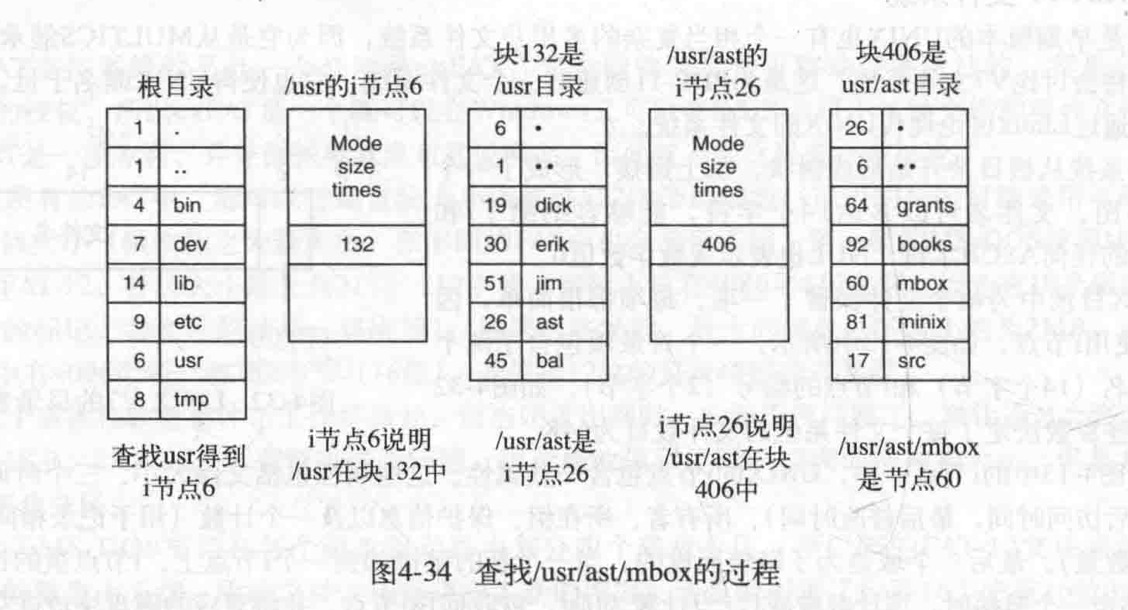
- 目录检索
- 根据用户给出文件名->按文件名查找到目录项/FCB
- 全路径名:从根开始
- 相对路径:从当前目录开始
- 文件寻址
- 根据目录项/FCB中文件物理地址等信息,计算出文件中任意记录或字符在存储介质上的地址
因此,目录检索的速度是关键因素。加快目录检索的解决方案:
- 目录项分解法:即把FCB分成两部分
- 符号目录项:文件名,文件号
- 基本目录项:除文件名外的所有字段
- 例如:UNIX的FCB=目录项 + i节点(索引节点或inode)
- 本目录节点的目录项
.,他自己的i-node - 附目录的目录项
..,他的爸爸的i-node
- 本目录节点的目录项
- 目录文件改进后减少了访盘次数,提高了文件检索速度
 图中的不是物理地址,而是得到所在的物理地址的块
图中的不是物理地址,而是得到所在的物理地址的块
Windows—FAT16文件系统
簇大小为$2^n$个扇区
文件系统的数据记录在“引导扇区”中
对空闲区采用位示图法
文件分配表FAT
可以把文件分配表看成一个整数数组,每个整数代表磁盘分区的一个簇号
状态:未使用、坏簇、系统保留、被文件占用(下一簇簇号)、最后一簇(0xFFFF)
作用:描述簇的分配状态,标注下一簇的簇号等
FAT表项:2字节(16->2*8bit)
目录项:32字节(等效于FCB)
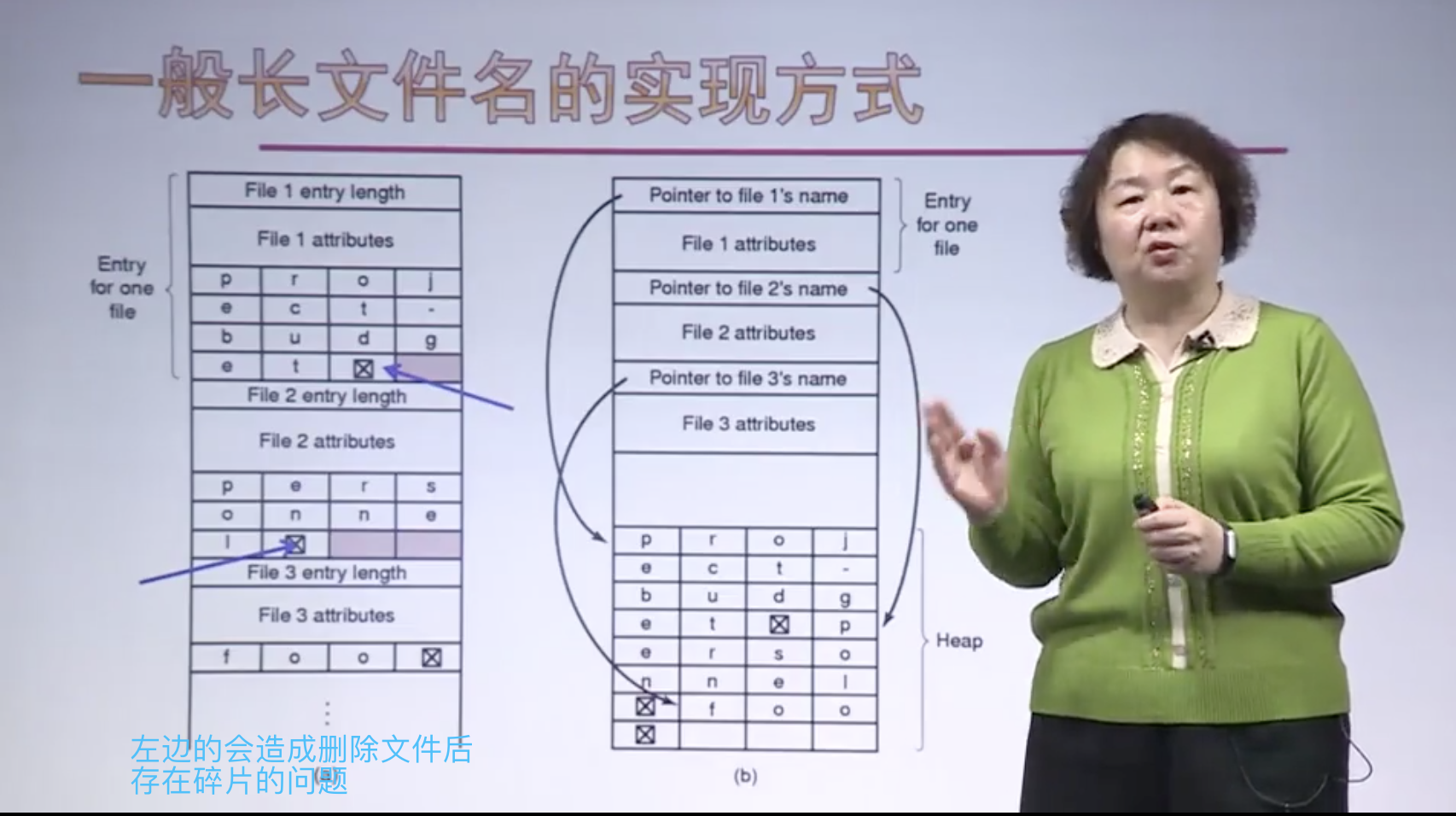
FAT16一个文件对应一个目录项;而对于FAT32长文件名来说,一个文件可能对应多个目录项;其中短文件目录项是必须有的
长文件名的存储
左边的是线性的
- 删除文件时,会在目录中引入可变大小的间隙,下一个要输入的文件可能不适合该目录
- 读取文件时可能会发生页面错误
右边的是堆形的
- 通过hash或者Cache来加速搜索
根目录大小固定(大小信息均在引导扇区中)【在FAT32中,根目录大小不固定了】
文件操作的实现
创建文件
建立系统与文件的联系,实质是建立文件的FCB
- 在目录中为新文件建立一个目录项,根据提供的参数及需要填写相关内容
- 分配必要的存储空间
create(文件名, 访问权限)
- 检查参数的合法性(是否符合命名规则;有无重名文件),若合法,下一步;否则,报错
- 申请空闲目录项,并填写相关内容
- 为文件申请磁盘块
- 返回
打开文件
根据文件名在文件目录中检索,并将该文件的目录项读入内存,建立相应的数据结构(系统打开文件表/用户打开文件表),得到文件描述符/文件句柄(来操作),为后续的文件操作做好准备
fd=open(文件路径名, 打开方式)
- 根据文件路径名查目录,找到目录项(或i节点号)
- 根据文件号查系统打开文件表,看文件是否已被打开;是,则共享计数加1;否则,将目录项(i节点)等信息填入系统打开文件表空表项,共享计数置1
- 根据打开方式,共享说明和用户身份检查访问合法性
- 在用户打开文件表中获取一空表项,填写打开方式等,并指向系统打开文件表对应表项;返回信息:fd——文件描述符,是一个非负整数,用于以后读写文件
指针定位
seek(fd, 新指针的位置)
系统为每个进程打开的每个文件维护一个读写指针,即相对于文件开头的偏移地址(读写指针指向每次文件读写的开始位置,在每次读写完成后,读写指针按照读写的数据量自动后移相应数值)
- 由fd查用户打开文件表,找到对应的表项
- 将用户打开文件表中文件读写指针位置设为新指针的位置,供后继读写命令存取该指针处文件内容
读文件
read(文件描述符, 读指针, 要读的长度, 内存目的地址)
- 根据打开文件时得到的文件描述符,找到相应的文件控制块(目录项);确定读操作的合法性,若合法,进入下一步;否则,出错处理
- 将文件的逻辑块号转换为物理块号;根据参数中的读指针、长度与文件控制块中的信息确定块号、块数、块内偏移
- 申请缓冲区
- 启动磁盘I/O操作,把磁盘块中的信息读入缓冲区,再送到指定的内存区(多次读盘)
- 反复执行3、4直至读出所需数量的数据或读至文件尾

文件系统的管理
文件系统的空间管理
- 固定大小
- 过大,浪费磁盘空间
- 过小,差的性能(增加寻道时间、旋转延迟、数据传输时间等等)
- 已知块号,则磁盘地址:
- 柱面号=[块号/(磁头数x扇区数)]
- 磁头号=[(块号mod(磁头数x扇区数))/扇区数]
- 扇区号(块号mod(磁头数x扇区数))mod扇区数
- 已知磁盘地址:
- 块号=柱面号x(磁头数x扇区数)+磁头号x扇区号+扇区号
- Disk Quotas(磁盘配额)
为防止人们占用太多磁盘空间,多用户操作系统通常提供强制磁盘配额的机制(强制性磁盘配额),系统管理员为每个用户分配最大的文件和块分配,操作系统确保用户不超过他们的配额 - 位图(0/1表示是否被占用)
- 块号=i*字长+j
- 其中字号:i;位号:j
- 存在的问题,每次需要找到连续的k个0,才能找到可以存放的空闲块
- 空闲块表(将所有空闲块记录在一个表中,记录每一个空闲块的起始块号,块数)
- 空闲块链表(把所有空闲块链成一个链)
- 一些短暂的临时文件将会导致不必要的I/O
- 指针块还可能存在溢出
- 解决方法:保持磁盘上的大多数指针块为满的状态,但是在内存中保留一个半满的指针块
- 扩展:成组链接法 UNIX中


文件系统的可靠性
可靠性:抵御和预防各种物理性破坏和人为性破坏的能力
坏块问题
备份(通过转储操作,形成文件或文件系统的多个副本)
全量转储
- 定期将所有文件拷贝到后援存储器
增量转储
- 只转储修改过的文件,即两次备份之间的修改,减少系统开销
- 物理转储
- 从磁盘第0块开始,将所有磁盘块按序输出到磁带
- 缺点:
- 备份未使用的磁盘块没有任何价值
- 避免倾倒坏块
逻辑转储
- 从一个或几个指定目录开始,递归地转储自给定日期后所有更改的文件和目录
- UNIX
操作流程在位图和i节点下
Phase 1
从起始目录开始检查其中的所有目录项
对每一个修改过的文件,算法在位图中标记其i-node
标记并递归检查每一个目录,无论其是否被修改过Phase 2
以递归方式再次遍历树,取消标记任何没有修改过的文件或目录的目录
Phase 3
按数字顺序扫描i节点并转储所有标记为转储的目录
Phase 4
转储标记为转储的文件
文件系统的一致性
源数据的一致性(word文件未保盘,系统奔溃后,这不算)
大多数计算机都有一个检查文件系统一致性的实用程序,如:UNIX – fsck,Windows – Scandisk
所有文件系统检查器都独立于其他文件系统验证每个文件系统
除检查每个块的计数是否正确之外,还检查目录系统
- 创建一张计数器表,每个文件对应一个计数器
- 程序从根目录开始检验,沿着目录层次递归下降,检查文件系统的每个目录
- 对于目录中的每个文件,将文件使用计数器加1(符号连接不计数)
- 检查全部完成后,得到一张由i-node索引的表,说明每个文件被多个目录包含
- 将这些数字与存储在文件i-node中的连接数相比较
问题的产生:
磁盘块->内存->写回磁盘块
若在写回之前,系统奔溃,则文件系统出现不一致
解决方案:
设计一个实用程序,当系统再次启动时,运行该程序,检查磁盘块和目录系统
UNIX存在两张表,初始为0;
表一:记录了每块在文件中出现的次数
表二:记录了每块在空闲块表中出现的次数
两表相互补充,进行恢复
两个都没有:空闲块置1
表二两次:变1
表一两次:增加一块,复制内容,两个为一
文件系统的写入策略
需要考虑文件系统一致性和速度
- 通写(write-through)
- 内存中的修改立即写到磁盘
- 缺点:速度性能差
- 例:FAT文件系统
- 延迟写(lazy-write)
- 利用回写(write back)缓存的方法得到高速
- 可恢复性差
- 可恢复写(transaction log)
- 采用事务日志来实现文件系统的写入
- 既考虑安全性,又考虑速度性能
文件系统的安全性
文件保护机制
- 用于提供安全性、特定的操作系统机制
- 对拥有权限的用户,应该让其进行相应操作,否则,应禁止
- 防止其他用户冒充对文件进行操作
实现:
- 用户身份验证
- 访问控制
- 主动控制:访问控制表
- 每个文件一个
- 记录用户ID和访问权限(没有ID即没有权限)
- 用户可以是一组用户
- 文件可以是一组文件
- 能力表(权限表)
- 每个用户一个
- 记录文件名及访问权限
- 用户可以是一组用户
- 文件可以是一组文件
- 主动控制:访问控制表
UNIX:文件的二级存取控制(审查用户的身份、审查操作的合法性)
- 对用户分类
- 文件主(owner)
- 文件主的同组用户(group)
- 其他用户(other)
- 对操作分类
- 读操作(r)
- 写操作(w)
- 执行操作(x)
- 不能执行任何操作(-)
比如711,则文件主可读可写可执行,而同组用户和其他用户只可以执行;
比如755,则文件主可读可写可执行,而同组用户和其他用户可读可执行101
文件系统的性能
磁盘服务->速度成为系统性能的主要瓶颈之一,所以需要尽可能减少磁盘访问次数
提高文件系统性能的方法:
- 目录项(FCB)分解
- 当前目录
- 磁盘碎片整理
- 磁盘的扇区0称为MBR(主引导记录),MBR的末尾包含分区表(分区表)
当计算机启动时,BIOS读入并执行MBR
MBR程序首先是找到活动分区,读取它的第一个块,称为引导块,然后执行它
引导块中的程序加载该分区中包含的操作系统
为了统一,每个分区都以引导块开始 - 块高速缓存(BLOCK CACHE)
- 又称为文件缓存、磁盘高速缓存、缓冲区高速缓存
- 是指:在内存中为磁盘块设置的一个缓冲区,保存了磁盘中某些块的副本
- 过程
- 检查所有的读请求,看所需块是否在块高速缓存中
- 如果在,则可直接进行读操作;否则,先将数据块读入块高速缓存,再拷贝到所需的地方
- 由于访问的局部性原理,当数据块被读入块高速缓存以满足一个I/O请求时,很可能将来还会再次访问到这一数据块
- 实现
- 块高速缓存的组织(通过Hash table+链表来维护)
- 块高速缓存的置换(修改LRU)【每一次放到队尾;如果不久后再次使用,也要靠队尾放置】
- 块高速缓存写入策略【该块是否会影响文件系统的一致性】
- 立即写/回写
- 缓冲区高速缓存(buffer caching)
- 磁盘调度
- 当有多个访盘请求等待时,采用一定的策略,对这些请求的服务顺序调整安排,来降低平均磁盘服务时间,达到公平、高效
- 公平:一个I/O请求在有限时间内满足
- 高效:减少设备机械运动带来的时间开销
- 一次访盘时间=寻道时间+旋转延迟时间+传输时间
- 减少寻道时间
- 减少延迟时间
- 当有多个访盘请求等待时,采用一定的策略,对这些请求的服务顺序调整安排,来降低平均磁盘服务时间,达到公平、高效
- 块提前读,又称为提前读取预取
- 每次访问磁盘的时候,多读入一些磁盘块(根据程序执行的空间局部性原理),从而提高命中率
- 开销:较小(只有数据传输时间)
- 具有针对性,只适用于顺序读取的文件
- 合理分配磁盘空间,减少磁盘臂的移动
- 分配磁盘块时,把有可能顺序存取的块放在一起
- 尽量分配在同一柱面上,从而减少磁盘臂的移动次数和距离
- 信息的优化分布
- 记录在磁道上的排列方式也会影响输入输出操作的时间
- 比如:处理也需要时间,这样对于需要顺序处理的第二个,不应该放在毗邻的位置,而是应该在处理之后磁盘转到的新位置更加合理
- RAID技术 (独立磁盘冗余阵列)
- Redundant Arrays of Independent Disks
- 多块磁盘按照一定要求构成一个独立的存储设备
- 目标:提高可靠性和性能
- 组织
- 通过把多个磁盘组织在一起,作为一个逻辑卷提供磁盘跨越功能
- 通过把数据分成多个数据块,并行写入/读出多个磁盘,以提高数据传输率(数据分条stripe)
- 通过镜像或校验操作,提供容错能力(冗余)
- RAID 0,条带化,数据分布在阵列的所有磁盘上,有数据请求时,同时多个磁盘并行操作,充分利用总线带宽,数据吞吐率提高,驱动器负载均衡,无冗余(即差错控制),性能最佳
- RAID 1,镜像,最大限度保证数据安全及可恢复性,所有数据同时存放在两块磁盘的相同位置,磁盘利用率50%,数据安全性最好
- RAID 4,交错块奇偶校验,以数据块为单位,综合,提高了性能和安全性
- 记录的成组与分解
- 记录的成组
- 把若干个逻辑记录合成一组存放一块的工作
- 进行成组操作时必须使用内存缓冲区,缓冲区的长度等于逻辑记录长度乘以成组的块因子(缓冲区的大小)
- 成组的目的:提高了存储空间的利用率,减少了调动外设的次数,提高了系统的工作效率
- 记录的分解:从一组逻辑记录中把一个逻辑记录分离出来
- 典型例子:目录文件
- 记录的成组
磁盘调度算法
先来先服务FCFS
按访问请求到达的先后次序服务
优点:简单,公平
缺点:效率不高,相邻两次请求可能会造成最内到最外的柱面寻道,使磁头反复移动,增加了服务时间,对机械也不利
最短寻道时间优先Shortest Seek Time First
优先选择距当前磁头最近的访问请求进行服务,主要考虑寻道优先
优点:改善了磁盘平均服务时间
缺点:造成某些访问请求长期等待得不到服务(远离中间的请求可能得不到服务)
扫描算法SCAN(电梯算法elevator algorithm)
当设备无访问请求时,磁头不动;
当有访问请求时,磁头按一个方向移动,在移动过程中对遇到的访问请求进行服务,然后判断该方向上是否还有访问请求,如果有则继续扫描;否则改变移动方向,并为经过的访问请求服务,这种算法权衡了距离、方向
优点:对任意的一组给定请求,磁盘臂移动总次数的上界是固定的:正好是柱面数的2倍
单向扫描调度算法C-SCAN(循环算法)
每次从0号柱面开始向里扫描
返回时不为任何的等待访问者服务
减少了新请求的最大延迟
#N-step-SCAN策略
把磁盘请求队列分成长度为N的子队列,每一次用SCAN处理一个子队列
当N较大时,相当于SCAN;N=1,即FCFS
克服“磁头臂”的粘性
#FSCAN
两个队列,老的和新的,可以克服“磁头臂”的粘性
#旋转调度算法
根据延迟时间来决定执行次序的调度
扇区近的先来,相同的话,随机选择一个,另一个则要转一圈后才可以轮到,所以可能中间还会夹杂别的扇区的
quiz 9 错题和模糊题
应选择3
文件的逻辑结构是指文件的外部组织形式,即从用户角度看到的文件的组织形式。因此文件的逻辑结构是由用户决定的

应选择3
文件系统的一个最大特点是“按名存取”,用户只要给出文件的符号名就能方便地存取在外存空间的文件信息,而不必关心文件的具体物理地址。而实现文件符号名到文件物理地址映射的主要环节是检索文件目录。

应选择4 和 1
对于第4题:文件控制块中包含的信息有:文件号、文件名、文件的物理位置、文件的逻辑结构、文件的存取控制权限、文件的建立日期和时间以及文件的修改日期和时间、当前已打开该文件的进程数及是否被进程锁住等。
文件在内存中的位置会改变,不属于文件本生的属性和信息
对于第5题:目录项分解法中,就分解为了符号目录项和基本目录项了!
应选择4
文件系统存储空间共有块数$2^{42}/2^{10}=2^{32}$。为表示$2^{32}$个块号,一个索引表项至少要32位,$32b=4B$。$512$字节可存放$2^7$个索引表项,故最大文件长度:$2^7×2^{10}=2^{17}B=128 KB$。

应选择3 第九题如图
每个索引表相当于一个物理块,有$2^10 / 2^2 = 2^8$ 个索引项,由题可知,前六个直接索引指向6个物理块,而第七个一级索引有$undefined$ 个索引项指向 $undefined$个物理块,同理,第八个二级索引指向 $2^8 * 2^8 = 2^16$ 个物理块,第九个三级索引指向$undefined$个物理块,第十个四级索引指向$undefined$个物理块。
第九题,采用算法前,一个盘块可以放1024/128=8个目录项,254/8=32个目录块,所以平均访问时间为16.5次;采用算法后,一个盘块可以放1024/20=51个目录项,这样254/51=5个目录块,所以平均查找一个目录项需访问磁盘(1+5)/2+1=4次
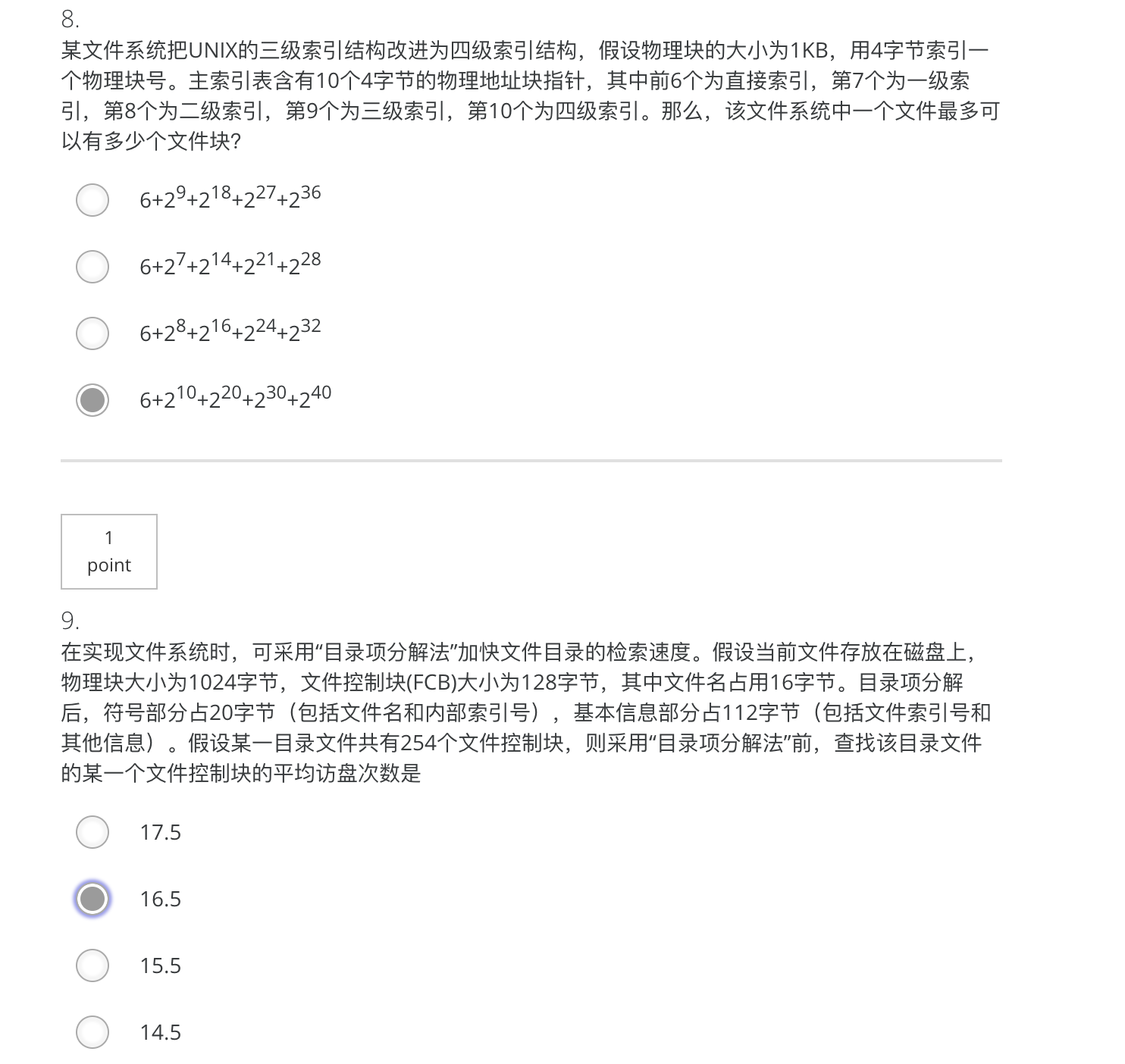
11 题如图 12题应选择1345
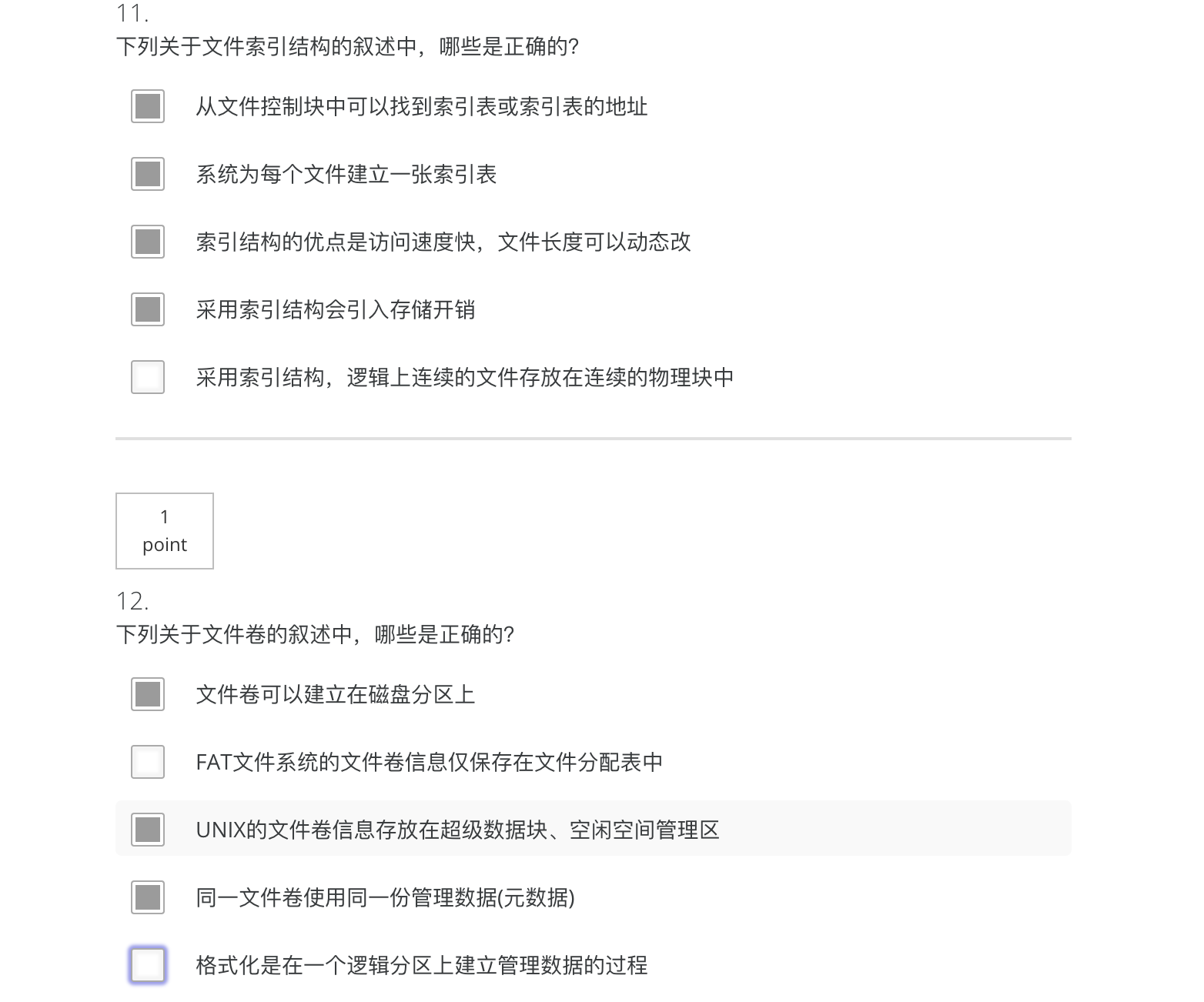
13应选择“错”
应是(链接结构)是文件系统中可以采用的文件的物理结构
而成组链接法是一种扩展思想
15应选择“对” 16选择对

quiz 10 错题和模糊题
练习1dh

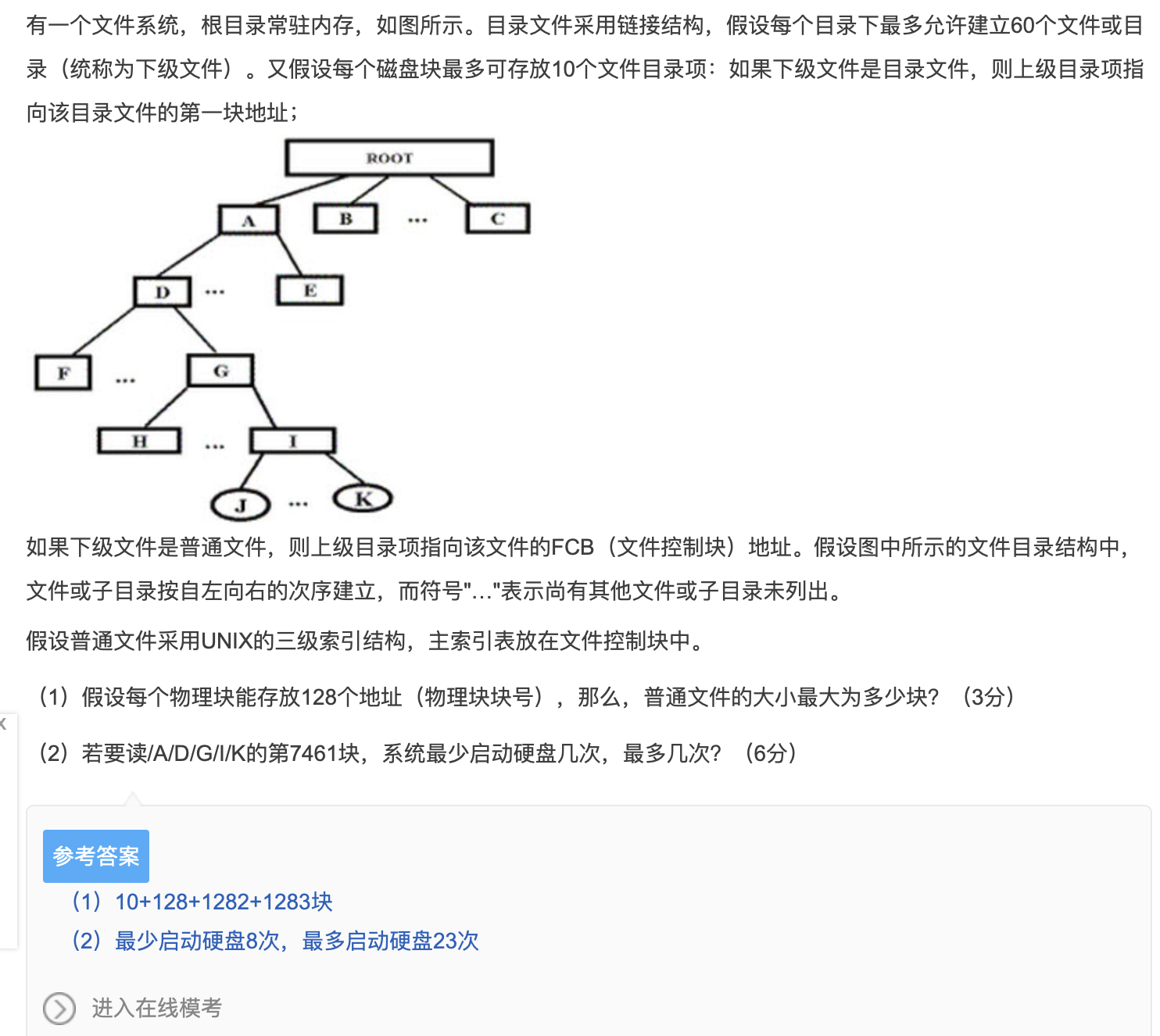
练习2

如图选择 (FAT32支持Unicode编码)
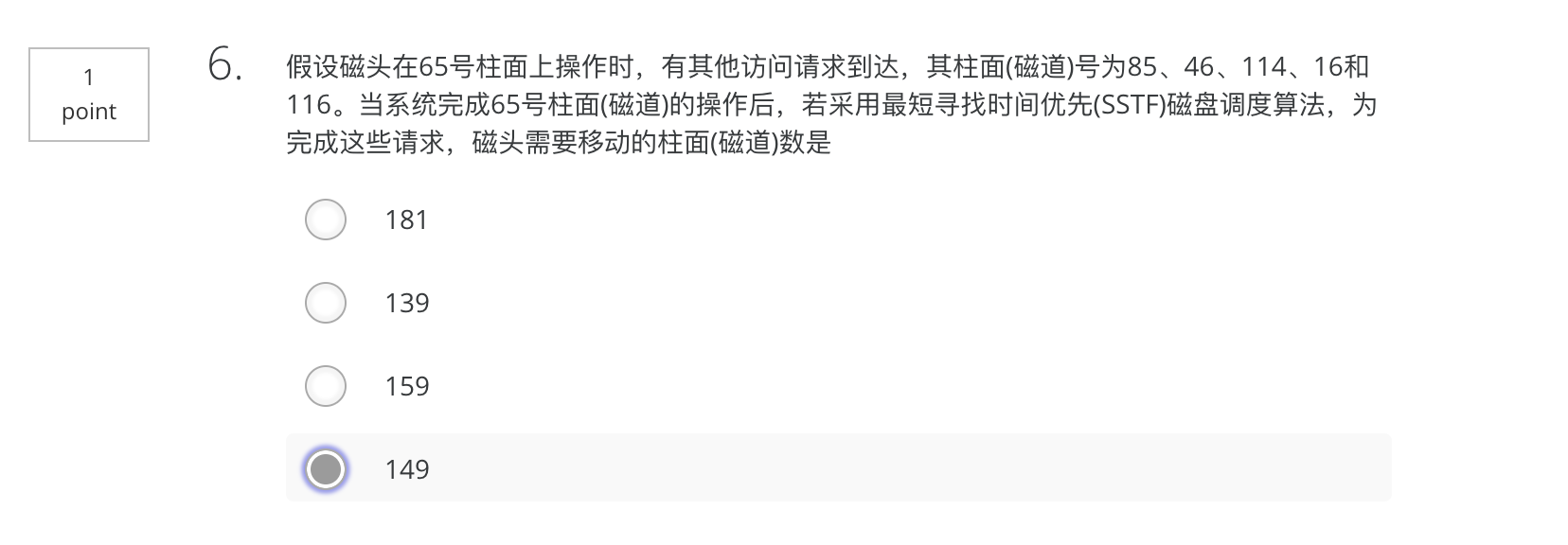
 (65-46)+(46-16)+(85-16)+(114-85)+(116-114)=19+30+69+29+2=149
(65-46)+(46-16)+(85-16)+(114-85)+(116-114)=19+30+69+29+2=149
选1
PPT练习题
P326 9. Consider the directory tree of Fig. 4-8. If /usr/jim is the working directory, what is the absolute path name for the file whose relative path name is ../ast/x?
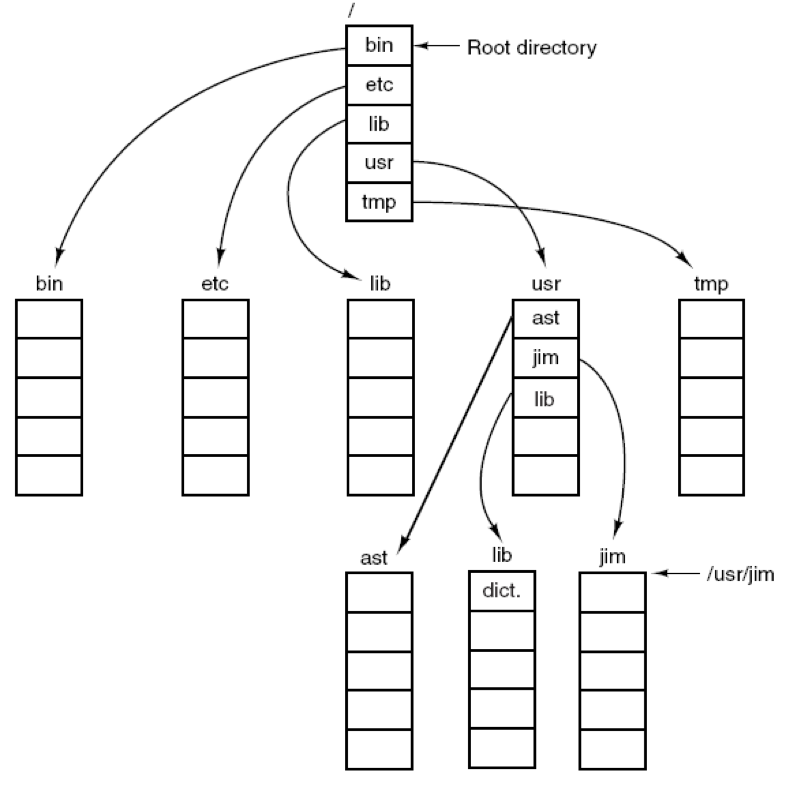
分析:/usr/ast/x
P326 15. Consider the i-node shown in Fig. 4-13. If it contains 10 direct addresses of 4 bytes each and all disk blocks are 1024B, what is the largest possible file?
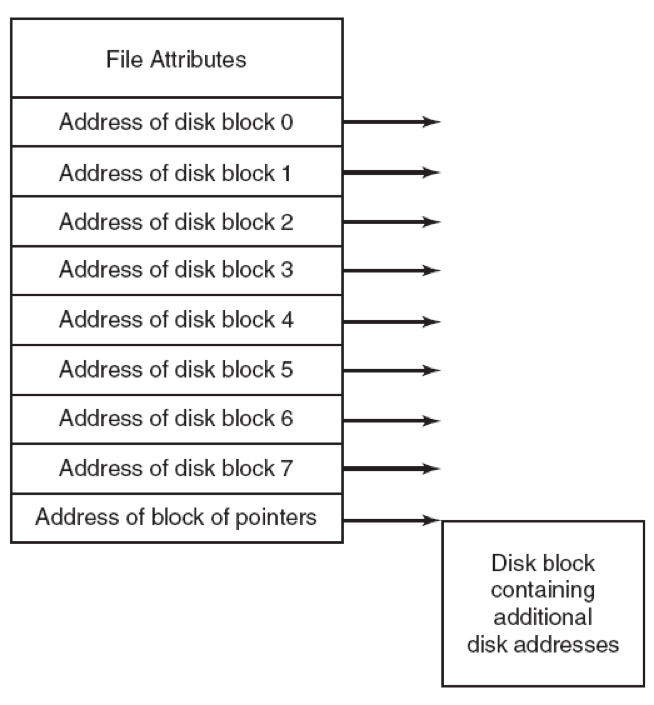
分析:题意:首先是i节点包含了10个直接地址,每个地址4B,所有磁盘块都是1024B,文件最大可能是多少?
首先这里Address of disk block有10个,图里仅为示意;然后最后存在一个地址块指针,即一个间接块,指向另一个更大的空间,那么这个指针块可以指向多少个地址呢?$1024B/4B=256$个,所以这个文件最大可能有:$101024B+2561024B=266KB$
一个空闲块位图开始时和磁盘分区首次初始化类似,比如:1000 0000 0000 0000(首块被根目录使用),系统总是从最小编号的盘块开始寻找空闲块,所以在有6块的文件A写入之后,该位图为1111 1110 0000 0000。请说明在完成如下每一个附加动作之后位图的状态:
a. 写入有5块的文件B
b. 删除文件A
c. 写入有8块的文件C
d. 删除文件B
分析:1111 1111 1111 0000
1000 0001 1111 0000
1111 1111 1111 1100
1111 1110 0000 1100
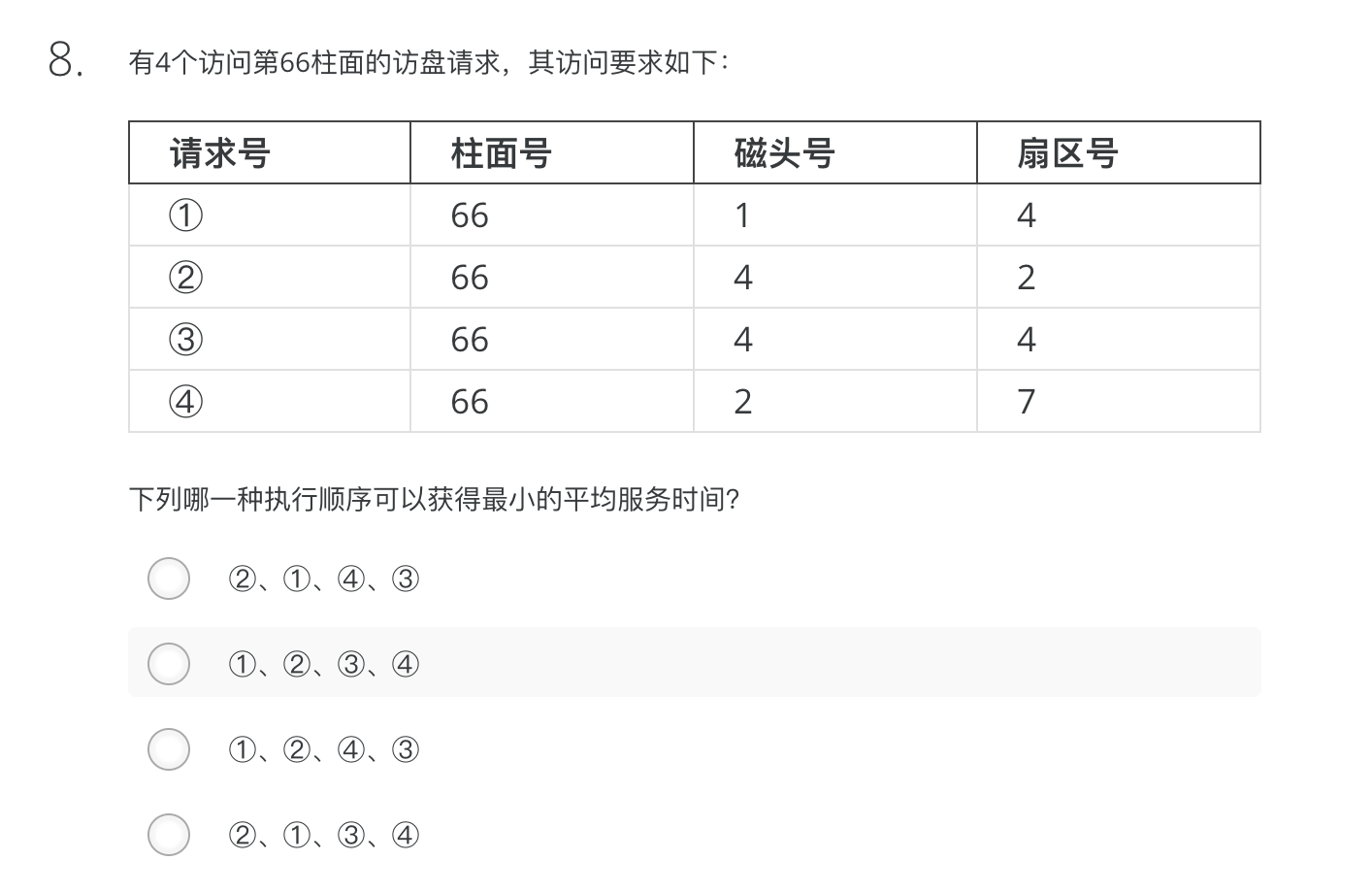
In UNIX i-node scheme, a directory entry contains only two fields: the file name (14 bytes) and the number of the i-node for that file (2 bytes). These parameters limit the number of files per file system to ( ) .
A. 64k B. 32k C. 16k D. 4k分析:i-node用2 bytes来表示的,那么共有16位来表示它,所以有2^16个不同来表示i-node的方法,所以说,每个文件系统中,最多有64K个文件
Consider the following page-request string in Demand Paging system: 1,2,3,4,5,3,4,1,6,7,8,7,6,3,2,1,2,3,6. How many page faults would occur for the following replacement algorithms, assuming four frames? Remember that all frames are initially empty, so your first unique pages will all cost one fault each.
(1) LRU replacement (2) FIFO replacement (3) Optimal replacement分析:12,13,10
I/O 系统
I/O管理
设备控制器
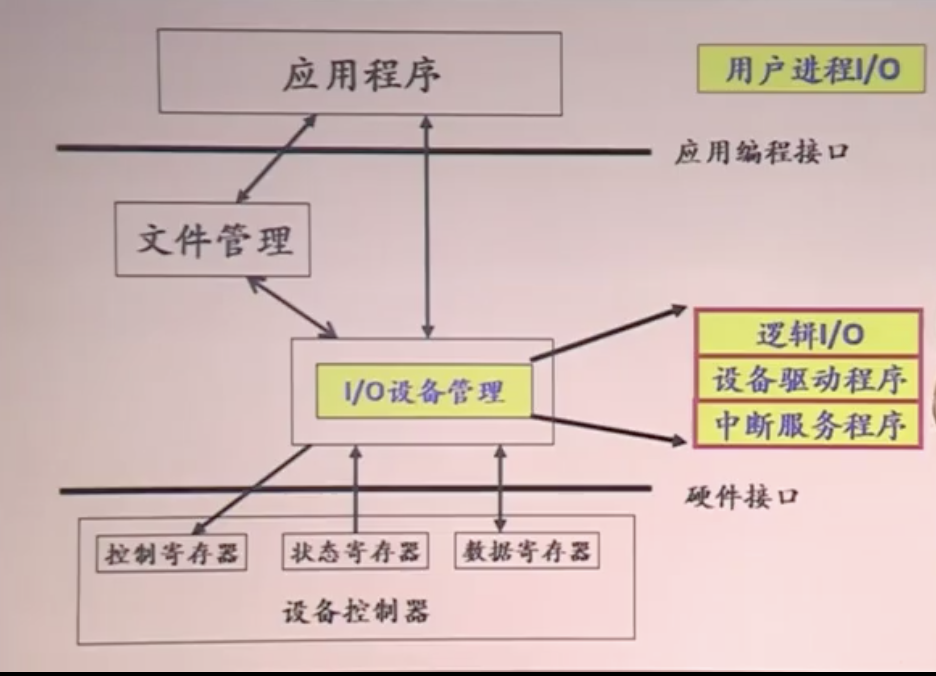
I / O设备通常由两部分组成:设备控制器和设备本身
设备控制器是插件板上的芯片或一组芯片,用于物理控制设备
与设备控制器通信,给出命令并接受响应的软件称为设备驱动程序device driver
控制器的工作是将串行比特流转换为字节块并执行必要的任何纠错
每个控制器都有一些用于与CPU通信的寄存器
CPU如何与控制寄存器和设备数据缓冲区通信?
- 解决方案1
每个控制寄存器都分配有一个I / O端口号
所有I / O端口的集合构成I / O端口空间
在此模式中,内存和I / O的地址空间不同
示例:IBM 360系列 - 解决方案2:内存映射I / O
将所有控制寄存器映射到存储空间
为每个控制寄存器分配一个唯一的存储器地址,没有分配存储器
通常,分配的地址位于地址空间的顶部
示例:PDP-11 - 混合模式
具有内存映射的I / O数据缓冲区和用于控制寄存器的独立I / O端口
示例:奔腾
I/O特点
- I/O性能常常成为系统性能的瓶颈
操作系统庞大复杂的原因之一:
- 资源多、杂、并发,均来自I/O
- 速度差异大
- 不同应用要求不同
- 控制接口的复杂性
- 传送单位不同
- 数据表示不同
- 错误条件
与其他功能联系密切,特别是文件系统
I/O设备分类
- 按数据组织分
- 块设备
- 以固定大小的数据块为单位存储、传输信息,每个块具有其自己的地址
- 传输速率较高、可寻址(随机读写)
- 基本属性是可以独立地读取或写入每个块
- 示例:磁盘,CD-ROM,USB
- 字符设备
- 以字符为单位存储、传输信息
- 传输速率低、不可寻址,也没有任何搜索操作
- 提供或接受字符流,而不考虑任何块结构
- 示例:打印机,网络接口,鼠标
- 块设备
- 按功能分
- 存储设备
- 磁盘、磁带
- 传输设备
- 网卡、Modem(调制解调器)
- 人机交互设备
- 显示器、键盘、鼠标
- 存储设备
- 从资源分配角度
- 独占设备
- 在一段时间内只能有一个进程使用的设备,一般为低速I/O设备(如打印机,磁带等)
- 共享设备
- 在一段时间内可有多个进程共同使用的设备,多个进程以交叉的方式来使用设备,其资源利用率高(如硬盘)
- 虚设备
- 在一类设备上模拟另一类设备,常用共享设备模拟独占设备,用高速设备模拟低速设备,被模拟的设备称为虚设备
- 目的:将慢速的独占设备改造成多个用户可共享的设备,提高设备的利用率
- 例如:SPOOLING技术,利用虚设备技术——用硬盘模拟输入输出设备
- 独占设备
输入设备
- 键盘
- 可以通过串行端口,并行端口或USB端口连接,在每个键操作上CPU被中断,键盘驱动程序提取键入的字符,所有键盘硬件提供的是密钥编号而不是ASCII代码
- 键盘驱动程序的基本工作是收集输入并将其传递给用户程序
- 面向字符模式
驱动程序接受输入并将其向上传递未经修改
POSIX中的非规范模式 - 面向行模式
驱动程序处理所有的intraline编辑,只是将更正的行提供给用户程序
POSIX中的规范模式
- 面向字符模式
- 鼠标
- 只要鼠标在任一方向上移动了某个最小距离或按下或释放按钮,就会向计算机发送一条消息
最小距离约为0.1mm
该消息包含三个项目:△x,△y,按钮
- 只要鼠标在任一方向上移动了某个最小距离或按下或释放按钮,就会向计算机发送一条消息
输出设备
- X终端
- 运行X软件并与远程计算机上运行的程序交互的计算机
- X服务器
X终端内部的程序,用于从键盘或鼠标收集输入并接受来自远程计算机的命令 - X客户端
在某个远程主机上运行 - 客户端和服务器之间的消息类型:
- 从程序到工作站命令
- 工作站对程序查询的回复
- 键盘,鼠标和其他活动公告
- 错误消息
- X服务器
- 运行X软件并与远程计算机上运行的程序交互的计算机
用户接口
- 图形用户界面(GUI)
- GUI有四个基本要素
- 视窗/窗口Windows(基本项)
- 图标ICons
- 菜单Menus
- 指点设备Pointing device
- GUI系统的输入仍然使用键盘和鼠标,但输出几乎总是进入称为图形适配器的特殊硬件板;图形适配器包含一个称为视频RAM的特殊内存,用于保存屏幕上显示的图像
- 位图
- 用于照片和视频
通过在图像上覆盖网格来扫描
每个网格方块的平均红色,绿色和蓝色值被采样并保存为一个像素的值 - 用于文本
将特定字符表示为小位图 - 一种使用位图的一般方法是通过一个程序
bitblt(dsthdc,dx,dy,wid,ht,srchdc,sx,sy,rasterop) - 位图的一个问题是它们不能缩放,因此,Windows还支持称为DIB(设备无关位图,设备无关的位图)的数据结构,使用此格式的文件使用扩展名.bmp。
- 用于照片和视频
- TrueType字体
字体外有轮廓(像空心字)
每个TrueType字符由其周围的一系列点定义(周界)
所有点都相对于(0,0)原点
在向上或向下缩放字符时,将每个坐标乘以相同的比例因子
- GUI有四个基本要素
I/O管理的目标和任务
按照用户的请求,控制设备的各种操作,完成I/O设备与内存之间的数据交换,最终完成用户的I/O请求
- 设备分配与回收
- 记录设备的状态
- 根据用户的请求和设备的类型,采用一定的分配算法,选择一条数据通路
- 执行设备驱动程序,实现真正的I/O操作
- 设备中断处理:处理外部设备的中断
- 缓冲区管理:管理I/O缓冲区
- 设备分配与回收
建立方便、统一的独立于设备的接口
通用性:种类繁多、结构各异->设计简单、避免错误->采用统一的方式处理所有设备
- 方便性
- 向用户提供使用外部设备的方便接口,使用户编程时不考虑设备的复杂物理特性
- 统一性:
- 对不同的设备采取统一的操作方式,即在用户程序中使用的是逻辑设备
- 逻辑设备与物理设备
- 屏蔽硬件细节(设备的物理特性、错误处理、不同I/O过程的差异性)
- 方便性
充分利用各种技术(通道、中断、缓冲、异步I/O等)提高CPU与设备、设备与设备之间的并行工作能力,充分利用资源,提高资源利用率
性能:CPU与I/O的速度差别大->减少由于速度差异造成的整体性能开销->尽量使两者交叠运行
- 并行性
- 均衡性(使设备充分忙碌)
保护
设备传送或管理的数据应该是安全的、不被破坏的、保密的
I/O硬件组成
I/O设备一般由机械(设备本身,物理装置)和电子(设备控制器或适配器)两部分组成
控制器的作用
- 操作系统将命令写入控制器的接口寄存器(或接口缓冲区)中,以实现输入/输出,并从接口寄存器读取状态信息或结果信息
- 当控制器接受一条命令后,可独立于CPU完成指定操作,CPU可以另外执行其他计算;命令完成时,控制器产生一个中断,CPU响应中断,控制转给操作系统;通过读控制器寄存器中的信息,获得操作结果和设备状态
- 控制器与设备之间的接口常常是一个低级接口
- 控制器的任务:把串行的位流转换为字节块,并进行必要的错误修正:首先,控制器按位进行组装,然后存入控制器内部的缓冲区中形成以字节为单位的块;在对块验证检查和并证明无错误时,再将它复制到内存中
I/O端口地址
- 接口电路中每个寄存器具有的、唯一的地址,是个整数
- 所有I/O端口地址形成I/O端口空间(受到保护)
I/O指令形式与I/O地址是相互关联的,主要有两种形式:
- 内存映像编址(内存映像I/O模式)
- 分配给系统中所有端口的地址空间与内存的地址空间统一编址
- 把I/O端口看作一个存储单元,对I/O的读写操作等同于对内存的操作
- 优点:
- 凡是可对内存操作的指令都可对I/O端口操作
- 不需要专门的I/O指令
- I/O端口可占有较大的地址空间
- 缺点:
- 占用内存空间
- I/O独立编址(I/O专用指令)
- 分配给系统中所有端口的地址空间完全独立,与内存地址空间无关
- 使用专门的I/O指令对端口进行操作
- 优点:
- 外设不占用内存的地址空间
- 编程时,易于区分是对内存操作还是对I/O端口操作
- 缺点:
- I/O端口操作的指令类型少,操作不灵活
内存映射I/O
- 优点
- 不需要特殊的保护机制来阻止用户进程执行I/O操作
- 操作系统必须要做的事情:避免把包含控制寄存器的那部分地址空间放入任何用户的虚地址空间之中
- 可以引用内存的每一条指令也可以引用控制寄存器
- 不需要特殊的保护机制来阻止用户进程执行I/O操作
- 缺点
- 对一个控制寄存器不能进行高速缓存
- 当设备引用进入高速缓存,则只会从高速缓存中取值并且不会再查询设备,之后当设备最终变为就绪时,软件将没有办法发现这一点,循环将永远进行下去
- 因此,为了避免这一情形,硬件必须针对每个页面具备选择性禁用高速缓存的能力,操作系统必须管理选择性高速缓存,这一特性为硬件和操作系统两者增添了额外的复杂性
- 对一个控制寄存器不能进行高速缓存
I/O控制方式
可编程I/O(轮询/查询)
让CPU做所有的事情
由CPU代表进程给I/O模块发I/O命令,进程进入忙等待,直到操作完成才继续执行
程序控制I/O(PIO, Programmed I/O)通过CPU的in/out或者load/store传输所有数据;适合字符设备
中断驱动I/O
允许CPU在等待设备准备就绪时执行其他操作
为了减少设备驱动程序不断地询问控制器状态寄存器的开销,I/O操作结束后,由设备控制器主动通知设备驱动程序
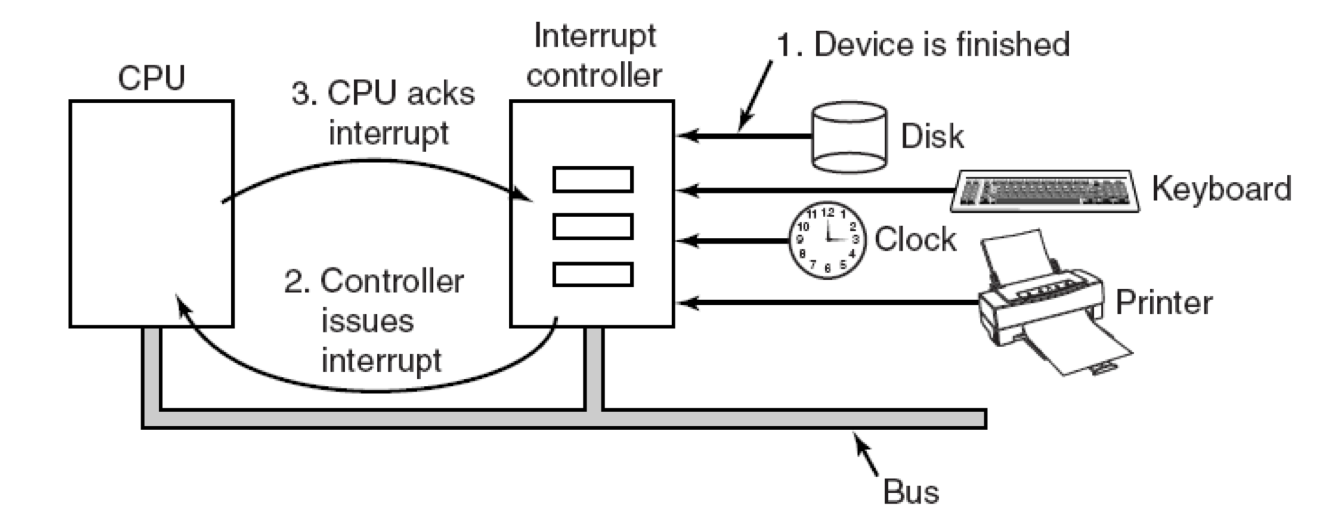
不符合以下这些要求的中断称为不精确中断
- PC(程序计数器)保存在已知位置
- PC指向的所有指令都已完全执行
- 没有执行超出PC指向的指令
- PC指向的指令的执行状态是已知的
中断驱动I / O的一个明显缺点是每个字符都会发生中断
让DMA控制器将字符输入打印机,而不会打扰CPU
此策略需要特殊硬件(DMA控制器),但在I / O期间释放CPU以执行其他工作
DMA(直接内存存取)
Direct Memory Access,使用了中断
仅仅在传送数据的开始和结束时需要CPU干预
一个专门的控制器来完成数据从内存到设备或者是从设备到内存的传输工作
DMA设备控制器可直接访问系统总线并直接与内存互相传输数据
其基本思想是,在I/O设备和内存之间开辟直接的数据交换通路
DMA控制器可用来代替CPU控制内存和设备之间进行成批的数据交换
(让DMA控制器一次给打印机提供一个字符,不必打扰CPU,将中断次数从打印每个字符一次变为打印每个缓冲区一次)
适合块设备
流程
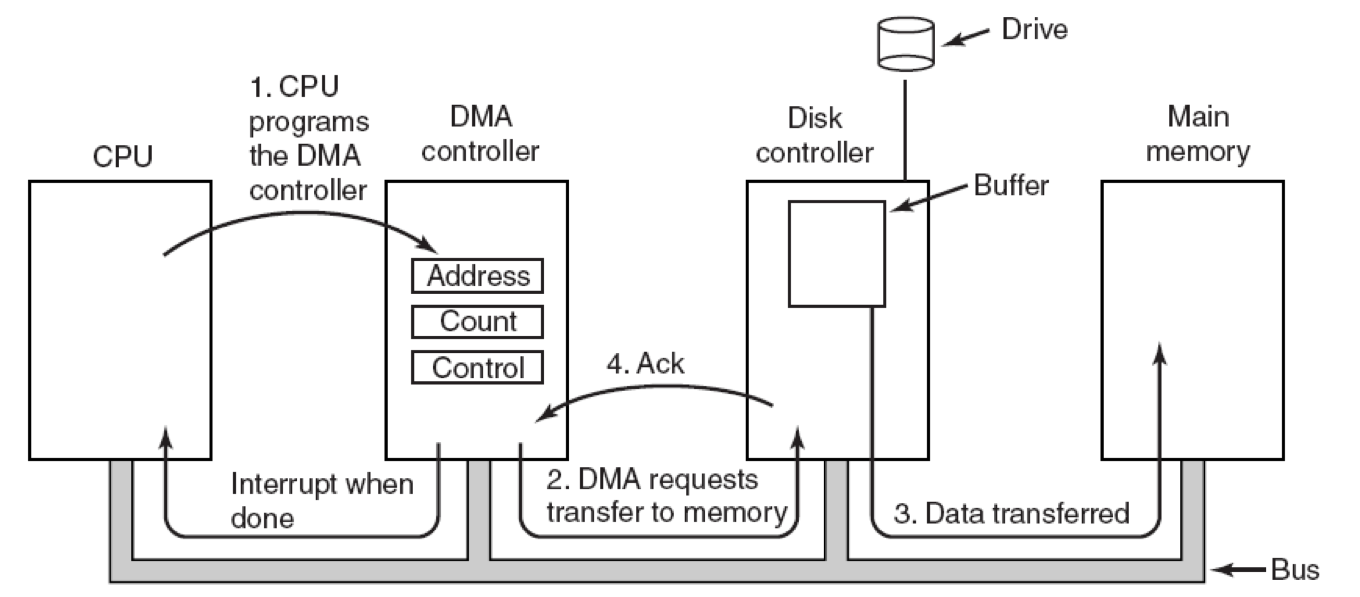
- CPU设置DMA控制器的寄存器:将准备存放输入数据的内存起始地址、要传送的字节数存入DMA控制器的寄存器
- DMA控制器通过在总线上发出一个读请求到磁盘控制器而发起DMA传送
- 磁盘控制器将数据写入内存
- 磁盘控制器发送应答信号至DMA控制器。重复2-4,当数据全部传送完毕,DMA控制器将中断CPU
操作模式
- word-at-a time mode(每次一字模式)
DMA控制器请求传输一个字并获取它,该机制称为周期窃取 - block mode(块模式)
DMA控制器告诉设备获取总线,发出一系列传输,然后释放总线,这种形式称为突发模式 - fly-by mode(飞跃模式)
DMA控制器告诉设备控制器将数据直接传输到主存储器
I/O软件设计
分层的设计思想
- 每一层都执行操作系统所需要的功能的一个相关子集,它依赖于更低一层所执行的更原始的功能,从而可以隐藏这些功能细节;同时,它又给高一层提供服务
- 较低层考虑硬件的特性,并向较高层软件提供接口
- 较高层不依赖于硬件,并向用户提供一个友好的、清晰的、简单的、功能更强的接口
通常分为四层:
- 用户级I/O软件
- 用户进程层执行输入输出系统调用,对I/O数据进行格式化,为假脱机输入/输出作准备
- 系统调用,包括I / O系统调用,通常由库过程完成
- 假脱机是一种在多道程序设计系统中处理专用I / O设备的方法
守护进程(守护进程)
假脱机目录(假脱机目录) - 假脱机文件传输
USENET新闻系统
- 与设备无关的OS软件
- 独立于设备的软件实现设备的命名、设备的保护、成块处理、缓冲技术和设备分配
- 又分为:
- 驱动程序的统一接口
- 如何使所有I / O设备和驱动程序看起来相同
- 将符号设备名称映射到正确的驱动程序
主设备号(用于定位驱动程序),次设备号(作为传递给驱动程序的参数)(在Unix中) - 阻止用户访问他们无权访问的设备
在Unix和Windows 2000中,设备在文件系统中显示为命名对象
- 将符号设备名称映射到正确的驱动程序
- 如何使所有I / O设备和驱动程序看起来相同
- 缓冲
- 缓冲区的作用:
- 缓和CPU和I/O设备之间速率不匹配的矛盾
- 减少对CPU的中断频率,放宽对中断响应时间的限制
- 提高CPU和I/O设备之间的并行性
- 无缓冲输入的缺点:必须为每个传入的角色启动用户进程
- 缓冲在用户空间的缺点:当字符到达时缓冲区被分页时,可用页面池将缩小,性能将降低
- 在内核中缓冲,然后复制到用户空间:当内核空间中的缓冲区已满时,将引入带有用户缓冲区的页面;当从磁盘引入带有用户缓冲区的页面时,字符送达
- 在内核有双缓冲区
- 如果数据被缓冲太多次,性能会受到影响(网络中还可能涉及许多副本)
- UNIX设置多缓冲的目的是:为了提高基本速率相差比较大的块设备之间的吞吐量,并减少对CPU的中断次数
- 缓冲区的作用:
- 错误报告
- 编程错误
解决方案:向调用者报告错误代码 - 实际的I / O错误
由调用者决定做什么
- 编程错误
- 分配与释放设备
- 提供与设备无关的块大小
- 与设备无关的软件,为更高层提供统一的块大小
- 驱动程序的统一接口
- 设备驱动程序
- 设备驱动程序设置设备寄存器、检查设备的执行状态
- 连接到计算机的每个I / O设备都需要一些特定于设备的代码来控制它,此代码称为设备驱动程序
- 设备驱动程序最明显的功能是接受来自其上方与设备无关的软件的抽象读写请求
- 设备驱动程序通常必须是操作系统内核的一部分,至少在当前架构下
- 驱动程序可以通过三种方式放入内核
- 使用新驱动程序重新链接内核,然后重新引导系统
示例:UNIX - 在操作系统文件中创建一个条目,告诉它需要驱动程序,然后重新启动系统
示例:Windows - 能够在运行时接受新驱动程序并即时安装它们而无需重新启动
示例:USB,IEEE 1394设备
- 使用新驱动程序重新链接内核,然后重新引导系统
- 中断处理程序
- 中断处理程序负责I/O完成时,唤醒设备驱动程序进程,进行中断处理
- 让驱动程序启动I / O操作块,直到中断通知完成
当中断发生时,中断过程执行其任务,然后取消阻止启动它的驱动程序 - 中断完成后,必须在软件中执行步骤
保存尚未由中断硬件保存的寄存器
设置中断服务程序的上下文
为中断服务程序设置堆栈
确认中断控制器,重新启用中断
从保存的位置复制寄存器
运行服务程序
选择下一个要运行的进程
设置MMU上下文以便下一步运行该进程
加载新进程的注册表
开始运行新进程
- 硬件
- 实现物理I/O的操作,关于I/O操作的性能的问题
I/O软件设计目标
设备独立性(设备无关性)
用户编写的程序可以访问任意I/O设备,无需事先指定设备(软盘,硬盘或CD-ROM)
好处:设备分配时的灵活性,易于实现I/O重定向
从用户角度:用户在编制程序时,使用逻辑设备名,由系统实现从逻辑设备到物理设备(实际设备)的转换,并实施I/O操作
从系统角度:设计并实现I/O软件时,除了直接与设备打交道的低层软件之外,其他部分的软件不依赖于硬件
统一命名
文件或设备的名称应该只是一个字符串或整数,而不是以任何方式依赖于设备
错误处理
错误应该尽可能地在接近硬件的层面处理
同步与异步传输
阻塞与中断驱动
缓冲
从设备发出的数据不能直接存储在最终目的地
共享与独占设备
磁盘是共享的,磁带驱动器是独占的
I/O相关技术
缓冲技术
- 解决CPU与I/O设备之间速度的不匹配问题(现在凡是数据到达和离去速度不匹配的地方均可采用缓冲技术
- 提高CPU与I/O设备之间的并行性
- 减少了I/O设备对CPU的中断请求次数,放宽CPU对中断响应时间的要求
缓冲区
- 分类
- 硬缓冲区:由硬件寄存器实现(例如:设备中设置的缓冲区)
- 软缓冲区:在内存中开辟一个空间,用作缓冲区
- 管理
- 单缓冲
- 双缓冲
- 缓冲池(多缓冲、循环缓冲):统一管理多个缓冲区,采用有界缓冲区的生产者/消费者模型对缓冲池中的缓冲区进行循环使用
unix SYSTEM V缓冲技术
- 采用缓冲池技术,可平滑和加快信息在内存和磁盘之间的传输
- 缓冲区结合提前读和延迟写技术对具有重复性及阵发性I/O进程、提高I/O速度很有帮助
- 可以充分利用之前从磁盘读入、虽已传入用户区但仍在缓冲区的数据(尽可能减少磁盘I/O的次数,提高系统运行的速度
- 数据结构
- 200个缓冲区(每个512字节或1024字节)
- 每个缓冲区由缓冲控制块或缓冲首部+缓冲数据区构成,系统通过缓冲控制块来实现对缓冲区的管理
- 空闲缓冲区队列(av链)队列头部为bfreelist
- 设备缓冲队列(b链)链接所有分配给各类设备使用的缓冲区,按照散列方式阻止
- 逻辑设备号+盘块号是缓冲区的唯一标志
- 每个缓冲区可同时在av链和b链中(I/O完成后)
I/O设备管理
数据结构
- 描述设备、控制器等部件的表格
- 每个部件、每台设备分别设置一张表格,常称为设备表或部件控制块
- 建立同类资源的队列
- 面向进程I/O请求的动态数据结构
- 建立I/O队列
独占设备的分配
- 静态分配
- 在进程运行前,完成设备分配;运行结束时,收回设备
- 缺点:设备利用率低
- 动态分配
- 在进程运行过程中,当用户提出设备要求时,进行分配,一旦停止使用立即收回
- 优点:效率高
- 缺点:分配策略不好时,产生死锁
分时式共享设备的分配
- 所谓分时式共享就是以一次I/O为单位分时使用设备,不同进程的I/O操作请求以排队方式分时地占用设备进行I/O
- 由于同时有多个进程同时访问,且访问频繁,就会影响整个设备使用效率,影响系统效率。因此要考虑多个访问请求到达时服务的顺序,使平均服务时间越短越好
设备驱动程序
- 一般,设备驱动程序的任务是接受来自与设备无关的上层软件的抽象请求,并执行这个请求
- 每一个控制器都设有一个或多个设备寄存器,用来存放向设备发送的命令和参数。设备驱动程序负责释放这些命令,并监督它们正确执行
- 接口
- 与操作系统的接口:为实现设备无关性,设备作为特殊文件处理。用户的I/o请求、对命令的合法性检查以及参数处理在文件系统中完成。在需要各种设备执行具体操作时,通过相应数据结构转入不同的设备驱动程序。
- 与系统引导接口(初始化,包括分配数据结构,建立设备的请求队列)
- 与设备的接口
- 接口函数
- 驱动程序初始化函数
- 驱动程序卸载函数
- 申请设备函数
- 释放设备函数
- I/O操作函数
- 中断处理函数
I/O进程
- 专门处理系统中的I/O请求和I/O中断工作
- 是系统进程,一般赋予最高优先级。一旦被唤醒,可以很快抢占处理机投入运行
- I/O进程开始运行后,首先关闭中断,然后用receive去接收消息
- 没有消息,则开中断,将自己阻塞
- 有消息,则判断消息类型
- I/O请求的进入
- 准备通道程序,发出启动I/O指令,继续判断有无消息
- 用户程序:调用send将I/O请求发送给I/O进程;调用block将自己阻塞,直到I/O任务完成后被唤醒
- 系统:利用wakeup唤醒I/o进程,完成用户所要求的I/o处理
- I/O中断的进入
- 进一步判断正常或异常结束
- 正常:唤醒要求进行I/O操作的进程
- 异常:转入相应的错误处理程序
- 当I/O中断发送时,内核中的中断处理程序发一条消息给I/O进程,由I/O进程负责判断并处理中断
- 进一步判断正常或异常结束
- I/O请求的进入
I/O性能问题
从两个角度入手:
- 使CPU利用率尽可能不被I/O降低
- 减少或缓解速度差距:缓冲技术
- 使CPU不等待I/O:异步I/O
- 使CPU尽可能摆脱I/O
- DMA、通道
异步I/O
用于优化应用程序的性能
通过异步I/O,应用程序可以启动一个I/O操作,然后在I/O请求执行的同时继续处理
基本思想:填充I/O操作间等待的CPU时间
同步I/O
应用程序被阻塞直到I/O操作完成
时钟
可编程时钟的操作模式
- 一次性模式(一次完成模式)
当时钟启动时,它将保持寄存器的值复制到计数器中,然后在晶体的每个脉冲处递减计数器
当计数器变为零时,它会导致中断并停止,直到软件再次明确说明 - square-wave mode(方波模式)
在达到零并导致中断后,保持寄存器自动复制到计数器
这些周期性中断称为时钟周期
时钟驱动器的任务
- 保持一天的时间
- 防止进程运行的时间超过允许的时间
- 考虑CPU使用率
- 处理用户进程发出的警报系统调用
- 为部分系统本身提供监视定时器
- 进行性能分析,监视和统计信息收集
如果时钟驱动程序有足够的时钟,它可以为每个请求设置一个单独的时钟。否则,必须用一个物理时钟来模拟多个虚拟时钟
瘦客户端
多年来,主要的计算范例在集中式计算和分散计算之间摇摆不定;大多数用户都想要高性能的交互式计算,但实际上并不想管理计算机,这导致研究人员使用满足现代终端期望的瘦客户端重新检查分时共享
如,THINC,客户端只作为显示用,所有计算都在服务器端完成
电源管理
- 电的消耗
- 环境需要
- 电池供电的电脑
- 电池不能保持足够的电量持续很长时间
- 两种降低能耗的一般方法
- 操作系统在不使用时关闭计算机的部件
- CPU
笔记本电脑CPU可以通过软件进入睡眠状态,将功耗降低到几乎为零
它在这种状态下唯一能做的就是在发生中断时唤醒 - 显示器
- 一部分开启,一部分关闭
- 硬盘
几分钟不活动后旋转磁盘
Td - 磁盘的收支平衡点,5~15秒
RAM中有大量的磁盘缓存
通过发送消息或信号,让运行程序了解磁盘状态 - 内存
缓存可以刷新然后关闭
将主内存的内容写入磁盘,然后关闭主内存 - 无线通信
当关闭无线设备时,基站在其磁盘上缓冲到来的消息。 - Thermal Management(热量管理)
- 电池管理
- 驱动程序接口
ACPI(高级配置和电源接口,高级配置与电源接口)
- CPU
- 应用程序使用更少的能源
- 可能意味着较差的用户体验
例子:颜色输出变为黑白,语音识别减少了词汇量,图像中的分辨率或细节较少
- 可能意味着较差的用户体验
- 操作系统在不使用时关闭计算机的部件
- 电池有两种通用类型:
- 一次性的(一次性使用)
可用于运行手持设备
最常见的是AAA,AA和D细胞 - 可再充电的(可再充电的)
可以储存足够的能量为笔记本电脑供电几个小时
电池节约的一般方法是将CPU,内存和I / O设备设计为具有多种状态:开,睡,休眠(休眠)和关闭
- 一次性的(一次性使用)
quiz 11 错题和模糊题
1,2,3,4,5如图选择

第六题应选择1 2 4 5

第九题如图

应填入 设备无关软件/设备独立软件/设备独立性软件/设备无关性软件/逻辑I/O

PPT练习题
In which of the four I/O software layers is each of the following done.
- Computing the track, sector and head for a disk read
- Writing commands to the device registers
- Checking to see if the user is permitted to use the device
- Converting binary integers to ASCII for printing
分析:
a. 设备驱动层
b. 设备驱动层
c. 设备独立软件层(protection)
d. 用户空间软件层(format I/O)
Disk requests come into the disk driver for cylinders 10, 22, 20, 2, 40, 6, and 38, in that order. In all cases, the arm is initially at cylinder 20. A seek takes 6 mesc per cylinder moved. How much seek times is needed for
- First Come first Served (FCFS)
- Shortest Seek Time First (SSTF)
- Elevator algorithm (SCAN, initially moving upward)
分析:
20-10-22-20-2-40-6-38 [(20-10)+(22-10)+(22-20)+(20-2)+(40-2)+(40-6)+(38-6)]*6=876mesc
20-22-10-6-2-38-40 [(22-20)+(22-10)+(10-6)+(6-2)+(38-2)+(40-38)]*6=360mesc
20-22-38-40-10-6-2 [(22-20)+(38-22)+(40-38)+(40-10)+(10-6)+(6-2)]*6=348mesc
假定一磁盘有200个柱面,编号为0~199,当前存取臂的位置在143号柱面上,并刚刚完成了125号柱面的服务请求,如果请求队列的先后顺序是:86,147,91,177,94,150,102,175,130。为完成上述请求,下列算法存取臂移动的总量是多少?写出存取臂移动的顺序【FCFS,SSTF,SCAN】
分析:
143-86-147-91-177-94-150-102-175-130
存取臂移动的总量:57+61+56+86+83+56+48+73+45=565
143-147-150-130-102-94-91-86-175-177
存取臂移动的总量:4+3+20+28+8+3+5+89+2=162
143-147-150-175-177-130-102-94-91-86
存取臂移动的总量:4+3+25+2+47+28+8+3+5=125
死锁
死锁的基本概念
定义
一组进程中,每个进程都无限等待被该组进程中另一进程所占有的资源,因而永远无法得到的资源,这种现象称为进程死锁,这一组进程就称为死锁进程
- 参与死锁的所有进程都在等待状态(所以都处在等待状态或者阻塞状态)
- 参与死锁的进程是当前系统中所有进程的子集
产生原因
资源数量有限、锁和信号量错误使用
产生条件
- 互斥使用(资源独占)
- 一个资源每次只能给一个进程使用
- 占有且等待(请求和保持,部分分配)
- 进程在申请新的资源的同时保持对原有资源的占有
- 不可抢占(不可剥夺)
- 资源申请者不能强行的从资源占有者手中夺取资源,资源只能由占有者资源释放
- 循环等待
- 存在一个进程等待队列$\{P_1,P_2,\cdot\cdot\cdot,P_n\}$
- 其中$P_1$等待$P_2$占有的资源,$P_2$等待$P_3$占有的资源,$\cdot\cdot\cdot$,$P_n$等待$P_1$占有的资源,形成一个进程等待环路
资源的使用方式:
“申请—分配—使用—释放”模式
可重用资源:可被多个进程多次使用
又可分为可抢占资源(CPU、内存)与不可抢占资源(打印机)
例如:处理器、I/O部件、内存、文件、数据库、信号量
可消耗资源:只可使用一次、可创建和销毁的资源
例如:信号、中断、消息
活锁和饥饿
活锁(既无进展也没有阻塞)
- 先加锁
- 再轮询【忙等待】(超时后,下CPU,再过段时间上CPU,不断循环)
饥饿(资源分配策略决定)
资源分配图
RAG: Resoure allocation graph
用有向图描述系统资源和进程的状态,从而来解决死锁的问题
通过二元组$G=(V,E)$
V: 结点的集合,分为P(进程),R(资源)两部分
E:有向边的集合,其元素为有序二元组
系统由若干类资源构成,一类资源称为一个资源类;每个资源类中若干个同种资源,称为资源实例
资源类:方框表示
资源实例:方框中的黑圆点表示
进程:用圆圈中加进程名表示
分配边:资源实例->进程(资源实例分配给某进程)
申请边:进程->资源类(进程申请某类资源)
资源分配图化简
寻找一个非孤立、且只有分配边(资源都充足,可以完成进程)的进程结点
去掉分配边,将其变为孤立节点
再把相应的资源分配给一个等待该资源的进程,即将该进程的申请边变为分配边(先后顺序无关)
重复1、2,直到找不到点了;那么如果只剩下孤立节点,就是没有死锁存在的;否则就存在环路
死锁定理
- 如果资源分配图中没有环路,则系统中没有死锁;如果图中存在环路则系统中可能存在死锁
- 如果每个资源类中只包含一个资源实例,则环路是死锁存在的充分必要条件
资源轨迹图
Resource Trajectories
如果直到了进程在各个阶段需要哪些资源,那么可以在图中进程标注;两个进程的交叠区域就是一个会造成死锁的区域;进程在图中只能向右或者向上前进,一旦进入了危险区,那么就可能发生死锁;为了避免死锁,应当在合适的时间阻塞某个进程,使得运行避开这个区域
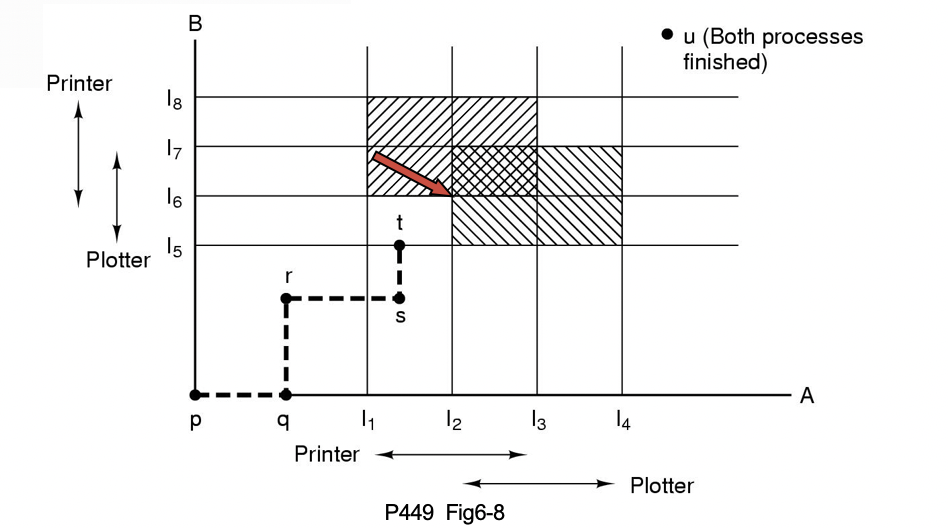
A在I1-I3使用Printer,在I2-I4使用Plotter;同理B
现在资源的分配是虚线的走法,如果要安全则要避开交叠区域,比如到左下角这个点的时候,则会出现,A占用Printer,并且还需要保持,B占用Plotter,并且还需要保持
解决死锁的方法
不考虑死锁问题
鸵鸟算法
不让死锁发生
死锁预防deadlock prevention
静态策略:设计合适的资源分配算法,不让死锁发生
具体做法:破坏产生死锁的四个必要条件之一
- 互斥使用(资源独占)
- 资源转换技术:把独占资源变为共享资源
- SPOOLing技术的引入
- 解决不允许任何进程直接占有打印机的问题
- 设计一个“守护进程/线程daemon”负责管理打印机,进程需要打印时,将请求发给该daemon,由它完成打印任务
- 核心思想:如果资源不被一个进程独占,那么就不会发生死锁
- 原理:
- 避免在不必要时分配资源
- 尽可能少的进程占用资源
- 占有且等待(请求和保持,部分分配)
- 核心思想:禁止已持有资源的进程再等待其他资源
- 问题:进程在运行开始时可能不知道所需的资源,还会占用其他流程可能使用的资源
- 实现方案一:要求每个进程在运行前必须一次性申请它所要求的所有资源,且仅当该进程所要资源均可满足时才给予一次性分配,资源静态分配
- 资源利用率低;会产生“饥饿”现象
- 实现方法二:在允许进程动态申请资源前提下规定,一个进程在申请新的资源不能立即得到满足而变为等待状态之前,必须释放已占有的全部资源,若需要再重新申请
- 也会产生“饥饿”现象
- 不可抢占(不可剥夺)
- 当一个进程申请的资源被其他进程占用时,可以通过操作系统抢占这一资源(两个进程优先级不同)
- 局限性:适用于状态易于保存和恢复的资源(CPU【进程抢占】、内存【页面置换算法】)
- 不可行的,例如一个打印机在执行的时候,被抢占了……
- 循环等待
- 通过定义资源类型的线性顺序实现
- 方案一:保证每个进程在任何时刻只能占用一个资源。若需要另外一个资源,必须先释放第一个资源
- 若进程正在把一个大文件从磁带机上读入并送到打印机打印,那么这种限制是不可接受的
- 方案二:资源有序分配法
- 把系统中所有资源编号,进程在申请资源时必须严格按资源编号的递增次序进行,否则操作系统不予分配
- 常使用的资源,放在前面;不常使用的资源,放在后面
- 可以通过此方法解决哲学家就餐问题
- 但是几乎找不到一种令每个人都满意的编号次序
死锁避免
动态策略:以不让死锁发生为目标,跟踪(动态)并评估资源分配过程,根据评估结果决策是否分配【若分配后系统发生死锁或可能发生死锁,则不予分配,否则(安全状态)予以分配】
安全状态:如果系统中存在一个由所有进程构成的安全序列$P_1,\cdot\cdot\cdot,P_n$,则称系统处于安全状态【安全状态一定没有死锁发生】
安全序列:一个进程序列$\{P_1,\cdot\cdot\cdot,P_n\}$是安全的,如果对于每一个进程$P_i(1\leq i \leq n)$: 它以后还需要的资源量不超过系统当前剩余资源量与所有进程$P_j(j<i)$当前占有资源量之和,则称系统处于安全状态
不安全状态:系统中不存在一个安全序列【不安全状态一定导致死锁,但是目前不一定在死锁状态,即死锁状态是不安全状态的子集】
银行家算法 Banker’s Algorithm
仿照银行发放贷款时采取的控制方式而设计的一种死锁避免算法
应用条件:
- 在固定数量的进程中共享固定的资源
- 每个进程预先指定完成工作所需的最大资源数量
- 进程不能申请比系统中可用资源总数还多的资源
- 进程等待资源的时间是有限的
- 如果系统满足了进程对资源的最大需求,那么,进程应该在有限的时间内使用资源,然后归还给系统
Algorithm:
n:系统中进程数量
m:资源类数量
Available:Array[1..m] of integer 资源(总共m个,剩余的可用量)
Max: Array[1..n,1..m] of integer 每一个进程对每一类资源的最大需求量
Allocation:Array[1..n,1..m] of integer 当前系统中哪些进程得到了哪些资源(即分配给这个进程的资源的数量)
Need:Array[1..n,1..m] of integer 每个进程对每一类资源还需要的资源量
Request:Array[1..n,1..m] of integer 本次进程对资源的申请量
当进程Pi提出资源申请时,系统执行下列步骤:
1)若Request[i]<=Need[i],转(2);否则,报错返回
2)若Request[i]<=Available,转(3);否则,进程等待
3)假设系统分配了资源,则有(系统新状态):
Available = Available - Request[i];
Allocation[i] = Allocation[i] + Request[i];
Need[i] = Need[i] - Request[i];
若系统新状态是安全的,则分配完成
若系统新状态是不安全的,则恢复原来状态,进程等待
为进行安全性检查,定义数据结构:
Work:Array[1..m] of integer
Finish:Array[1..n] of integer
安全性检查的步骤:
1) Work = Available;
Finish = false;
2)寻找满足条件的i:
a. Finish[i] == false;
b. Need[i] <= Work;
如果不存在,则转(4)
3)Work = Work + Allocation[i];
Finish[i] = true;
转(2)
4)若对所有i,Finish[i] == true,则系统处于安全状态,否则系统处于不安全状态
让死锁发生
死锁检测与解除
死锁检测
- 允许死锁发生,但是操作系统会不断监视操作系统进展情况,判断死锁是否真的发生
- 一旦死锁发生则采取专门的措施,解除死锁并以最小的代价恢复操作系统运行
检测时机:
- 当进程由于资源请求不满足而等待时检测死锁
- 缺点:系统开销大
- 定时检测
- 系统资源利用率下降时检测死锁
一个简单的死锁检测算法
- 每个进程、资源指定唯一编号
- 设置一张资源分配表,记录各进程与其占用资源之间的关系
- 设置一张进程等待表,记录各进程与要申请资源之间的关系
通过寻找进程等待表,找对应资源;再去资源分配表中寻找这个资源被哪一进程占用了;如此反复循环,直到被占用的资源的进程不出现在进程等待表(说明不存在死锁)或者直到被占用的资源的进程出现在之前找到过的进程中(说明出现了死锁)
死锁解除
利用抢占恢复/回退恢复/杀死(撤销)进程
- 撤销所有死锁进程【所有:消耗过大】
- 进程回退(Roll back)再启动【记录进程中的中间点,每一个进程都后退一步,但是记录中间点需要很多消耗】
- 按照某种原则逐一撤销死锁进程,直到……
- 按照某种原则逐一抢占资源(资源被抢占的进程必须回退到之前的对应状态),直到……
后面两种需要进行“选择原则”
其他问题
- 两阶段加锁(第一阶段:对所需资源加锁;第二阶段:更新,释放锁)适合数据库
- 通信死锁(避免通信死锁的方法:超时)
哲学家就餐问题
问题描述:
有五个哲学家围坐在一圆桌旁,每个人面前有一只空盘子,每两个人之间放一只筷子;每个哲学家的行为是思考,感到饥饿,然后吃通心粉;为了吃通心粉,每个哲学家必须拿到两只筷子,并且每个人只能直接从自己的左边或右边去取筷子(筷子的互斥使用、不能出现死锁现象)
问题模型:
应用程序中并发线程执行时,协调处理共享资源
解决方案
把筷子当作一个信号量来处理;拿筷子时,对筷子进行P操作,申请筷子(都是先申请右边的,再申请左边的)
何时发生死锁?
当每个哲学家都拿到右边的筷子,都等待左边的筷子时,发生死锁。
|
|
怎样从死锁中恢复?
某个哲学家放下一只筷子
怎样避免死锁的发生?
- 最多允许4个哲学家同时坐在桌子周围(思考的时候让他四处溜达)
【增加一个新的信号量room,表示是否有空间可以让哲学家坐在桌子边上】
{是一种鸽巢原理或者是抽屉原理,银行家算法}
|
|
仅当一个哲学家左右两边的筷子都可用时,才允许它拿筷子
通过信号量来实现
12345678910111213141516171819202122232425262728293031323334353637383940// 把哲学家分为三种状态:思考,饥饿,进食typedef int semaphore;int state[N];semaphore mutex = 1;semaphore s[N];void philosopher(int i){while(true){think();P(&mutex);state[i] = HUNGRY;test(i); // 判断是否能同时拿到两只筷子V(&mutex);P(&s[i]);// 如果test通过,则在里面进行了V操作,所以这里就可以用P操作了;否则阻塞在P操作了// 拿左筷子// 拿右筷子eat();// 放左筷子// 放右筷子P(&mutex);state[i] = THINKING;test([i-1]%5); // 对左右哲学家进行测试,看是不是因为刚才i号哲学家吃饭,抢走了周围哲学家的筷子test([i+1]%5);V(&mutex);}}void test(int i){if(state[i] == HUNGRY && (state[(i-1)%5] != EATING) && (state[(i+1)%5] != EATING)){state[i] = EATING;V(&s[i]);}}通过管程来解决
伪代码:
12345678910void philosopher[k=0 to 4]/* the five philosopher clients */{while(true){<think>;get_forks(k); /* client requests two forks via monitor */<eat spaghetti>;release_forks(k); /* client releases forks via the monitor */}}实现:
1234567891011121314151617181920212223242526272829303132333435monitor dining_controller;cond ForkReady[5];boolean fork[5] = {true};void get_forks(int pid){int left = pid;int right = (++pid)%5;/* grant the left fork */if(!fork[left])cwait(ForkReady[left]);/* queue on condition variable */fork[left] = false;/* grant the right fork */if(!fork[right])cwait(ForkReady[right]);/* queue on cindition variable */fork[right] = false;}void release_forks(int pid){int left = pid;int right = (++pid)%5;/* release the left fork */if(!empty(ForkReady[left]))/* no one is waiting for this fork */fork[left] = true;/* awaken a process waiting on fork */else csignal(ForkReady[left]);/* release the right fork */if(!empty(ForkReady[right]))/* no one is waiting for this fork */fork[left] = true;/* awaken a process waiting on fork */else csignal(ForkReady[right]);}给所有哲学家编号,奇数号的哲学家必须首先拿左边的筷子,偶数号的哲学家则反之
……
如何预防死锁?
- 一次性分配思想(一次拿两只筷子)
- 资源的有序分配(先拿大编号,再拿小编号的筷子,对于第五个就先拿左边,再拿右边的;其余都是先拿右边的,再拿左边的)
quiz 12 错题和模糊题
如图选择
第二题:能上CPU,但是得不到资源

如图选择
死锁预防,是未进入之前,设定好的资源分配策略
死锁避免,是进入之后,决定下一步是否安全,银行家算法

应选择4

应选择4,因为“分配后系统”
应选择3(2个该类资源)
因为共有3个进程,5个资源,进程数小于资源数,则不会发生死锁的公式为
①最多申请资源数=资源总数/进程数(可以整除的条件下)
②最多申请资源数=(资源总数/进程数)+1(不可以整除的条件下)
所以本题用②的计算方式,得出结果为5/3+1=2

应选择1234
对于1来说,只分配了一部分,不是一下子全部分配,导致资源再申请新资源的时候还保持着自己已占用的资源,这样就会导致死锁,是占有且等待(请求和保持,部分分配)的条件
应选择23
首先要先算出还需要的资源数量,同时得到系统中还剩余的A、B、C资源数量
对于每一次选择的时候,系统中的数量应该大于还需要的;然后进行更新,系统数量减去还需要的;然后释放资源,系统数量+最大资源数量(即已经拥有的所有数量)【后面两步相当于在系统资源数量上增加已分配的数量】
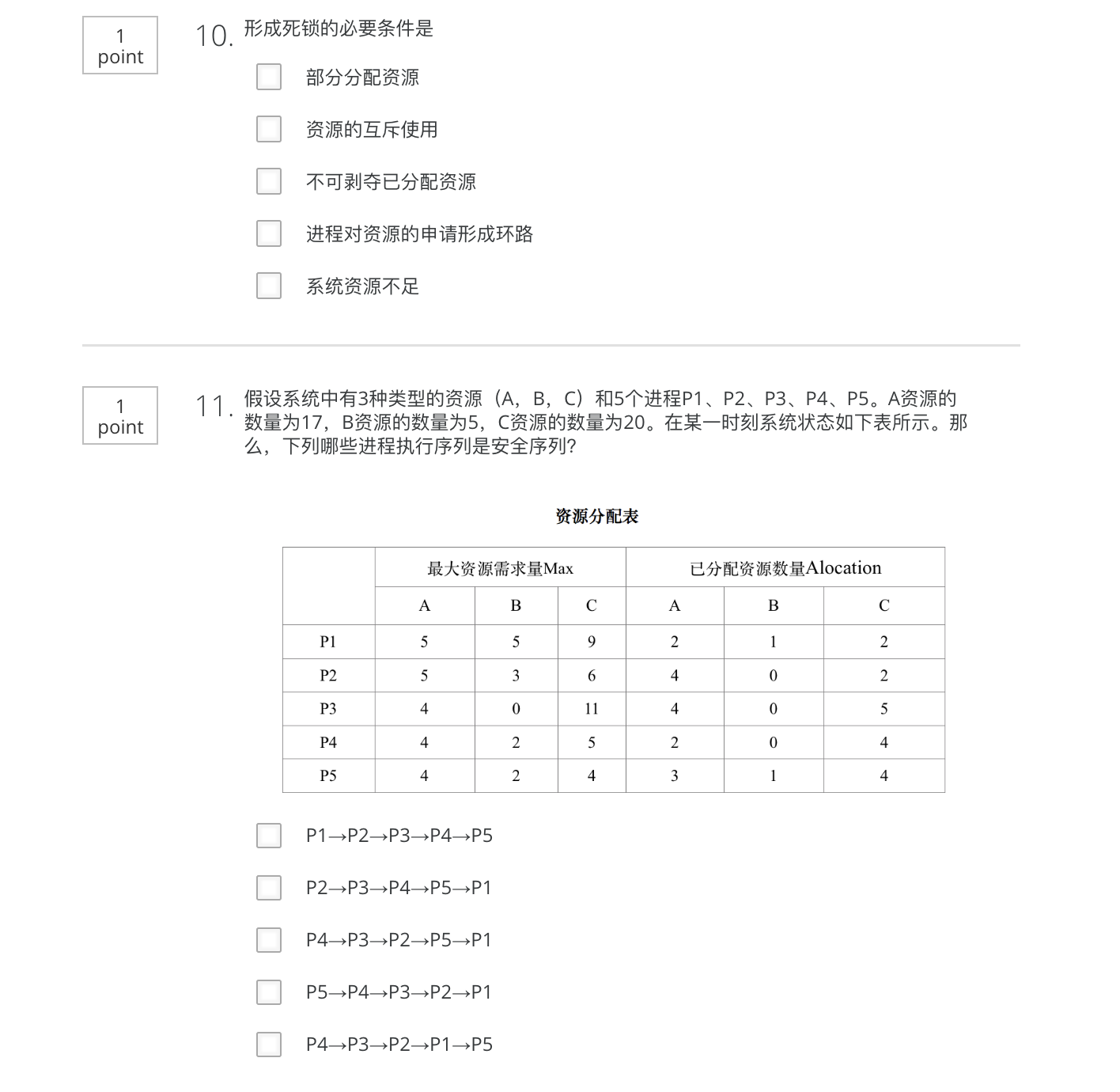
如图选择
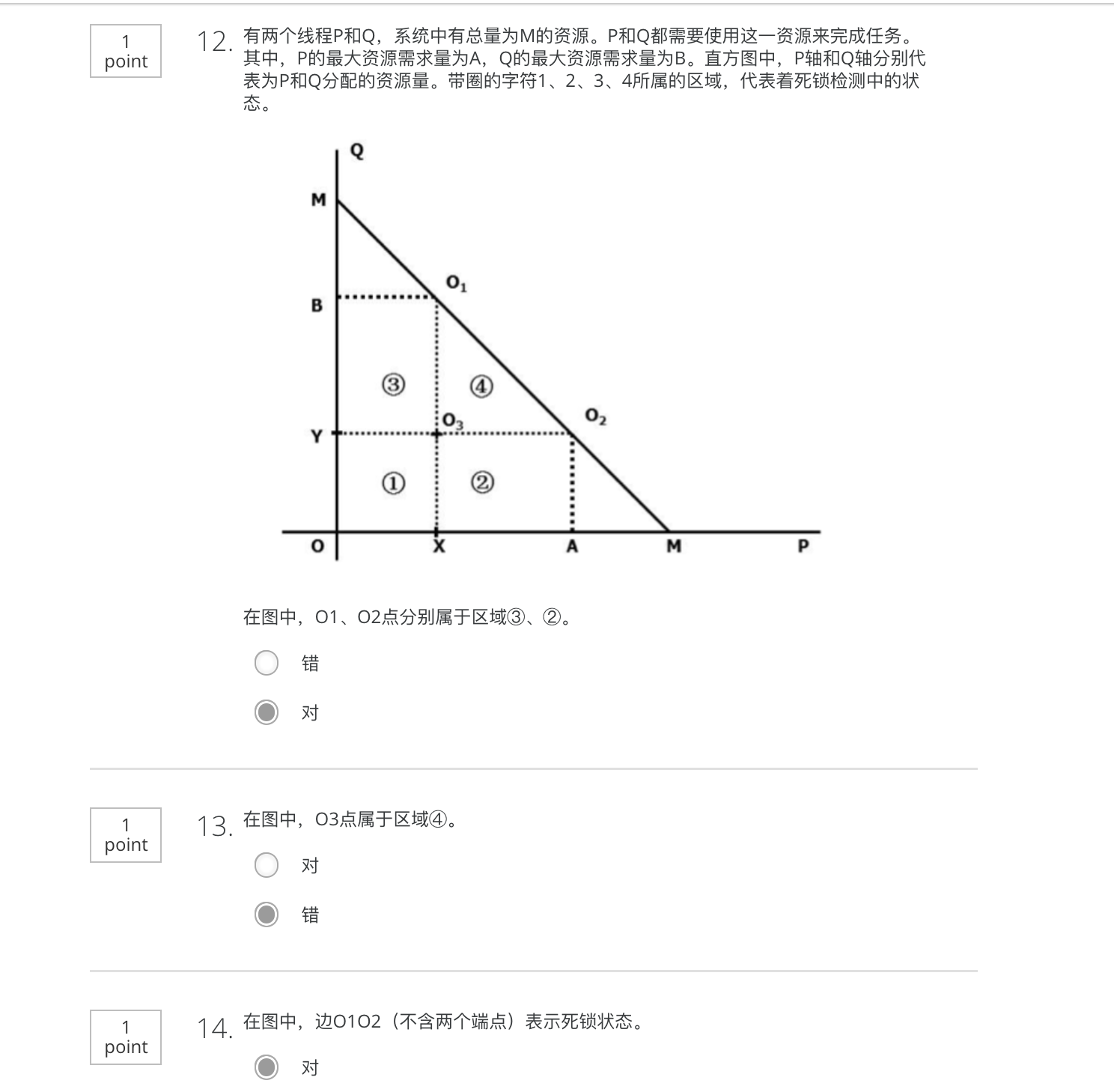
PPT练习题
在系统中仅有m个同类资源,由n个进程互斥使用。如果每个进程对该类资源的最大需求量为w,那么当m、n、w分别取下表列出的值时,问在表中(a)~(e)各种情况下,哪种可能发生死锁?如果可能死锁,请举例说明。
| | (a) | (b) | (c) | (d) | (e) |
| ——- | ——- | ——- | ——- | ——- | ——- |
| m | 2 | 2 | 2 | 4 | 4 |
| n | 1 | 2 | 2 | 3 | 3 |
| w | 2 | 1 | 2 | 2 | 3 |可能死锁:c, e
某系统有A、B、C3类资源供5个进程使用,进程对资源的需求和分配情况如下:
| 进程 | 已分 | 配资 | 源数 | 最大 | 需求 | 量 |
| ———— | ——- | ——- | ——- | ——- | ——- | ——- |
| | A | B | C | A | B | C |
| P1 | 0 | 1 | 0 | 7 | 5 | 3 |
| P2 | 3 | 0 | 2 | 3 | 2 | 2 |
| P3 | 3 | 0 | 2 | 9 | 0 | 2 |
| P4 | 2 | 1 | 1 | 2 | 2 | 2 |
| P5 | 0 | 0 | 2 | 4 | 3 | 3 |目前系统还剩A、B、C三类资源为(2, 3, 0)。请按银行家算法回答下面问题:
- 该状态是否安全?
- 如果进程P1提出(0,1,0)的资源请求,系统能否满足它的请求?
| 进程 | 还需 | 资源 | 量 |
| —— | —— | —— | —— |
| | A | B | C |
| P1 | 7 | 4 | 3 |
| P2 | 0 | 2 | 0 |
| P3 | 6 | 0 | 0 |
| P4 | 0 | 1 | 1 |
| P5 | 4 | 3 | 1 |P2(5,3,5)-p4(7,4,6)-p5(7,4,8)-p3(10,4,10)-p1(10,5,10)安全
| 进程 | 还需 | 资源 | 量 |
| —— | —— | —— | —— |
| | A | B | C |
| P1 | 7 | 3 | 3 |
| P2 | 0 | 2 | 0 |
| P3 | 6 | 0 | 0 |
| P4 | 0 | 1 | 1 |
| P5 | 4 | 3 | 1 |系统还剩A、B、C三类资源为(2,2,0)
P2(5,2,2)-p4(7,3,6)-p5(7,3,8)-p3(10,3,10)-p1(10,5,10)可以满足
多处理器系统
多处理机
Share-memory multiprocessor(共享存储器多处理机,简称多处理机)
共享内存多处理器是一种计算机系统,其中两个或多个CPU共享对公共RAM的完全访问权限
每个CPU都可以平等访问整个物理内存,可以使用LOAD和STORE指令读写单个单词,数据速度:10-50nsec
多处理机的同步问题:
如果无法锁定总线,TSL指令可能会失败;为了阻止这种情况的发生,TSL指令必须首先锁住总线,阻止其他的CPU访问它,然后进行存储器的读写访问,再解锁总线
多处理机的调度问题
Timesharing(分时)
为就绪进程准备一个系统级的大数据结构Space sharing(空间共享)
在多个CPU上同时调度多个线程称为空间共享- 群调度
作为一个单元(一个团伙)安排的相关线程组,团伙的所有成员在不同的分时CPU上同时运行,所有帮派成员一起开始和结束时间片
UMA
Uniform Memory Access,统一内存访问
- 每个存储器字的读出速度是一样快的
- 具有总线架构的UMA多处理器
- 使用交叉开关的UMA多处理器(交叉开关)
- 交叉开关最好的一个特性是,非阻塞网络(nonblocking network)
- 最差的一个特性是,交叉点的数量以$n^2$方式增长
- 使用多级交换网络的UMA多处理器(多级交换网络)
- Omega Switching Network
NUMA
Nonuniform Memory Access,非统一内存访问
所有CPU都可以看到单个地址空间,通过命令LOAD和STORE访问远程内存
访问远程内存比本地内存慢
NC-NUMA:不隐藏远程内存的访问时间
基于目录的多处理器(基于目录的多处理):维护一个数据库,告诉每个缓存行的位置以及它的状态是什么
CC-NUMA(高速缓存一致NUMA):存在连贯的缓存
Multicore Chips(多核芯片)
将两个或更多完整的CPU(通常称为内核)放在同一芯片上(技术上,在同一个芯片上)。
多核芯片有时被称为CMP(芯片级多处理器)
片上系统(片上系统)
这些芯片具有一个或多个主CPU,但也有专用内核,如视频和音频解码器,网络接口等,从而在芯片上实现完整的计算机系统
- 为每个CPU提供私有存储器及操作系统的各自私有副本
- 允许所有的CPU共享操作系统代码,只需提供数据的私有副本
- 没有进程共享、没有页面共享、高速缓存不一致
Master-Slave multiprocessors(主从多处理机)
操作系统的一个副本及其表都在CPU 1上
所有的系统调用都重定向到CPU 1 上
问题:当有很多CPU时,CPU1会变成瓶颈
Symmetric Multiprocessors(SMP,对称多处理机)
在存储器中有操作系统的一个副本,但是任何CPU都可以运行它
在操作系统中使用互斥信号量(锁),使整个系统成为一个大临界区
多计算机
Message-passing multicomputer(消息传递多计算机,简称多计算机)【每个都有自己的私有内存】
多计算机上不同CPU上的进程通过相互发送消息进行通信
send(dest,&mptr),receive(addr,&mptr)
阻止(同步)呼叫与非阻塞(异步)呼叫
Remote Procedure Call(RPC) (远程过程调用):allowing programs to call procedures located on other
- 紧耦合的CPU不共享内存
- 通过某种高速互连连接
- 每个内存对于单个CPU是本地的,只能由该CPU访问
- 数据速度:10-50μsec
- 集群计算机
- COWS(工作站集群)
- 互连技术
Switching schema(交换机制)
- store-and-forward packet switching(存储转发包交换)
由源节点的网络接口卡注入第一个交换机的包组成
当整个包达到时,它被复制到这条路径上的下一个交换机 - circuit switching(电路交换)
包括由第一个交换机建立的、通过所有交换机而到达目标交换机的一条路径
一旦该路径建立起来,位流就从源到目标通过整个路径不停留地输送 - wormhole routing(虫孔路由)
把每个包拆成子包,并允许第一个子包在整个路径还没有完全建立之前就开始流动
广域分布式系统
Wide area distributed system(广域分布式系统)【通过Internet连接起来的系统】
通过广域网连接完整的计算机系统
这些计算机中的每一台都有自己的内存,系统通过消息传递进行通信
数据速度:10-50毫秒
一些网络协议:IP/TCP
一些服务:无连接的和面向连接的
虚拟机技术
虚拟机技术,通常称为虚拟化(virtualisation化)。
该技术允许单台计算机托管多个虚拟机,每个虚拟机可能运行不同的操作系统;这种方法的优点是一个虚拟机中的故障不会自动降低任何其他虚拟机
Type 1 Hypervisor1型管理程序,本省就是一个操作系统,唯一一个运行在内核态的程序,工作是支持真实硬件的多个副本,也称为虚拟机,与普通操作系统支持的进程类似
虚拟机运行一个客户机操作系统,认为它处于内核模式(它真的处于用户模式)这称为虚拟内核模式
Type 2 Hypervisors2型管理程序
示例:VMware,VMware在主机操作系统之上作为普通用户程序运行,当它第一次启动时,它会将操作系统安装到其虚拟磁盘上
准虚拟化(半虚拟化)
要修改客户机操作系统的源代码,使其完全不执行敏感指令,而是进行管理程序调用
管理程序必须定义一个接口,该接口由客户操作系统可以使用的一组过程调用组成(API)
故意删除(某些)敏感指令的客户操作系统被称为半虚拟化
半虚拟化的问题
如果通过调用虚拟机管理程序替换敏感指令,操作系统如何在本机硬件上运行?
如果市场上有多个虚拟机管理程序怎么办?
解
内核被修改为在需要执行敏感操作时调用特殊过程
这些称为VMI(虚拟机接口)的过程组成了一个与硬件和管理程序接口的低级层
中间件
- Document-Based Middleware(基于文档的中间件)
- File System-Based Middleware(基于文件系统的中间件)
- Naming Transparency(命名透明性)
- location transparency(位置透明性) - 路径名称不提示文件的位置
- location independent(位置独立性) - 可以移动文件而不更改其名称
- 文件和目录命名的三种方法
- 机器+路径命名
- 将远程文件系统挂载到本地文件层次结构上
- 在所有计算机上看起来相同的单个名称空间
- Shared Object-Based Middleware(基于共享对象的中间件)
- CORBA(Common Object Request Broker Architecture)
- Coordination-Based Middleware(基于协作的中间件)
- Linda
- Publish/Subscribe(发布/订阅)
- Jini
安全
安全问题
- threats(威胁)
- Data confidentiality(数据机密性) - 秘密数据保密【数据暴露】
- Data integrity(数据完整性) - 未经所有者许可,未经授权的用户不得修改任何数据【数据篡改】
- 系统可用性(系统可用性) - 没有人可以打扰系统使其无法使用【拒绝服务】
- 隐私/排外性:保护个人不被滥用有关他们的信息【系统被病毒控制】
- intruders(入侵者)
- 被动入侵者- 阅读他们无权阅读的文件
- 主动入侵者- 对数据进行未经授权的更改
- 常见类别
- 非专业用户的随意浏览
- 内部人员的窥视
- 为获取利益而尝试
- 商业或军事间谍
- 病毒:一段能够自我复制并通常会产生危害的程序代码
- accidental data loss(数据的意外遗失)
- 常见原因:天灾:火灾,洪水,战争;硬件或软件错误:CPU故障(故障),坏磁盘,程序错误;人为错误:数据输入,错误的磁带安装
- Protection Domains(保护域)
- A domain is a set of (object, right) pairs. Each pair specifies an object and some subset of the operations that can be performed一对对象权限的组合,每对组合指定一个对象和一些可在上面运行的操作子集。权限是指对某个操作的执行许可
- A right means permission to perform one of the operations
- An important question is how the system track of which object belongs which domain:Protection matrix
- Domain switching itself can be easily included in the matrix model by realizing that a domain is itself an object, with the operation enter
- Access Control Lists(访问控制列表)【每个对象的】
- 每个对象都有一个(有序)列表,其中包含可以访问该对象的所有域。 此列表称为访问控制列表(ACL)
- 许多系统支持一组用户的概念。 组具有名称,可以包含在ACL中。以这种方式使用组有效地引入了角色的概念
- Capabilities(权能字)【每个进程的】
- 将每个进程与可访问的对象列表相关联,并指示每个进程允许哪些操作。此列表称为功能列表(C-list),其上的各个项称为功能
- 必须保护能力列表免受用户篡改(用户干预)
- 标记架构(例如IBM AS / 400)
- 将C列表保留在操作系统内(例如Hydra)
- 将C列表保留在用户空间中,但以加密方式管理功能
- 能力的通用权利
- 复制功能:为同一对象创建新功能
- 复制对象:使用新功能创建复制对象
- 删除功能:从C列表中删除条目; 对象不受影响
- 销毁对象:永久删除对象和功能
- Trusted Systems(可信任系统)
验证
当用户登录到计算机时,操作系统通常希望确定用户是谁,这是一个称为用户验证的过程。
基本原则认证必须识别:
- 用户知道什么
- 用户拥有什么
- 用户是什么
试图闯入不属于计算机系统的人是骇客
有不同的用户身份验证架构:
- 使用密码/口令验证
- 最广泛使用的身份验证形式是要求用户键入登录名和密码,最简单的实现只保留(登录名,密码)对的中央列表
- UNIX Password Security
- 将每一个口令同一个叫做盐(Salt)的n位随机数相关联
- 无论何时口令改变,这个随机数就改变
- 将口令和随机数连接起来,一同加密,加密后的结果存放进口令文件
- 使用实际物体验证
- Magnetic cards(磁卡)
- magnetic stripe cards(磁条卡)
- chip cards(芯片卡): stored value cards, smart cards
- Magnetic cards(磁卡)
- 使用生物特征验证
- 一个典型的生物识别系统由注册部分和识别部分两部分构成
- 使用手指长短进行识别
- 视网膜组织分析
- 签名分析
- 声音测定
- 一个典型的生物识别系统由注册部分和识别部分两部分构成
内部攻击
- Logic Bombs(逻辑炸弹)嵌在产品的操作系统中的代码,特定情况下爆炸
- Trap Doors(后门)
- 陷阱门/后门是由程序员插入系统的代码创建的,以绕过一些正常检查(代码审查)
- Login Spoofing(登录欺骗)
- 通过在多个终端上进行假冒登录界面,入侵者可收集到多个口令,通常当没有人登录到UNIX终端或局域网上的工作站时,会显示登录屏幕
利用代码漏洞
- Buffer Overflow Attacks缓冲区溢出攻击
- 一个常见的攻击源是由于几乎所有操作系统和系统程序都是用C语言编写的,而C编译器没有数组边界检查
- Format String Attacks格式化字符串攻击
- Return to libc Attacks返回libc攻击
- Integer Overflow Attacks整数溢出攻击
- Code Injection Attacks代码注入攻击
- 可能导致代码注入攻击的代码,比如请输入后,接受用户的输入,并且作为cmd
- Privilege Escalation Attacks权限提升攻击
恶意软件
可以用于敲诈勒索的形式
示例:加密受害者磁盘上的文件,然后显示消息…
病毒
Companion virus(共事者病毒)
- 实际上不会影响程序,但在程序运行时会运行
Executable program virus可执行程序病毒
- 覆盖病毒overwriting viruses
这些病毒中最简单的只是用自己覆盖可执行程序 - 寄生病毒Parasitic virus
将自己附加到程序并执行其脏工作,但允许程序正常运行
- 覆盖病毒overwriting viruses
- Memory-resident virus内存驻留病毒
- 总是驻留在内存中
把自身地址放置在Trap或者中断向量中,从而将Trap或中断向量指向病毒
- 总是驻留在内存中
- Boot sector virus引导扇区病毒
- 覆盖主引导记录(MBR)或主引导扇区
把真正的引导记录扇区复制到磁盘的安全区域
使用磁盘内任意空闲的扇区,然后更改坏扇区列表,把隐藏引导记录的扇区标记为坏扇区
- 覆盖主引导记录(MBR)或主引导扇区
- Device driver virus设备驱动病毒
- Macro virus宏病毒
- Source code virus源代码病毒
间谍软件
粗略地说,间谍软件是在没有所有者知情的情况下秘密地加载到PC上的软件,并且在后台运行并在所有者的背后做事
特点:
- 受害者不能轻易找到
- 收集有关用户的数据
- 将收集的信息传达给远方的主人
- 试图在确定的删除它的尝试中生存
间谍软件采取的行动
- 更改浏览器的主页
- 修改浏览器的收藏(已添加书签)页面列表
- 将新工具栏添加到浏览器
- 更改用户的默认媒体播放器
- 更改用户的默认搜索引擎
- 将新图标添加到Windows桌面
- 将网页上的横幅广告替换为间谍软件选择的横幅广告
- 将广告放入标准Windows对话框中
- 生成连续且不可阻挡的弹出式广告流
隐蔽软件
rootkit(隐蔽软件)是一个程序或一组程序和文件,试图隐藏它的存在,即使面对受感染机器的所有者确定的定位和删除它的努力。
通常,rootkit包含一些被隐藏的恶意软件
一个典型rootkit包括:
- 以太网嗅探器程序,用于获得网络上传输的用户名和密码等信息
- 特洛伊木马程序,例如:inetd或者login,为攻击者提供后门
- 隐藏攻击者的目录和进程的程序,例如:ps、netstat、rshd和ls等
- 可能还包括一些日志清理工具,例如:zap、zap2或者z2,攻击者使用这些清理工具删除wtmp、utmp和lastlog等日志文件中有关自己行踪的条目
- 一些复杂的rootkit还可以向攻击者提供telnet、shell和finger等服务
rootkit的类型
- 固件rootkit
- Hypervisor(管理程序)rootkit
- 内核rootkit
- 库rootkit
- 应用程序rootkit
防御
纵深防御:你应该有多层安全性,这样如果其中一个被破坏,还有其他一些需要克服
防火墙
- Virus Scanner(病毒扫描程序)
have the virus infect a program that does nothing, often called goat file(诱饵文件), to get the copy of the virus in its purest form
make an exact listing of the virus’ code and enter it into the database of known viruses - 防病毒程序检测文件感染的另一种方法是在磁盘上记录并存储所有文件的长度
- Integrity checkers(完整性检查程序)
首先扫描硬盘上的病毒,一旦确信硬盘是干净的,它就开始计算每个可执行文件的校验和,并把一个目录里所有相关文件的校验和的列表写入该目录的checksum文件中 - Behavioral checkers(行为检查程序)
反病毒程序在系统运行时驻留在内存,并自己捕捉所有的系统调用 - Virus avoidance(病毒避免)
- good OS(提供高度安全保障的操作系统)
- install only shrink-wrapped software(仅安装从可靠的供应商处购买的正版软件)
use antivirus software - do not click on attachments to email
- frequent backups
- Recovery from virus attack
- halt computer, reboot from safe disk, run antivirus
- 代码签名
- 仅接受来自可信来源的Applet
- 用户通过数字签名来验证Applet来自可信的供应商
- 代码签名是基于公钥加密体制的
JAVA的安全体制:
- 一种类型安全的语言
- 编译器拒绝尝试滥用变量
- Java程序被编译为称为JVM(Java虚拟机)字节代码的中间二进制代码
- 在Java模型中,通过Internet发送以进行远程执行的applet是JVM程序
- applet通过JVM字节验证程序运行,该验证程序检查applet是否遵守某些规则
- 检测包括
- 试图伪造(伪造)指针
- 违反私人集体成员的访问限制
- 按类型滥用变量
- 堆栈上溢/下溢的生成
- 非法将变量转换为另一种类型
安全模型
Bell-LaPadula(军方)【保守机密,但不能保证数据的完整性】
- 在密级k上面运行的进程只能读取同一密级或更低密级的对象
- 在密级k上面运行的进程只能写取同一密级或更高密级的对象
- 进程可以读写对象,但不能直接相互通信
Biba(民用)【刚好相反】
- 在密级k上面运行的进程只能写取同一密级或更低密级的对象
- 在密级k上面运行的进程只能读取同一密级或更高密级的对象
转载请注明出处,谢谢。
愿 我是你的小太阳
